


Analyze with AI
Get AI-powered insights from this Mad Devs article:
Have you ever wondered how your favorite mobile app delivers lightning-fast updates or how social media platforms handle millions of messages per second? The secret lies in using data meticulously encoded and exchanged between systems. There are two powerful data joggle formats: Protocol Buffers (Protobuf) and JSON. While both serve as data serialization formats, their approaches and strengths differ vastly, shaping the digital landscape we experience.
Let's delve into the world of Protobuf vs. JSON, understanding their key differences, use cases, and, ultimately, which one reigns supreme in the battle for efficient data exchange.
How Protobuf works
Like a meticulous planner, Protobuf organizes your data, ensuring efficient communication and minimal resource usage. Ideal for microservices and resource-constrained environments, it champions speed and efficiency.
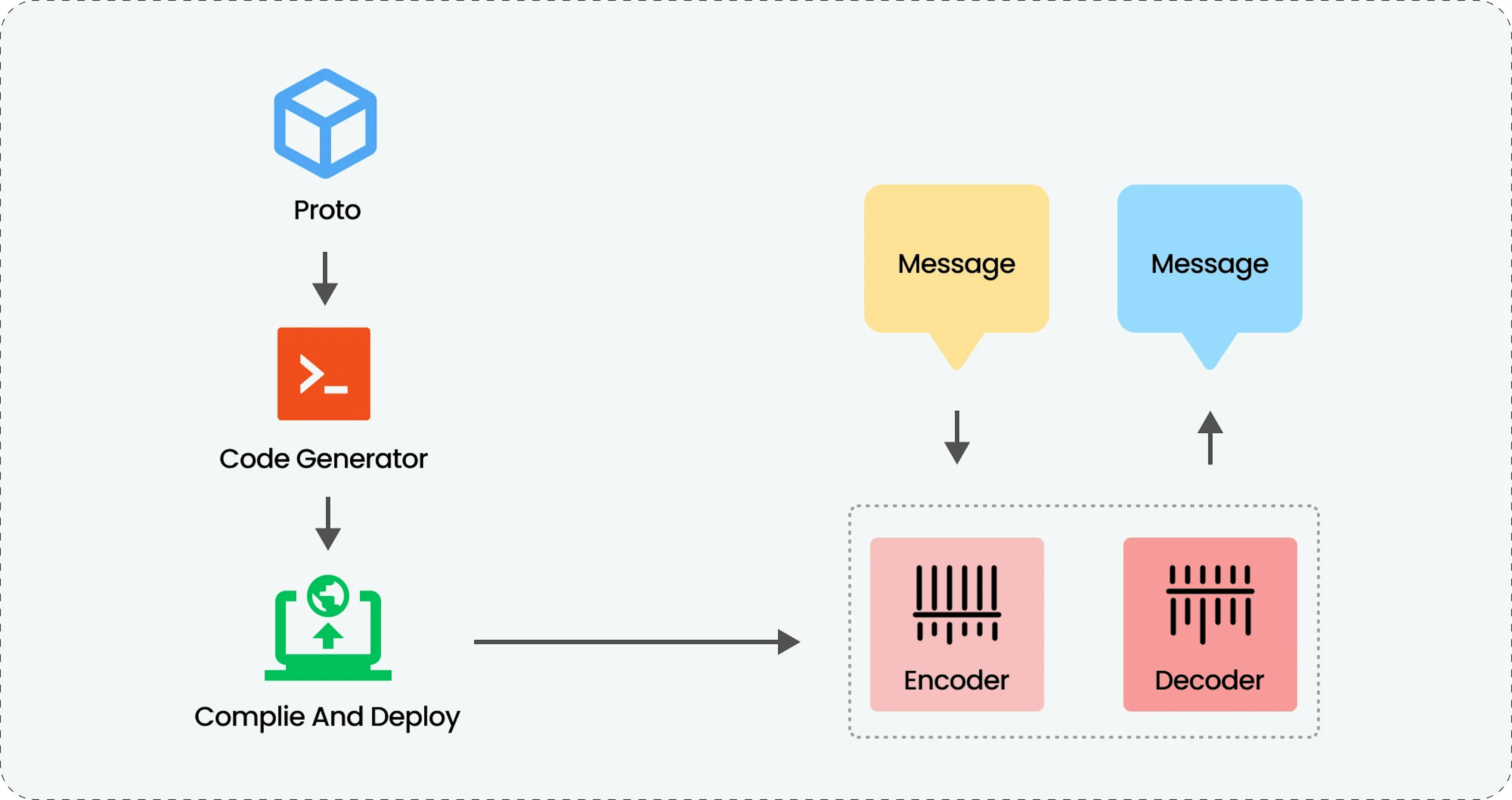
Here's a breakdown of the key elements and how they interact:
- The process starts with a message defined in a .proto file. This message acts as a blueprint for the data structure, similar to classes in programming languages.
- The message in the .proto file is sent to a code generator, which is a software tool. This code generator takes the message definition and creates code specific to your chosen programming language.
- The generated code includes two key functionalities: encoder and decoder.
Encoder — This part of the code takes the original data and converts it into the Protobuf format based on the message definition.
Decoder — On the receiving end, the decoder functionality takes the received binary data and converts it back into its original format based on the message definition. - The encoded data is then sent through a communication channel, which could be a network connection or a file. When received, the decoder translates the binary data back into its original format using the schema defined in the .proto file.
How JSON works
JSON keeps your data human-friendly and machine-readable. Popular for APIs and config files, it requires minimal setup and coding, making it perfect for quick work and data exchange.
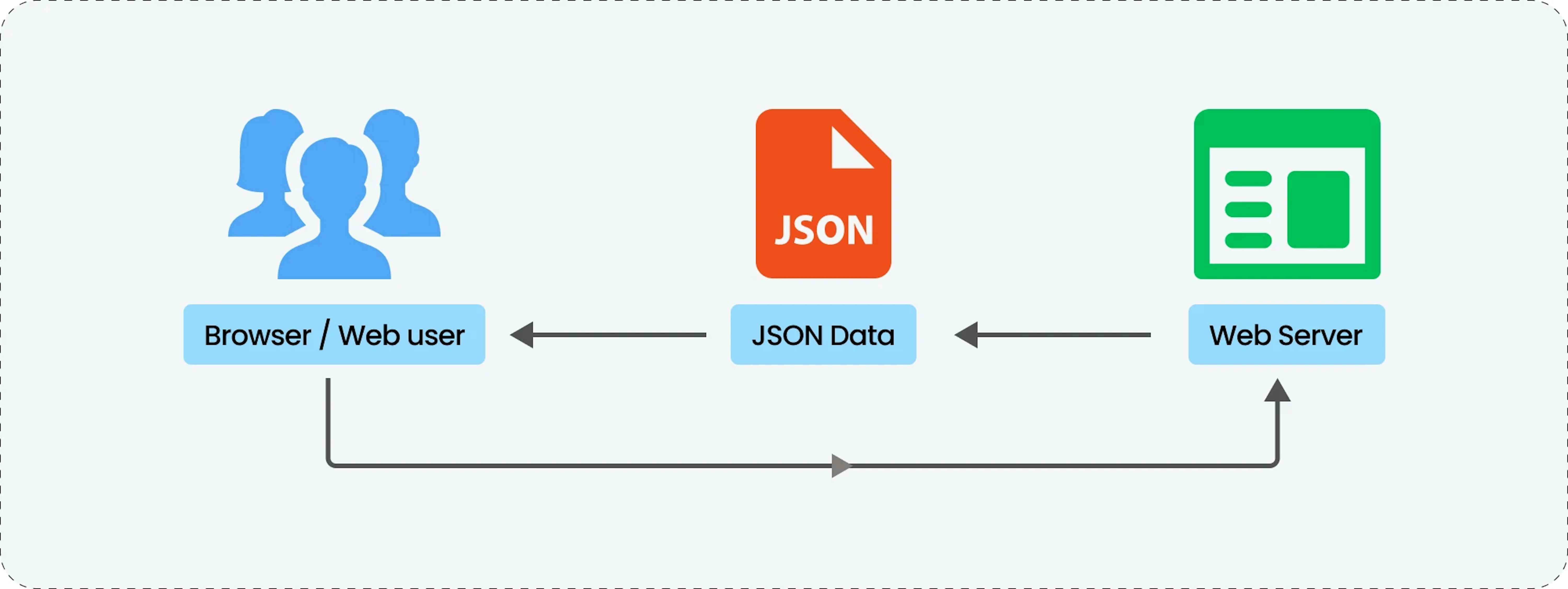
Here's a breakdown of the mechanism:
- The process starts with data, which can be anything from simple values like numbers and strings to complex structures like arrays and objects.
- This data is then encoded into JSON format. It consists of key-value pairs, where keys are strings and values can be strings, numbers, boolean values, arrays, or even nested objects.
- The encoded JSON data is then sent to a web server.
- A web user or browser requests the web server.
- The web server receives the request and returns the JSON data. The browser or web user then decodes the JSON data in its original format.
- Finally, the web user or browser displays or uses the decoded data.
Protobuf and JSON evaluation
Both formats excel in different areas, and understanding their strengths and weaknesses is crucial for making an informed choice. Let's delve into the key attributes of each format and evaluate them across various aspects:
Protobuf and JSON evaluation
| ASPECT | PROTOBUF | JSON |
|---|---|---|
| Performance | Faster: Encoding and decoding are significantly faster due to the compact binary format. | Slower: Encoding and decoding are slower due to the text-based format. |
| Size | Smaller: Binary format results in smaller data sizes, reducing bandwidth and storage needs. | Larger: Text-based format leads to larger data sizes. |
| Security | Requires additional security measures: Binary format itself doesn't provide inherent security. | Security considerations: Vulnerable to potential vulnerabilities in underlying languages/libraries. |
| Flexibility | Less flexible: Schema definitions restrict data structure changes. | More flexible: No schema required, allowing for dynamic data structures. |
| Human readability | Less human-readable: Binary format is not easily understandable without additional tools. | Highly human-readable: Text format is easily understandable by humans. |
| Tooling ecosystem | Growing ecosystem: Tools are available for various programming languages, but might be less widely supported compared to JSON. | Extensive ecosystem: Widely supported by programming languages and tools due to its simplicity. |
| Data integrity | Schema validation: Schema enforcement helps catch errors early in the development process. | Limited data integrity checks: No built-in mechanism to ensure data integrity. |
Use cases and examples
Both Protobuf and JSON are widely used for data exchange, but they excel in different areas. Here are some concrete examples and elaborations of their applications.
Protobuf
Microservices communication
Protobuf's efficiency and compact size make it ideal for communication between microservices, especially in large-scale systems.
Example: Google Cloud Platform (GCP) uses Protocol Buffers extensively for communication between its various microservices, promoting efficient and scalable service interactions.
Mobile app data exchange
Applications utilize Protobuf for efficient data exchange between mobile devices and servers. The smaller data size reduces network bandwidth usage, which is crucial for mobile app performance and battery life.
Example: Uber uses Protocol Buffers for data exchange between its mobile app and backend services.

JSON
Public APIs
Popular social media platforms use JSON for their public APIs, allowing developers to access and exchange data with their platforms easily. Its human-readable format simplifies integration and debugging.
Example: Twitter and Facebook expose their data through public APIs that primarily use JSON format. This allows developers to access and integrate their data into various applications easily.
Configuration files
Many applications use JSON for configuration files due to its ease of use and human readability. The key-value structure allows for storing and managing various configuration options in a clear and maintainable way.
Log messages
JSON is often used for storing and processing log messages due to its flexibility and ease of parsing. The structured format allows for efficient analysis and debugging of application behavior.
These are just a few examples, and the choice between JSON vs. protocol buffers ultimately depends on your project's specific needs and priorities. When deciding, consider factors like performance, size, flexibility, human readability, and tooling support.
Summing it up
So what is the best option in Google Protocol Buffers vs. JSON? Each format boasts distinct characteristics, requiring careful evaluation to select the optimal solution for your specific requirements.
For applications prioritizing performance and data integrity, Protobuf emerges as the champion. Its binary format and well-defined schema guarantee efficient transmission and robust data consistency, making it ideal for high-performance systems and large-scale data exchange.
However, JSON is the best option for flexibility and ease of use. Its schema-less nature fosters adaptability to diverse data structures and facilitates straightforward manipulation, rendering it perfect for evolving data or scenarios where clarity and accessibility are crucial.
Ready to unlock the power of efficient data exchange in your project? Schedule a free consultation with our experts at Mad Devs to discuss your specific needs and choose the optimal data format for your application.


FAQ
What is Protocol Buffers?
What is JSON?
Are Protocol Buffers better than JSON?
What is the difference between JSON encoding and Protobuf encoding?
When should I use Protocol Buffers?
Is there something better than JSON?
Latest articles here




