


This article is the Part 2 of the detailed description of my talk at HighLoad++ 2015. The first part can be found here:

In part 1, I described how the project began, and now I will tell you about the first released version of the product.
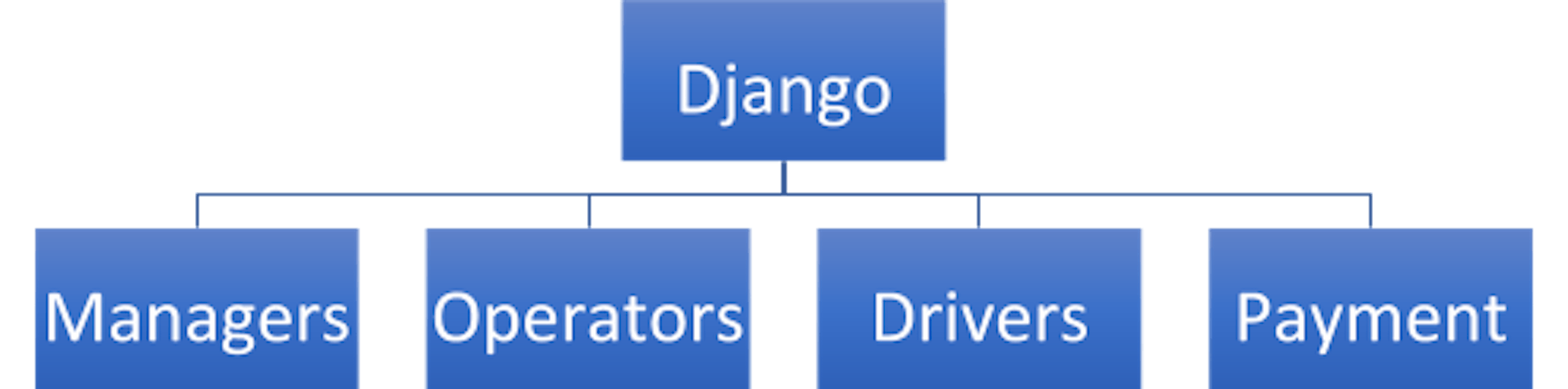
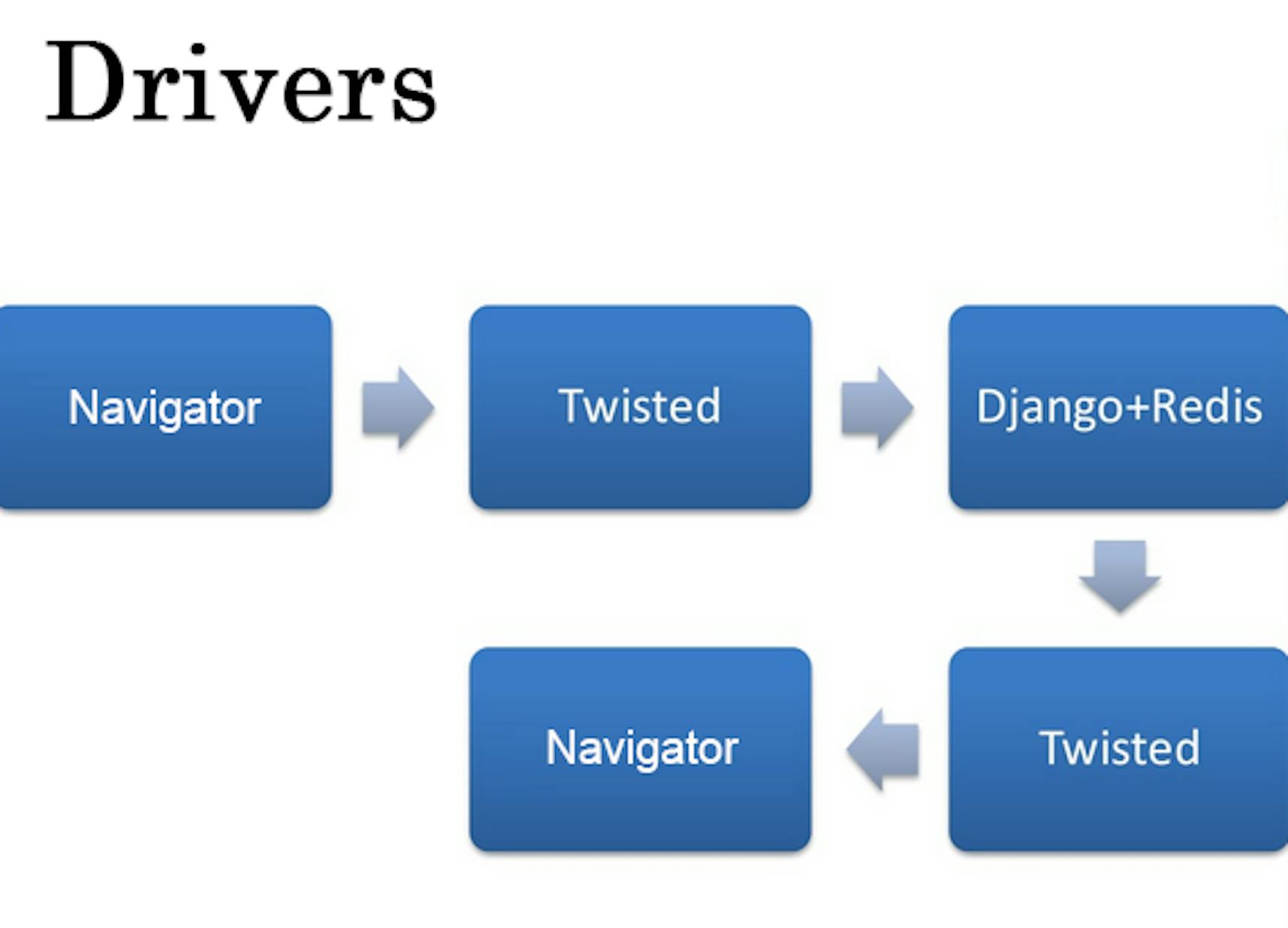
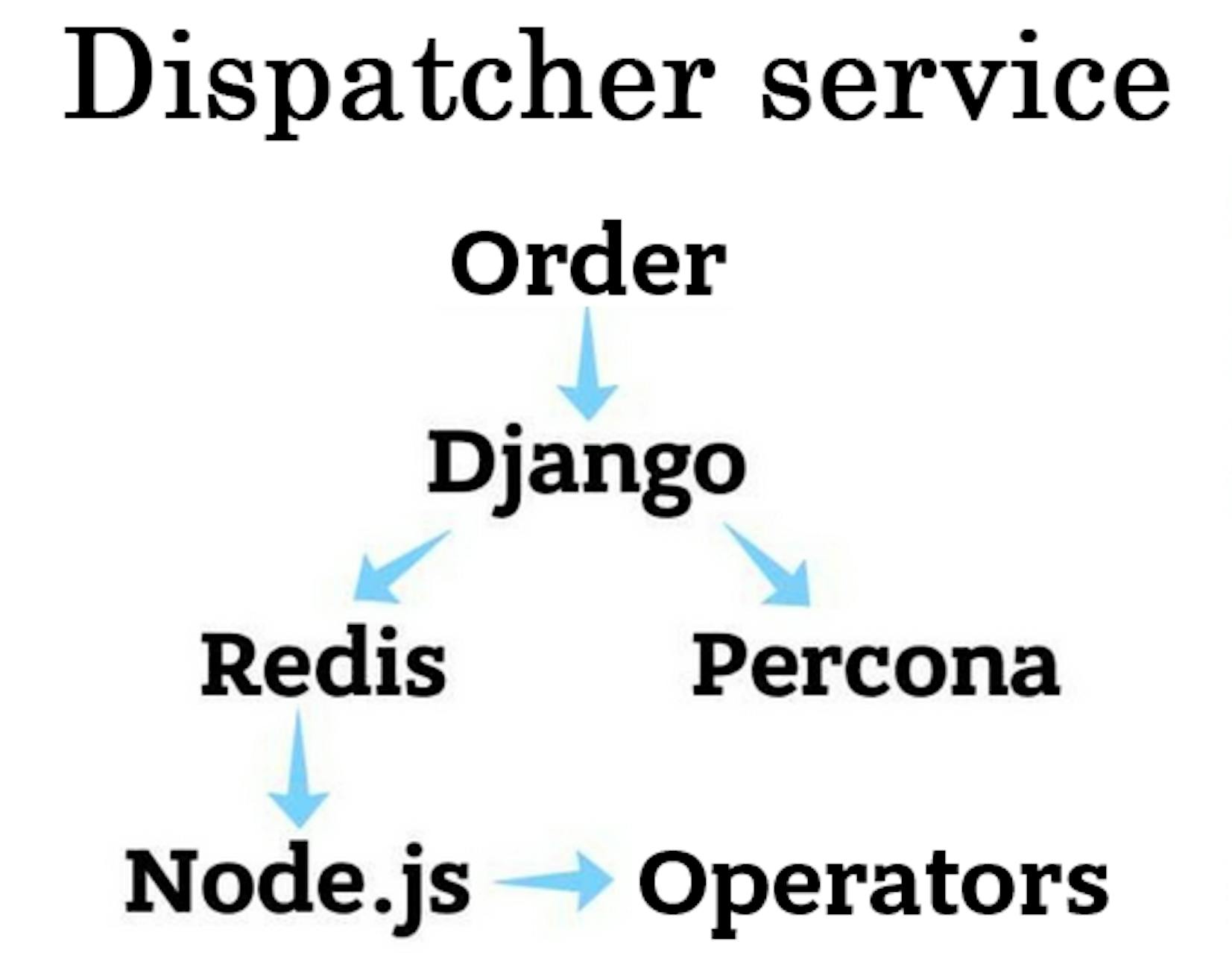
Everything was implemented in Django. Drivers used Chinese navigators that were connected via Twisted. If a driver was authorized, he connected to Redis. Otherwise, he connected to Django with get/post requests, then Django returned a response to Twisted.
Implementation
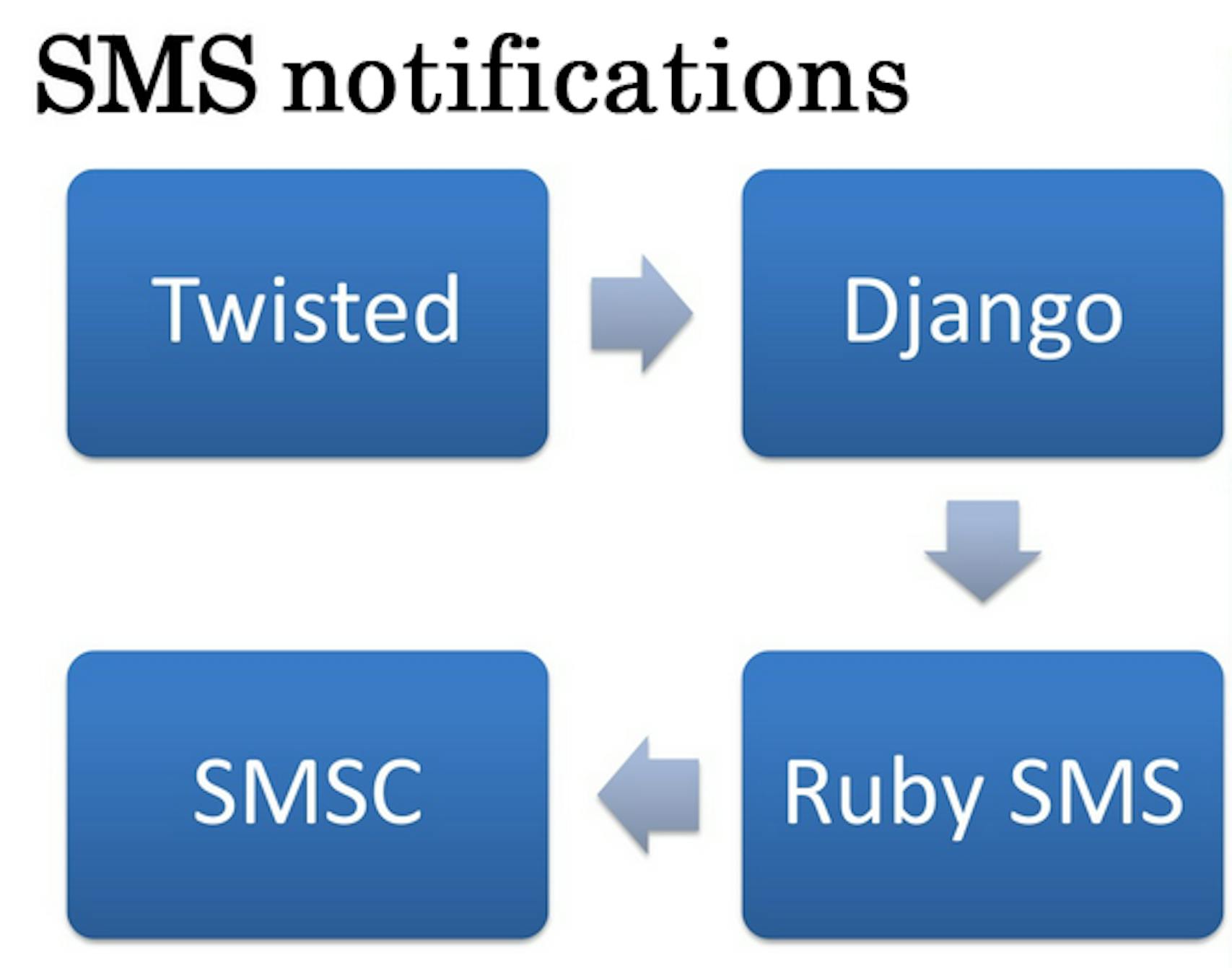
SMS notifications for clients were sent to drivers, i.e. our Twisted sent requests to Django on Ruby daemon, then it processed requests through SMS provider's center (SMSC).
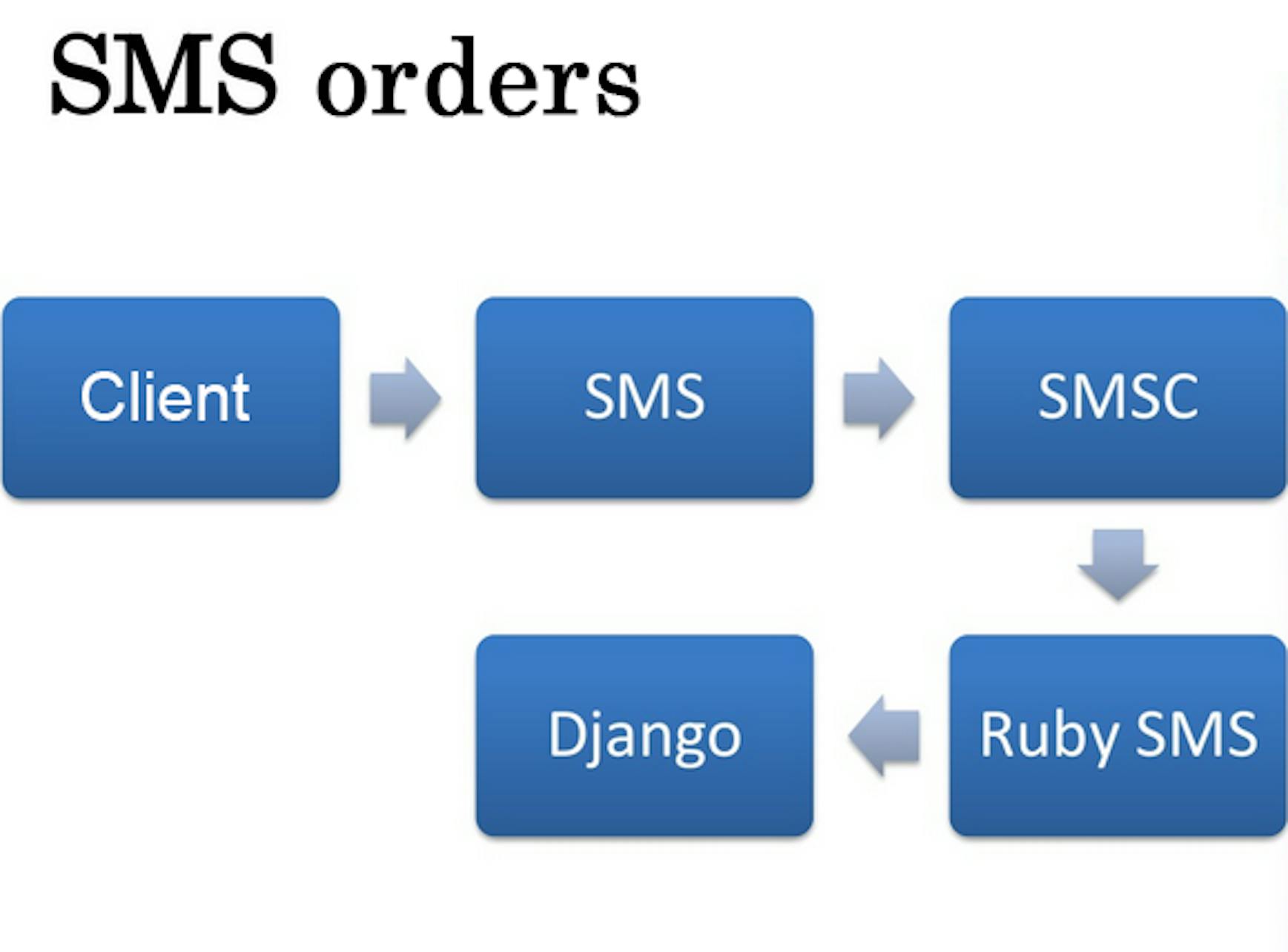
In the process of getting SMS orders, the client sent a message that was received by the SMS provider's center. We picked up the message by Ruby daemon and made a Post request to Django.
In fact, operators have 2 work processes: acceptance of orders and calls from the telephony. All orders come with Post requests to Django, which saves Percona order and then sends it to a specific Redis channel that is listening to Node.js. Information is sent to broadcast operators’ channel.
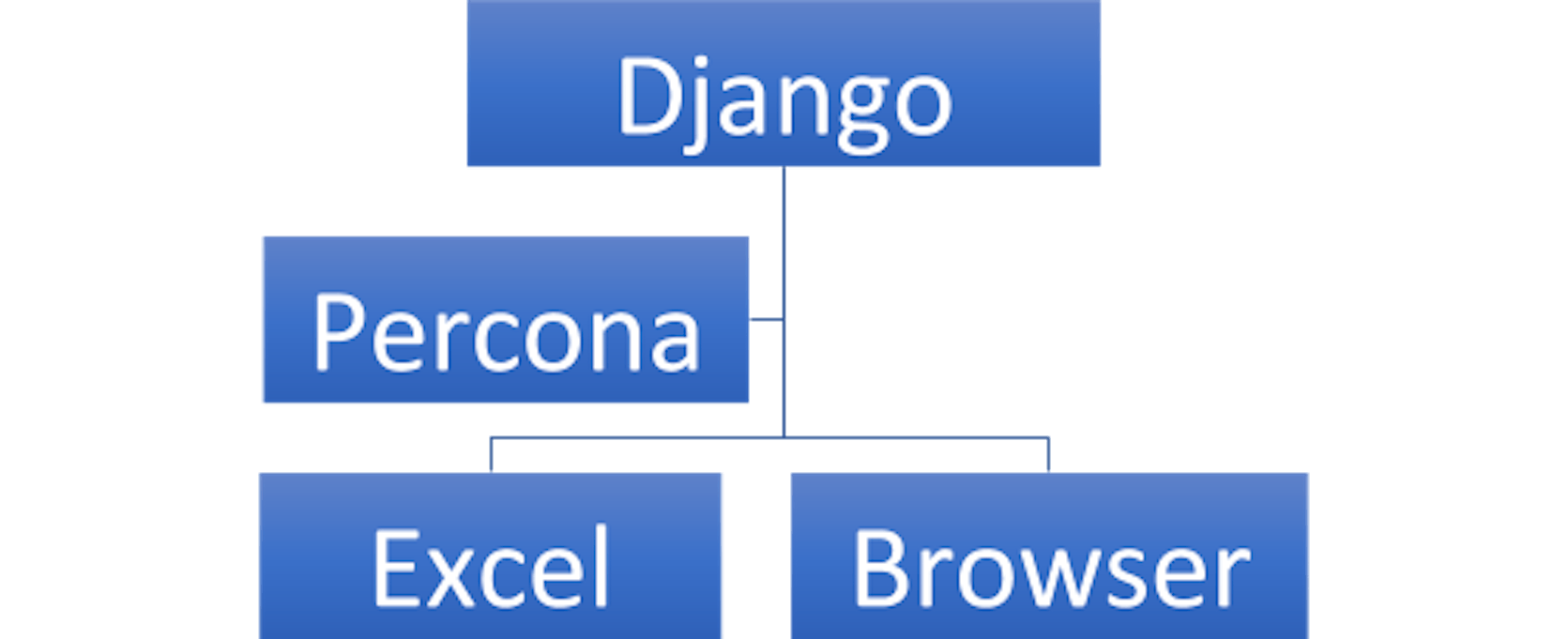
The simplest part of our system atomizes the manager's work. Django collects data from Percona and sends it to Excel or a browser. At the early stage, we manually added the fault tolerance for Percona and made Master-Slave Replication. We placed the virtual IP on the master. In case of primary server failure, the load would be transferred to secondary.
Managers
The work was done. Then it was time to check the efficiency in real conditions. We launched the courier service on new software and then checked. The main advantage of the system was the fact it worked well immediately from the first time. At this stage, we stabilized calls through WebRTC.
We were changing the software, and it was painful for everyone:
- Transfer 2000 drivers;
- Transfer all short SMS numbers;
- Transfer IP telephony;
- Transfer 20 operators;
Our small technical team launched the new software in 7 days.
We implemented one Nginx entry in operator paned and proxied Django and Node.js. We set up a separate virtual machine for drivers that transferred traffic from Twisted to another virtual machine. This solution was crucial for further scaling.
We used Sentry to collect exceptions from the backend and so got the first eyes at production. Nagios and Collectd collected metrics and monitored the project.
On the 1st day, we transferred about 100 drivers and 4 operators. Operators transferred orders to new software from the old one.
On the 2nd day, we already moved 250 drivers and 4 more operators and started the transfer of SMS numbers as well.
On the 3rd day, most operators were working with our software, all SMS numbers were transferred.
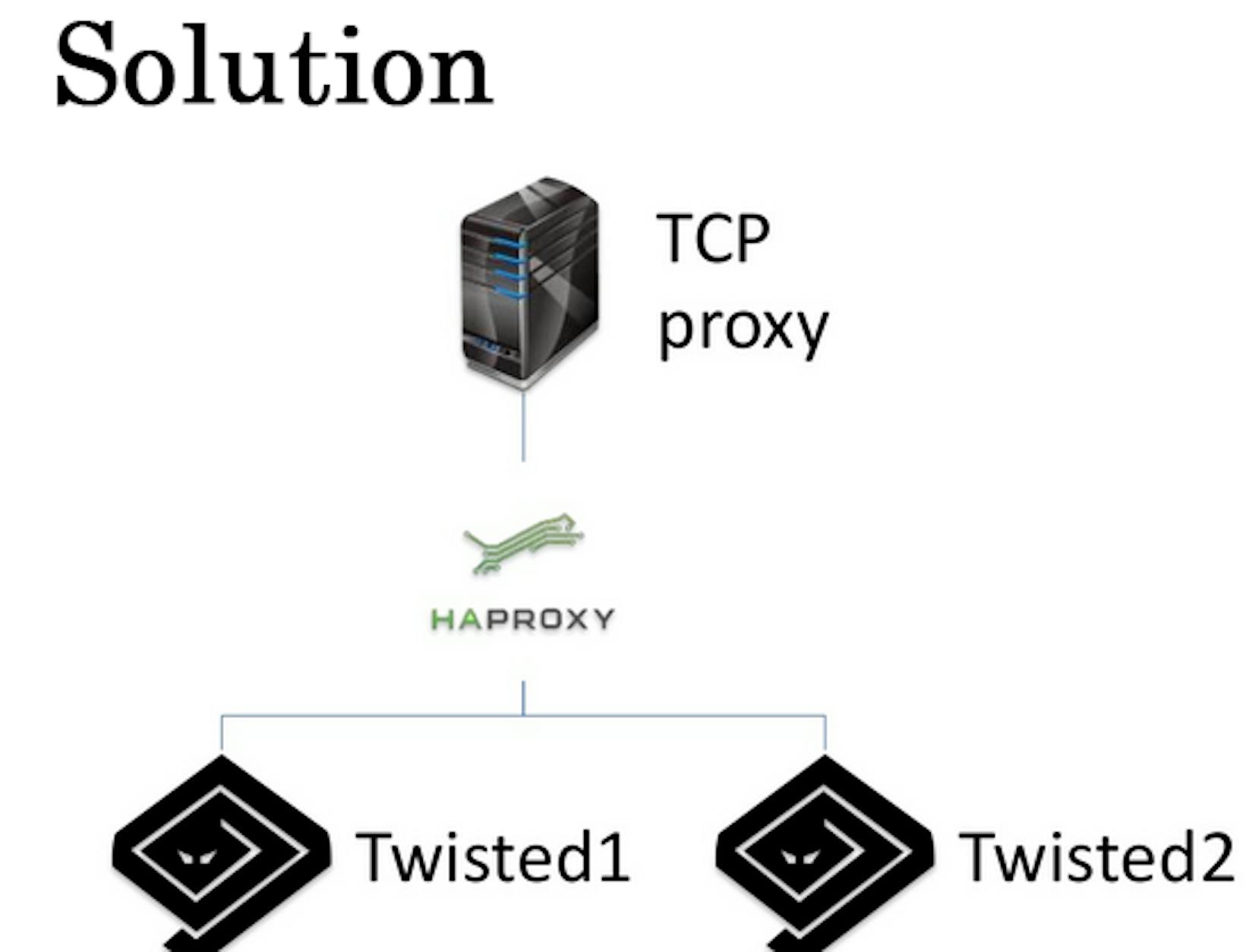
On the 4th day, we were busy with transferring IP telephony and faced with first performance problems. Drivers could not always take an order or get the order list update. What was the problem? Computer output the Socket Timeout on the navigators since we were using synchronous Twisted. It did not have enough time to process all driver requests. To solve this problem, we balanced the workload between 2 Twisted instances based on HAProxy.
On the 5th day, all orders were processed via our software. Drivers desired to upgrade to the new software, and the transport department was overwhelmed with work. There were about 150 drivers in the office simultaneously. During peak load, 3 operators were transferring 2 drivers every minute. We experienced problems with operator efficiency. Some operators could not get order updates. In addition, sometimes drivers marked orders as "fake" but some of the operators did not receive this information. Since Node.js was responsible for real-time updates, we concluded it could not manage the process and decided to scale it.
On the 6th day, we moved the whole service to new software. The problems started occurring for both drivers and operators. The operators' problem was the slow processing of the orders. Operators had an order card that should work the following way:
- Operator types an address;
- Clicks on Submit button;
- The data is saved, and the card disappears.
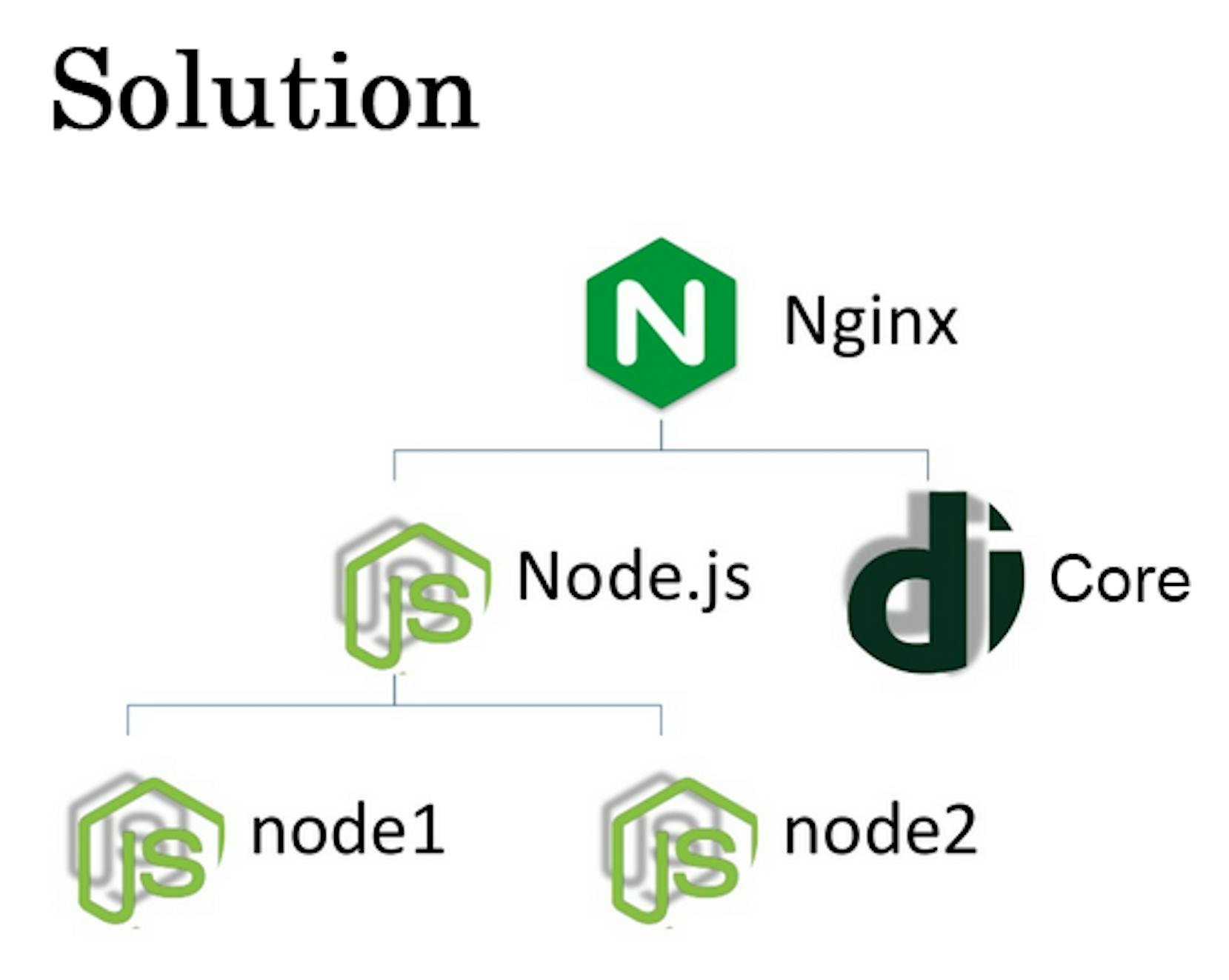
But on the 6th-day cards stopped disappearing. Also, the 4th-day problem for drivers reappeared. We caught Socket Timeout that led to the problems with Django. We decided that it was time to scale everything and chose the straight way of solving the problem — to do the balancing.
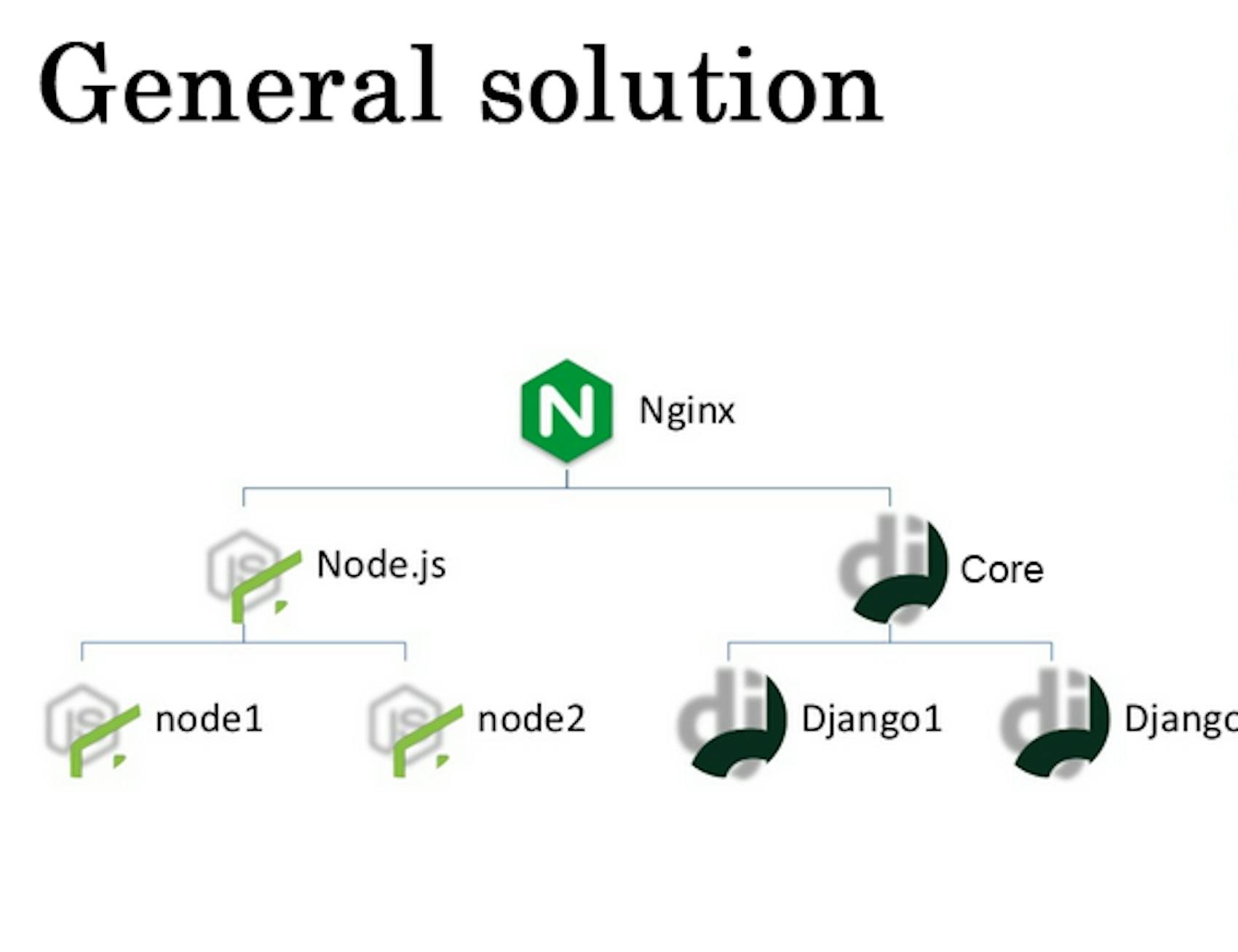
One Twisted is connected to one Django, the other with another Django. Node.js daemon works with one Django and the second daemon with the other one. Node.js daemon consumes about 250 megabits of the network. It is due to the usage of both Node.js and Socket.io.
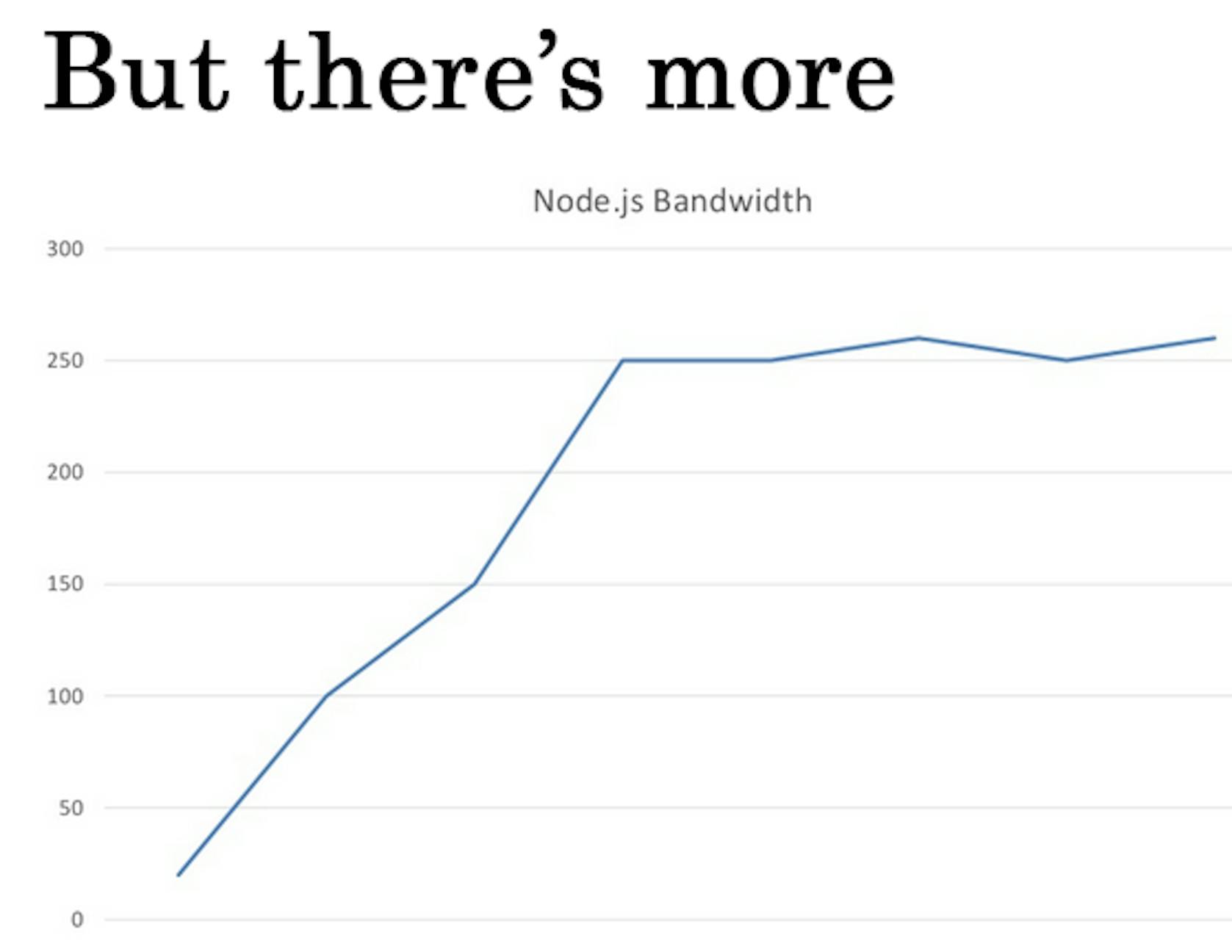
This graph represents the Socket.IO 0.9.8 version. Those, who used it, know that listener there is located in Redis module. Redis work listeners and connections. This led to the situation shown on the graph above. The Socket.IO package developer was busy with the development of his own library and did not want to fix the error. Thanks to the people who solved this problem. They fixed the leak of Redis memory as well. We have been working with Redis for a long time. Then, the 1.3 version was introduced, and we upgraded our software.
On the 7th day, everything became more or less stabilized.
So what was the result of the transfer to the new software?
During the period of transfer, we lost about 8% of orders. But our software let to reduce the time for the car to arrive was from 8 to 5 minutes. We did not use Twisted fully and asynchronously by mistake. And if I were to make this decision today, I would use Erlang or Python daemon. Within this week, I also understood that our load tests had nothing to do with real life.
In part 3 I will describe what other issues we've faced and what we came up with for our software to become stable and competitive among other automated taxi management solutions.


Latest articles here





