


Analyze with AI
Get AI-powered insights from this Mad Devs article:
Our team started to apply DevOps practices long before we registered Mad Devs as a company. Specifically, I ran into this approach more than 10 years ago in a different company where I worked as a System Administrator.
Back then, this term did not exist yet, but people, including myself, already applied not yet formalized rules and principles that became known as DevOps:
- continuous integration;
- automatic deliveries;
- the responsibility of each team member for the product;
- direct communication with the customer;
- collection and analysis of business/application metrics;
- documentation, etc.
In fact, all this was a logical extension of the practices listed in the Agile manifesto and started from the moment when the developer stopped writing code for the localhost.
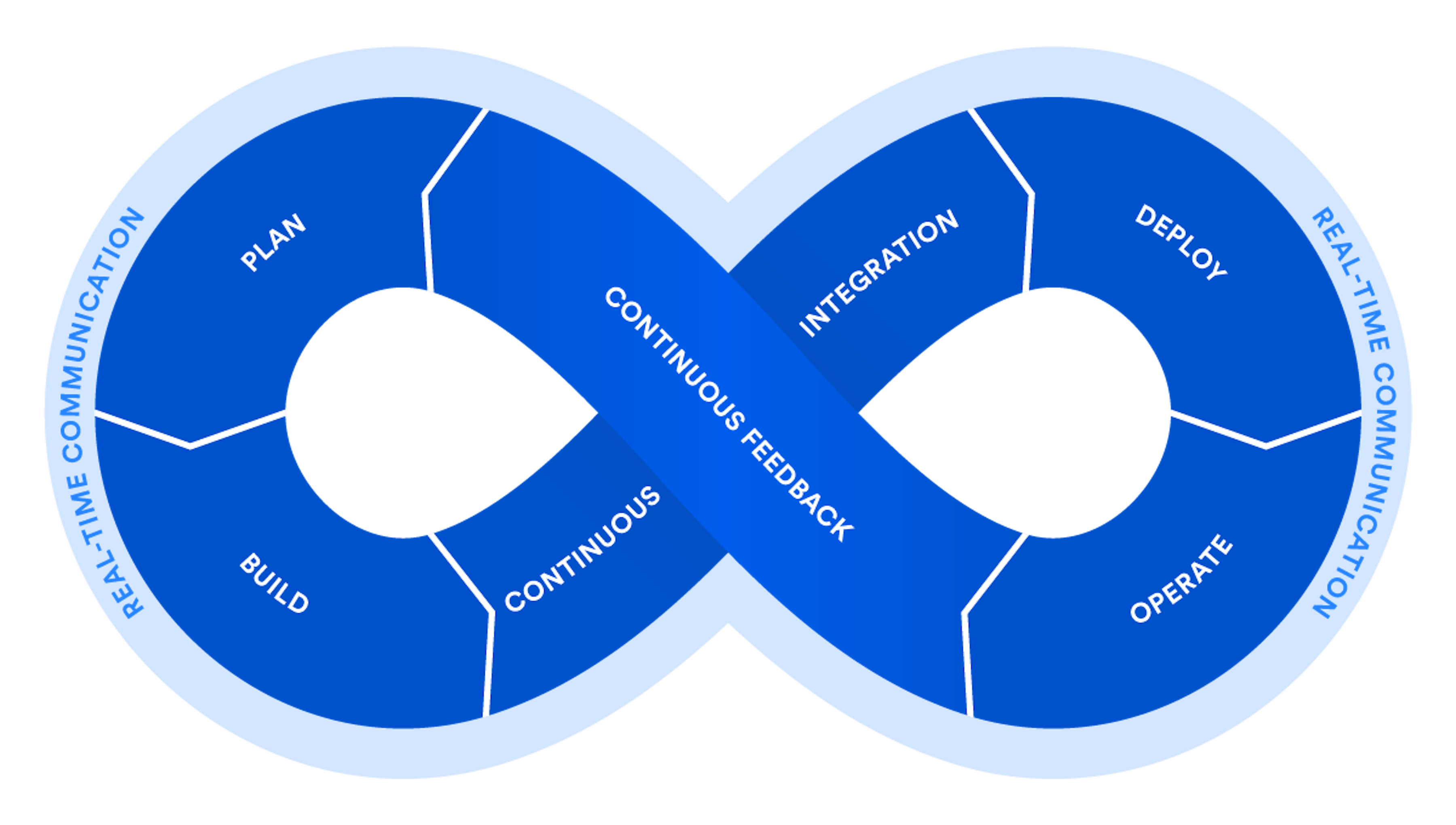
The principles of DevOps voiced by Atlassian
The DevOps scheme presented by Atlassian back then is still relevant today. In essence, it is the modern cycle of product development and delivery, which also includes its after-launch operation.
Pre-DevOps era: a wall between admins & developers
For a long time, the operation of the product was separated from the development and developers. This was done by some uninhabited, evil creatures calling themselves sysadmins. Sysadmins did not participate in the development and communication. They got code packages from a hole in the wall and tried to run this code somewhere, yelling the four-letter words. Each attempt of running it was painful. They had to spend several days staring at the logs, searching for an incomprehensible error, profiled database queries, got stuck in the strace, etc. Later, it turned out that it was only necessary to define a new environment variable or add a new parameter to the config: it was just the developer who failed to warn the admin, who was only aware of the product's name and the fact that it was written in PHP…
How I started as a DevOps engineer 10 years ago
Returning to the nostalgic past: when I started to do the admin job in my team 10 years ago, I was not put in the basement away from other people, like a stereotypical admin. On the contrary, I got a workplace in the thick of developers. This was the moment when I started as a DevOps engineer. At the same time, I learned that despite the importance of knowledge and skills, even more priority should be given to communication and the ability to directly affect the product from a position of operations. I had the right to object and voice my concerns, and the developers were able to convey or adjust their requirements long before delivery. If your admins try it, they will never agree to take a seat in the basement!
It quickly became clear that when the product’s design, development, and operation are considered together, it’s really beneficial. When everyone is responsible for the product and knows where, how, and what is launched in the production environment, providing a developer with access to "production" is no longer an issue. Of course, neither Ops nor Devs should be there without a serious need, but back then, it was a cultural shock — the developer was logged in, and it didn’t go down! This is definitely impossible when you build a wall between your Devs and Ops.
But if DevOps is an Agile development process with the exploitation phase added to it, then who are these DevOps engineers? What’s on the list of core responsibilities in the DevOps world? And, last but not least,
Who is an ideal DevOps team leader?
This role in a team can be taken over by a mid-level professional, regardless of the job title or occupation (we can consider developers, admins, or even QA staff). The main purpose of DevOps’ existence is to fill the hole in the cycle of continuous integration, delivery, and operation of the product.
In my subjective opinion, it's better when DevOps is led by someone with the admin background (but not the 'any key' specialist). In this case, this person will handle the team's load related to low-level questions like database upgrade, configuration management, or any other infrastructural things that may distract or annoy developers. I would also bring another point to justify the admin's start as DevOps' lead: with the product's growth and development, the DevOps team also starts to grow and develop. It will require more time and effort, and if a Developer leads your DevOps team, this Developer will start to screw up in development. My last point in favor of an admin-led team is that the entry-level is lower for an admin, so this means a faster start.
What should DevOps know? A list of critical skills by MadOps
What should DevOps know and be able to do? We have come up with our own list of requirements for DevOps engineers. Disclaimer: I will not list all the points here. I will summarize the core skills they should possess.
Principles of Agile development. This is one of the most important skills in the modern world of development (and especially remote one). This includes not only the ability to distinguish Kanban from Scrum, but also the ability to communicate with the team, understand the value for the customer, track time, as well as create readable work logs, standup reports, and clear documentation.
Automation + Everything as a code. You should get rid of the manual 'monkey job' as soon as possible. Nowadays, there's a tool for almost every routine task. If you failed to find a ready-made tool, you could always use Python and bash to write it for yourself. For example, if you need to create a VM image, then use Packer. If you configure 10+ hosts, go ahead with Ansible. If you create a Kubernetes cluster in Google Cloud Platform or work on a CDN on Amazon, make your life easier with Terraform. Everything should be automated, from loading a new bare-metal server over the network to deploying a new container into the existing cluster. The code you write should be reproducible and idempotent. Commits must be justified by the task in the tracker and obey the point above.
Cloud and hybrid architectures. We are currently seeing companies striving not to be dependent on just one cloud vendor (and they have grounds for this concern). You shouldn't be a fan and evangelist of only one solution for the cloud. Different parts of the service can run on AWS, Heroku, and other IaaS, PaaS, and SaaS. It is necessary to find the most advantageous solution and be able to migrate service between platforms in an adequate period of time. Do not forget the automation I mentioned, to make the migration less painful.
Scalability & high availability requirements. It is important to be aware of the business' tolerance to downtime and loss of data for a certain period, etc. It is pointless to ensure high availability for a resource that can be down for 24 hours with no serious damage to a business. At the same time, an hourly downtime on another resource may cost more than its full hot-standby copy paid for a year in advance. Scaling up has become much easier with clouds and containerization. However, both the infrastructure and the service itself must be ready to scale (here, I should mention the most common pain of using local storage for objects).
Monitoring & alerting. For the retrospective, forecasts, and reactions, it is necessary to collect all available metrics for your system, application, and business. The team must have eyes. There is no universal solution for monitoring. Each cloud service or platform offers its own set of available metrics and alarms, but very often, using just one solution is not enough. You can use external systems like Librato or Datadog or build a custom monitoring service on top of Prometheus. Everything is based on budget, time, and tasks.
Security. Ensuring security is not the core responsibility of a DevOps engineer. However, knowledge of the basics is necessary. SSL on endpoints, no * in policies, no public or open-to-write buckets, encryption for partition, closed firewalls and securitized groups, MFA, etc. In addition to this, DevOps should work with the Security Department to automate processes and quickly apply new security policies for services.

What if everything seems to be working without a DevOps engineer?
What can a DevOps expert do if everything seems to be configured and working? Let's admit that the developers have set up an environment, figured out how to run the database, and created an autoscale group. Alternatively, even simpler than that, let's say that they have launched an application on Heroku, added the necessary addons, and can sleep well. There are some alerts and metrics in place, and everything looks good.
In this case, I would address the following concerns.
- Since everything is usually done manually, it is impossible to reproduce the architecture or restore a part of it if your cloud vendor has problems.
- The costs are high due to a lack of control over resource consumption. Many things might be abandoned once configured, but they are still paid for. Usually, the fast launch is the priority, so in many cases, there's no research for costs and comparison of various offers and alternatives. There are no reserved instances purchased in advance.
- The deployment process is not well established. There's no practice of consistent testing. Integration tests are rarely in place. Testing is done locally by the developers if tests are ever run at all.
- There are strange bugs that appear only in production and cannot be reproduced locally in any way. This affects the customer's trust in the IT department, which has to participate in constant battles with the project's Product Owner.
- Performance issues occur for no clear reason. There are SPOFs here and there, workarounds and repairs take a lot of time, which slows down the already slow development process even more.
- There's a need to migrate your service to another platform and prepare the current architecture for rapid growth.
- Monitoring alerts come too late to take action. The team will be the last to know about the issue of downtime. In worst cases, it happens after the users and the customer notices it.
This list is incomplete. I could have named many more issues. Some of them can be solved in a timely conversation, and some require changes in the delivery and development process. To proceed with these changes, you might need purely technical skills or knowledge of a particular platform. In any case, even the short participation of a skilled DevOps pro in a project will have a positive impact on your team and the development process in general.
P.S. Credits to Oleg Puzanov, who inspired me to write this article for our blog.


Latest articles here




