


Analyze with AI
Get AI-powered insights from this Mad Devs article:
This article is the Part 3 of detailed description of my talk at HighLoad++ 2015. For all interested please refer to Part 1 and Part 2.
When everything was stabilized after the transition, we started to grow. Cars arrived faster, everybody was happy. Business representatives came to us and said that they wanted even more orders. To get more orders, it was necessary to expand the auditory. Therefore, we decided to create a mobile application.
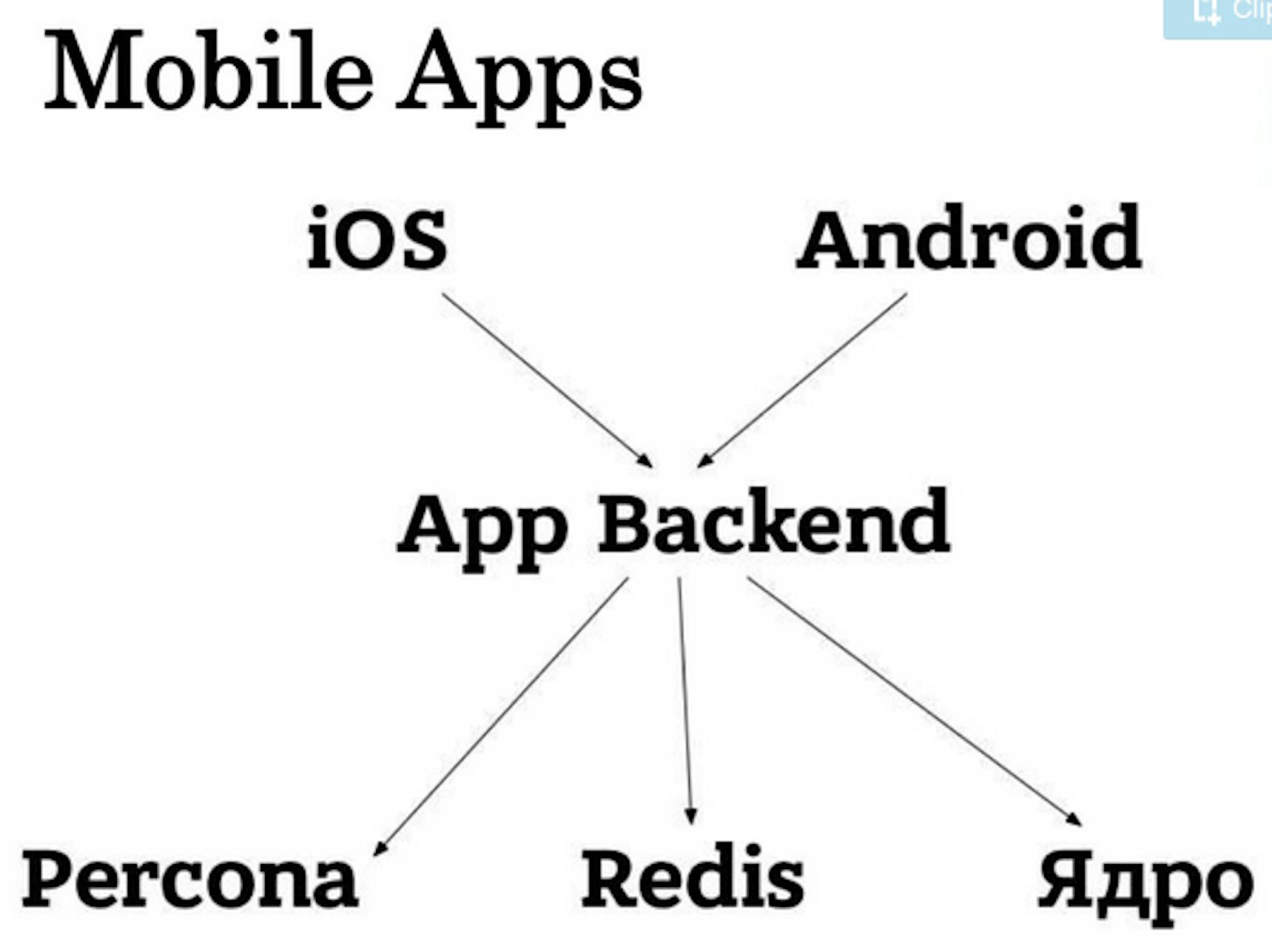
Creating the mobile app
We had a Django backend that created an order upon request to the core. The further order statuses were saved into Redis to reduce the time for unnecessary HTTP requests between two backends. Percona saved the client data: authorization status and phone number. Our Nginx entry was as follows: Django proxied on the core, on mobile applications, and Node.js. We were happy: the number of orders was increasing, people were installing the app more often, and drivers were fighting for the opportunity to work for us.
Then the dark day came and both Twisted instances became unable to manage the process. Drastic changes were necessary, i.e. we had to use Twisted with all its asynchronous, wherein we did not have equal balancing. We decided to secretly implement HAProxy. We had one Nginx entry, one server had more workload than the other. The proximate workload on physical servers looked the following way:
The entry to drivers' system is implemented on HAProxy. It balances between 2 Twisted that refers to one of Django instances. The similar entry is on Nginx. We decided that it would be more logical to set up the second Nginx based on the 2nd physical box, and then balance the workload between two Nginx through Round Robin. We did HA on VRRP protocol with the help of Linux 'keepalived' daemon. This daemon produces good fault-tolerance.
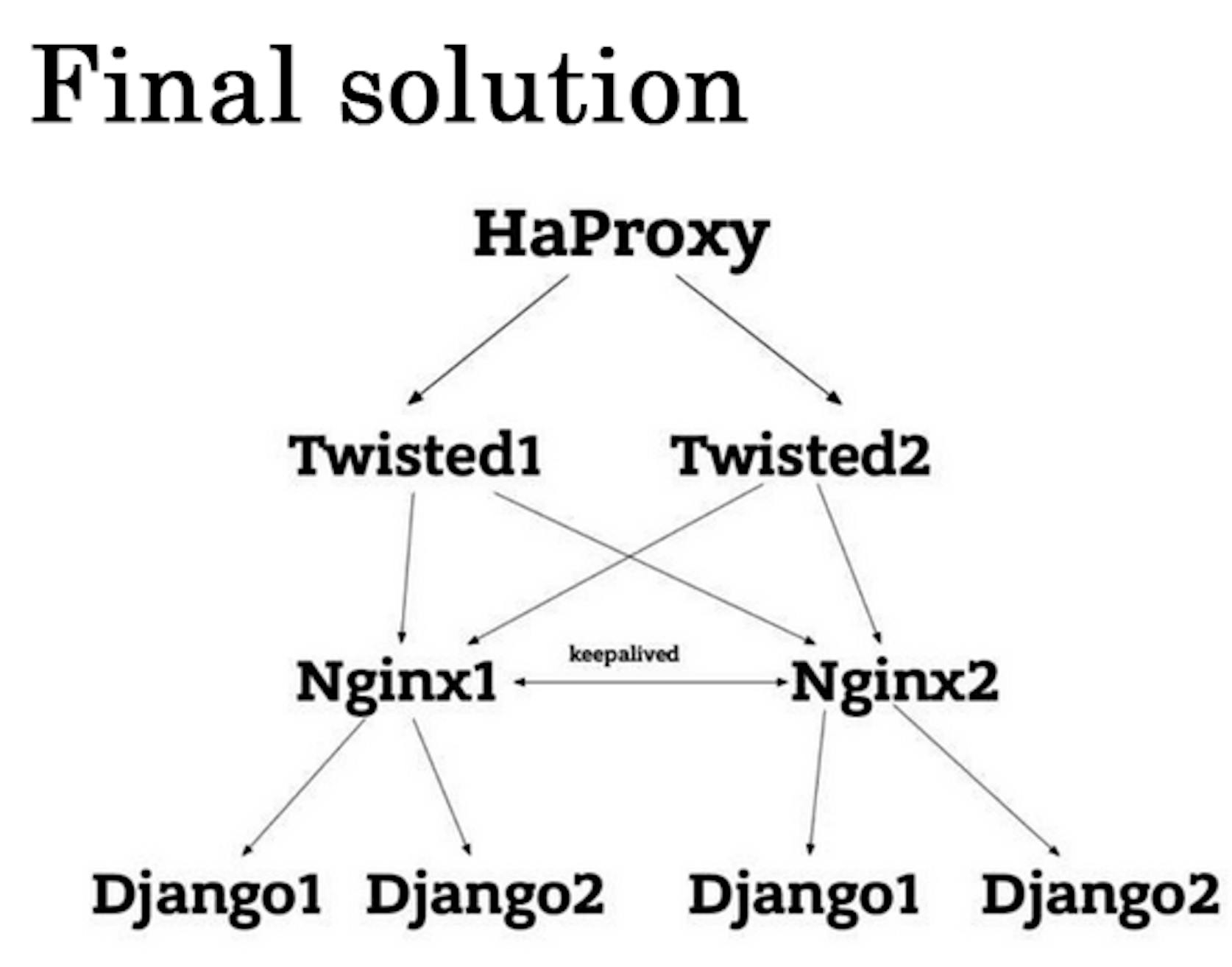
This scheme shoes that in case if we have one Nginx fallen, the second one moves into virtual IP and becomes the 1st Nginx, and nobody pays attention to this change.
We divided the workload. Reports and order processes were edited separately. We set up 4 Django instances. Two of them were processing the workload for order acceptance and for work with Percona master, two other ones introduced reports and read information from Slave.
We rewrote Twisted, designed asynchronous work with everything it was possible to made, added the work with random upstream services.
We concluded that we should have the fault-tolerant point on HAProxy that balances between two Twisted frameworks with the help of "keepalive" daemon. Those in turn are balanced by two Nginx, that balance between two Django instances. Nginx and HAProxy are fault-tolerant through "keepalive". Thanks to this scheme we can lose absolutely any element of the chain without losing the working capacity of the whole system. To make everything work fast and correct, we have about 40–50% of free space on our servers.
But not everything was so easy. We got two new problems:
- SMS daemons were not scaled, and
- Redis was not supported.
SMS daemons worked like this: Django connects to web-socket by TCP and sends messages through SMS center. Disadvantages were the large number of TCP connections, and lot of resources wasted because of them. There was no scaling. We solved it by referring everything to Redis. We did it on publish/subscribe mechanism. At the end Django sent «publish» to appropriate channel, listened to SMS daemons, and if the information was received, Redis sent a message.
Redis failover
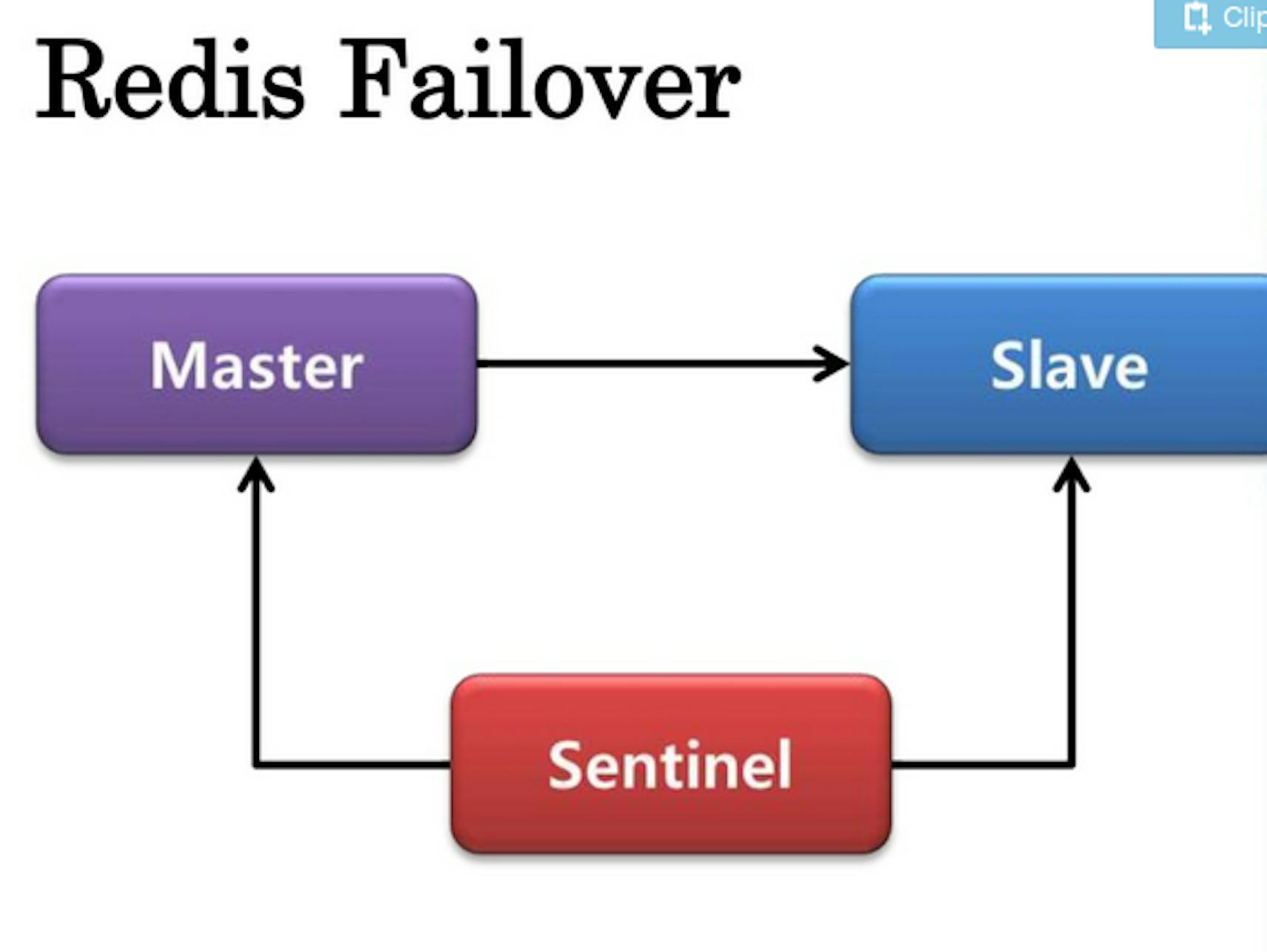
We added the fault-tolerance for Redis with the help of Sentinel. We have Sentinel that watches all nodes on Redis. There is a master from which data is asynchronously copied to slave and if master does not work, one of the slaves becomes a master. The period of failure does not exceed 2 seconds.
We were happy that Percona introduced the new 5.6 version. We installed the new version immediately after testing. We had Master-Master with GTID-replication. For master address, there were virtual IP and one more virtual IP was for slave; master — for write, and slave — for read. We also set the fault-tolerance for both master and slave, but the switching was not automated since it was not worth to do due to the difficult implementation. As the result we got highly scaled fault-tolerant product with sip and without flash.
Now I will tell how we stabilize the sip work through WebRTC. At first, we bought 1 SIP account for tests. We took SipML as the background software at frontend. We put WebRTC2sip as a media proxy between SipML and provider. The calls worked satisfactory, but with a few problems. For example, we could not connect phone numbers and balance calls. For every number, it was necessary to set up one more WebRTC.
We decided to upgrade to Asterisk 11.5 and use it as АТС to make it work with our GSM gateways and providers, and leave SipML on frontend. We got all benefits of high-grade ATC, such as balancing the workload and connecting new numbers.\
SipML and WebRTC2sip
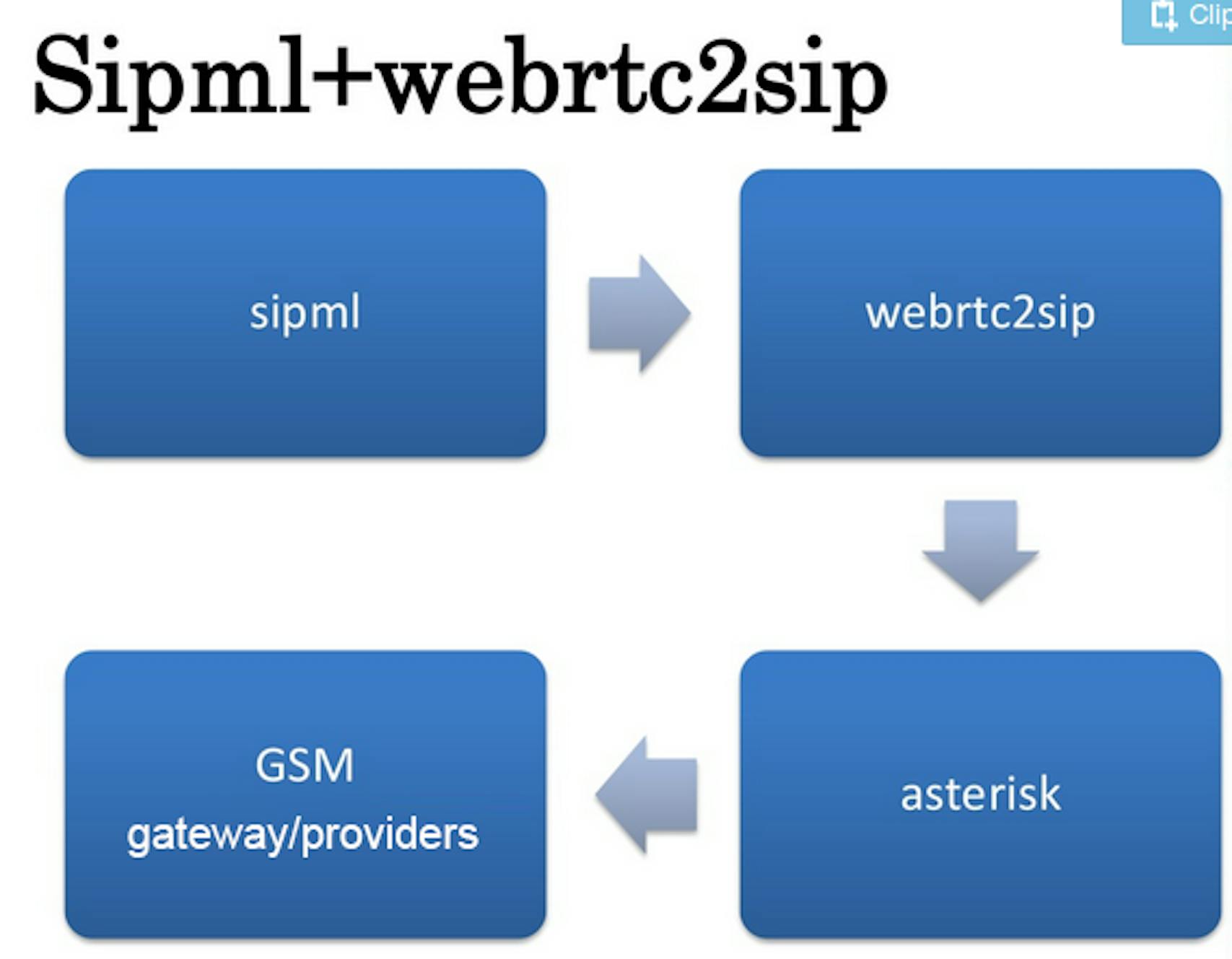
Asterisk problems were the following: incoming clients' calls were interrupted and outcoming calls had no tones or operators' service messages. Audio between two devices was bridged slowly, people could not hear each other well. The incoming call could turn off the Asterisk. We decided to update it. As the result, the call was no more interrupted, Asterisk worked consistently and stable, audio bridged well, but tones still did not appear. Instead one-sided audio appears—only client could hear operator or vice versa.
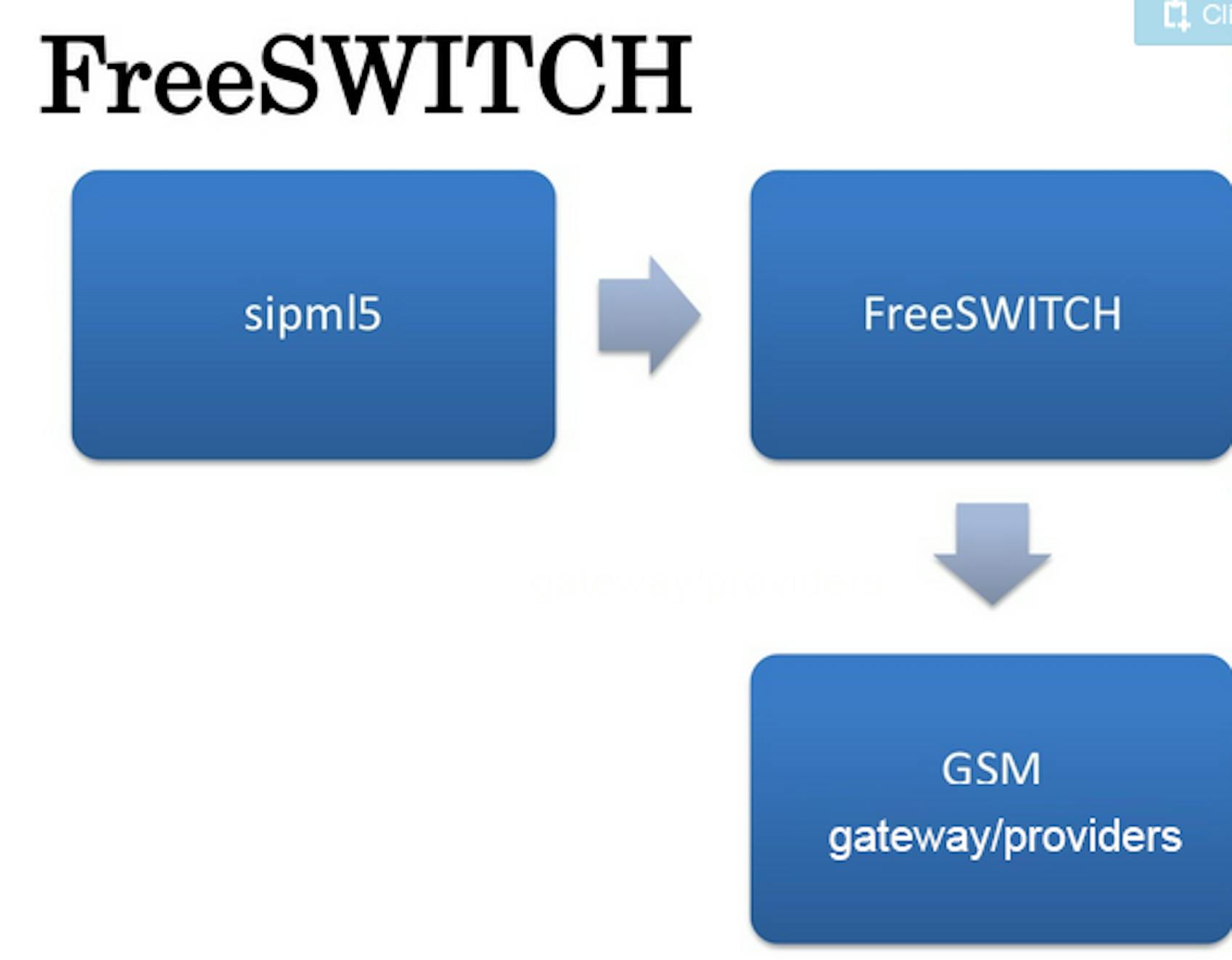
We decided to return WebRTC2sip into the scheme as a media proxy between SipML and Asterisk. Due to this solution we got the working telephony, but WebRTC2sip tool off randomly. We ran WebRNC2sip under debug, added break points and tried to fix it, but did not succeed. There was no documentation, and the quality of code was low.
Then we found out FreeSWITCH. Asterisk and WebRTC2sip we changed for FreeSWITCH. Everything worked except tones and service answers from cell operators. We decided that free FreeSWITCH will answer the call when a call is received. As the result, dispatching operator can hear both tones and messages. The new problem was that a call was interrupted after the second minute of the talk due to SipML message. Those who worked with the library, know that its updated version is about 1MB, and we didn't want to deal with this 1MB of code trying to fix it.
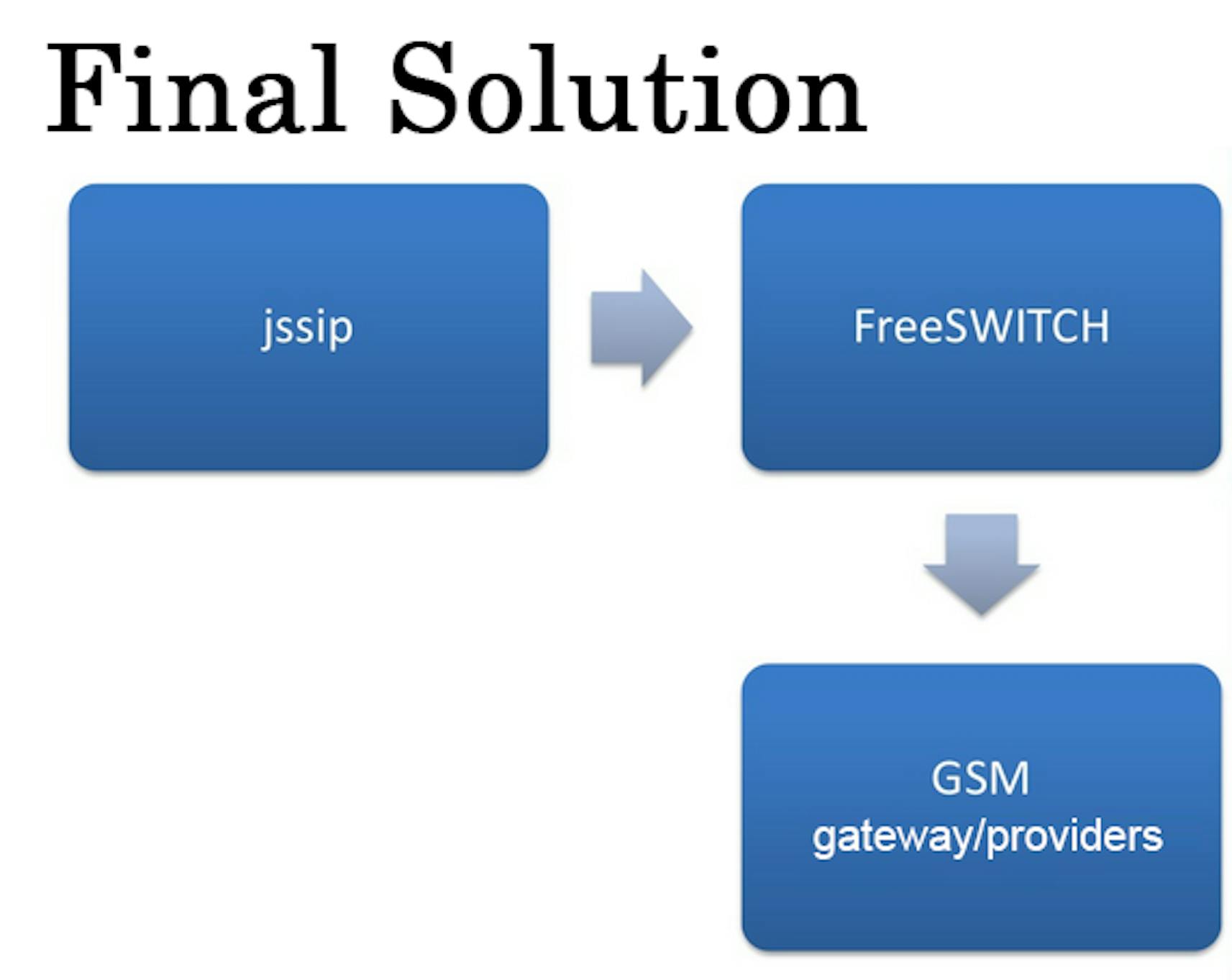
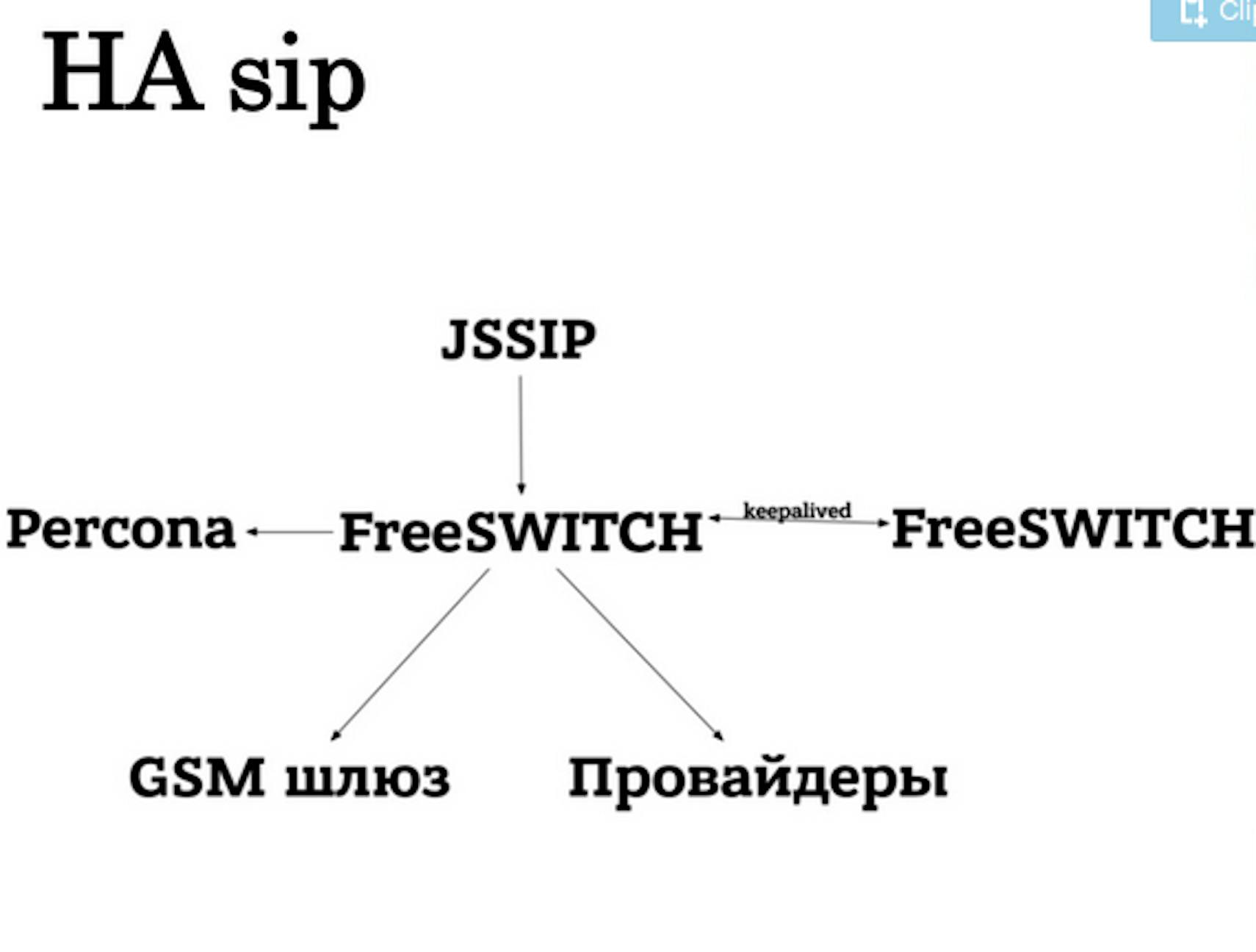
As the subsitute we found light JSSIP by the RFC authors for Sip work through WebRTC. We finally came up with the stable scheme. JSSIP worked as a software background, FreeSwitch worked with GSM gateways and providers.
To implement this strategy we used "keepalived", two FreeSwitch on different virtual machines. If master failed, its responsibilities were taken by the second FreeSwitch. Percona saved all the service conditions, connected users and FreeSwitch requirements. Thanks to FreeSwitch recovery mechanism, we had all the system worked.
This solution with telephony allowed us to process about 25000 calls per day, but it was not necessary and we reduced the number of calls from 25000 to 12000 through the automatization of processes and mobile applications. We reduced 30% of operators and increased the amount of orders by 40%.
Final solution
What were the gotchas in the project?
1.WebRTC, but it is a separate topic.

2. We could not immediately organize the fault-tolerance for Redis and other components.
3. During to the active scaling the problem with concurrency occurs.
4. If the problem with Redis occured, we used setnx; for problems with competitive access to database, we used atomic transactions and select_for_update.
What mistakes we did in general?
- We did not take into account the possible growth speed.
- We initially did not have a good balancing.
- At the moment of the report we changed Nagios for Sensu. It is nice, centralized and easy to use. Instead of Collectd we started to use Graphite. We use Newrelic to collect performance metrics with Node.js daemon. We use Cprofilemidleware in Django, Opbeat — to collect Django performance metrics. Then, if any of our metrics does not satisfy our expectations on the performance, we optimize this part of system.
We have educational alerts for developers and administrators. Up to two times per week, we check the fault-tolerance of any of running services by simply failing it. Up to two times per month we reload any of physical boxes and watch how it sets up.
The conclusions based on the whole report:
- The architecture of the solution should be adapted to the business processes;
- Do not be afraid to drastically change the architecture;
- Different work flows of large system should not affect each other;
- Nice architecture grows with you.


Latest articles here




