


Analyze with AI
Get AI-powered insights from this Mad Devs article:
The importance of logging
Logs are recorded events that your software produces. They are essential to every IT project since they provide the context to help debugging and solving problems in the application.
Logs in the project is a necessity. They show the quality level of the software team and the code.
Some developers place logs chaotically with print or fmt.Println without any care about formatting and meaning for future log viewers. Other developers use logging libraries, yet often this does not solve the problem of chaos in log files and inability to understand what exactly happened in the application.
Chaotic logging brings too much suffering. If a project runs in production, maintainers rewrite these logs almost every day if not hour trying to add more informative logs and eliminate “spam” logs. Yet, after the debugging is finished, all the added logs become useless and would be removed in the next iteration of debugging. There is a special place prepared in hell for those who do logging this way… and seems like they are always in that place in their development process.
Takeaway #1: do not do chaotic logging! Systematize them as soon as possible and never allow the clutter and chaos.
I would like to begin a series of articles about logging with two aspects that I consider essential to every newcomer that starts more or less serious development. These are logs formatting and logs levels. Also, it is essential to mention that these articles would have examples that are based on one of the most popular logging library for Golang projects — Logrus.
How you should log properly
A lot of junior developers and sometimes middle programmers even do not suspect that logging formats should be defined in advance so that every log in your project is well organized, carries the context, and is easy to find.
Regarding the general log formatting, I recommend placing a package name and function name that invoked a particular event. This helps to quickly find out where the event took place and take appropriate actions.
The most obvious way to log something is just to … log it.

Yet a better option, in the long run, is to spend 10–15 more seconds and log more information.
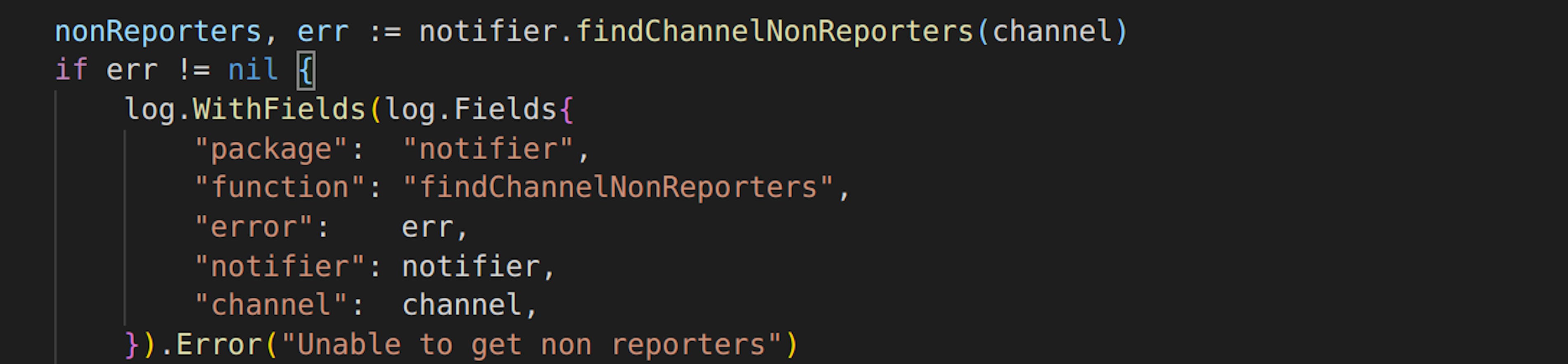
The first method, even though logs everything you need right now, will bring troubles in the future, since it lacks a lot of contexts. And in the future, the only person who would understand what was going on is you, but probably you yourself would forget everything about it.
In most cases, I recommend using log.WithFields(). Error() log construction, since it allows to create separate Fields for different variables and therefore orient among them fairly easy and fast.
You can save hours or even weeks of work for future self just by properly describing how logs should be formatted in any place of your project. Remember, adding new logs, do not be lazy to take care of formatting. This is your future investment. By the way, you should only add logs to your project and avoid removing them at all…
Logging levels in Go
Many beginners do not quite understand why there are so many logging levels and even if they more or less understand it is difficult to properly place logs if different levels to comfortably use them.
As a result, development or debugging in a project turns into chaotic addition and removal of logs to understand why things happen in a particular way in production. In the following commits spam logs are removed (just to be again added a few commits later). This is a problem and if you experience something similar, it is time to stop and think on how to place logs of different levels to your code so that there would be no need to remove them at all.
Convenience in logging is when the amount of spam logs reaches 0 level and all the logs serve its particular purpose. They are never removed but only added.
Logging libraries(in particular Logrus) have the option to configure logging levels, showing or hiding log messages of different levels. The levels I would like to talk about now are: "Fatal," "Error," "Info," "Warning," "Debug," All other common levels have a more or less similar purpose (Panic vs Fatal), or are very specific (Trace).
When to use fatal/panic logs in Go
Where should we place fatal/panic logs? They should appear when the software can no longer continue its performance. For example, when the project could not start simply because the database could not start or configs could not load properly. These logs are often placed at the very beginning of the code to "fail fast" and do not go further if something went wrong with setup of essential components
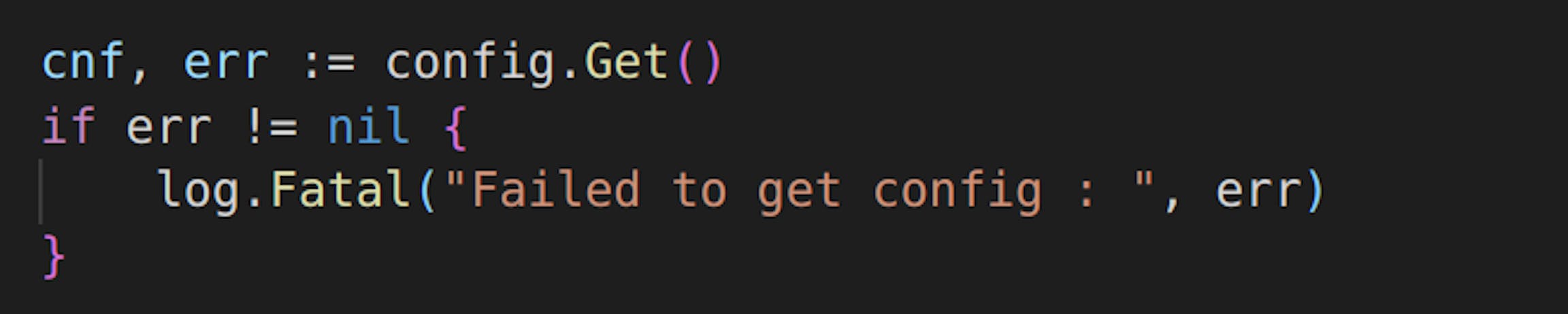
React on Fatal/Panic logs immediately!
When to use error logs in Go
Error level is for real errors, errors that you do not expect to get, errors that must be immediately taken into account and handled. For example if the request in database failed with syntactic error or missing table or some essential component had broken. Error logs are just like fatal and panic levels should be sent to different monitoring instruments (like Sentry) for immediate warnings to most productively use available resources.
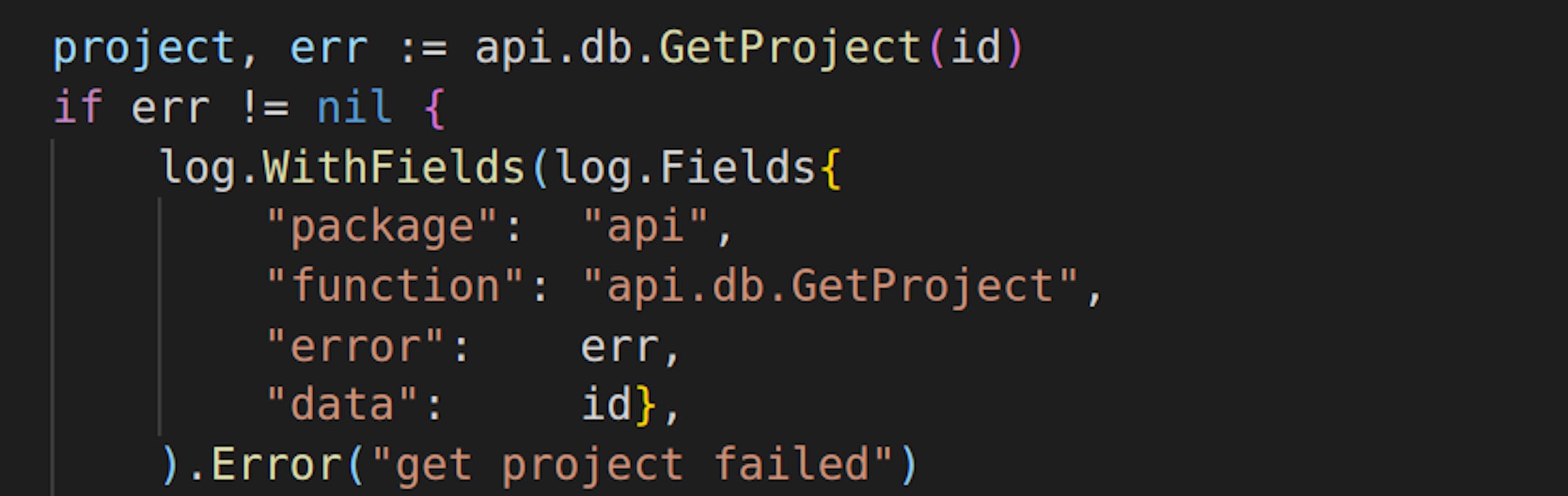
Error level logs should trigger and be fixed as soon as possible, do not allow them to happen again.
When to use warning logs in Go
Warning takes care of everything to pay attention to yet, bear in mind that this is all programmed meaning no errors, everything goes right way. For example validations of structures, skipping iterations for some loops, etc.
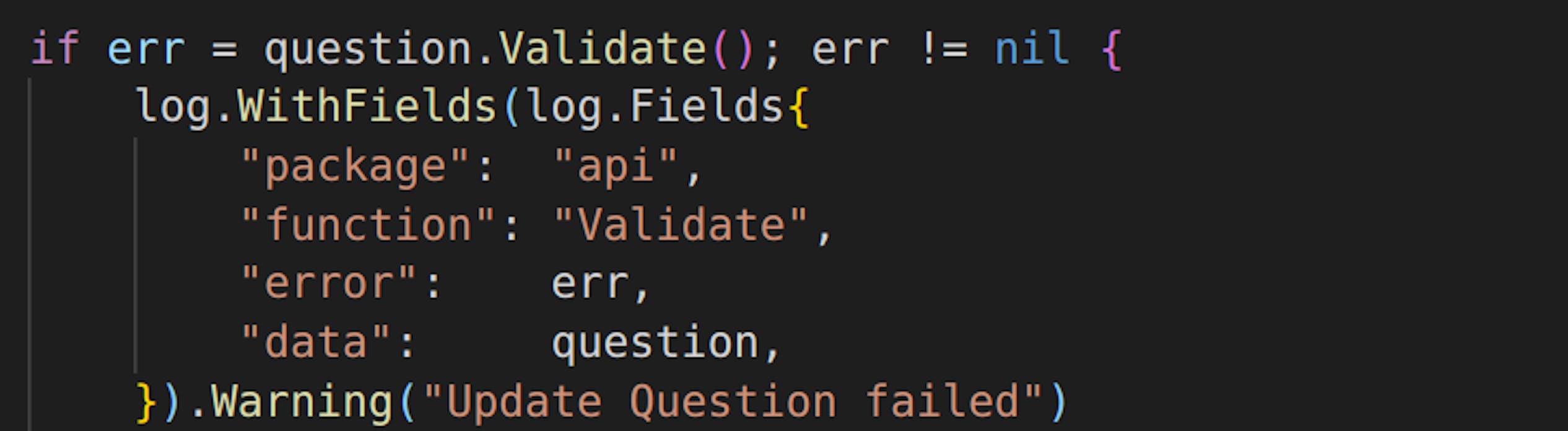
Warnings is everything that you may pay attention or sometimes should pay attention, but it should not trigger you as much as errors and force you to fix things right away.
When to use info logs in Go
Info level can be used everywhere where additional info is needed. This level is pretty universal and often mixed up with warning, or debug logs. Personally I do not recommend using it as it is very neutral and could mean almost anything. It is better to use the next logging level to better understand how to use the provided info
When to use debug/trace logs in Go
Debug/trace level logs should provide very detailed info about the events of the app. What are the incoming requests, how they are handled, what changes as business logic goes, what is sent in response, and so on. All these will be really helpful in debugging and error tracing to identify all data changes and why things are the way they are.
Debug/trace logs are like microscope, you do not need one always, just in a very particular situations. Therefore turn these levels off in production not to clutter the log files
To sum it up:
- Use well developed/supported logging instruments since it saves your time and helps to format logs better.
- Think and plan your logging format in advance to always know where and how to place a particular log so that it serves its purpose and only improves debugging.
- Use logging levels appropriately, since it is really hard to read, understand, and debug the application if it has a lot of useless logs or does not have enough logs. Both options are no good for you.
When the format is set and the levels are used appropriately it is time to set the configuration of the log the way it is easy to change logs and control them. Also, it is easy to view and react to them. All these I would like to explain in the next part of the series. Stay tuned!
In the second part of the article, we will talk about how to control your logging in Go.


Latest articles here





