


Analyze with AI
Get AI-powered insights from this Mad Devs article:
The world is increasingly driven by machines that can see, interpret, and interact with their surroundings. Computer vision, once a niche branch of AI, now shapes industries ranging from healthcare to autonomous systems, redefining how we perceive technology's role in our lives.
In 2025, computer vision isn't just about recognizing images—it's about understanding context, predicting behaviors, and enabling machines to collaborate seamlessly with humans. Behind this revolution are groundbreaking algorithms that transform abstract pixels into actionable insights.
This article highlights the must-know computer vision algorithms of 2025, covering their core principles and practical applications.
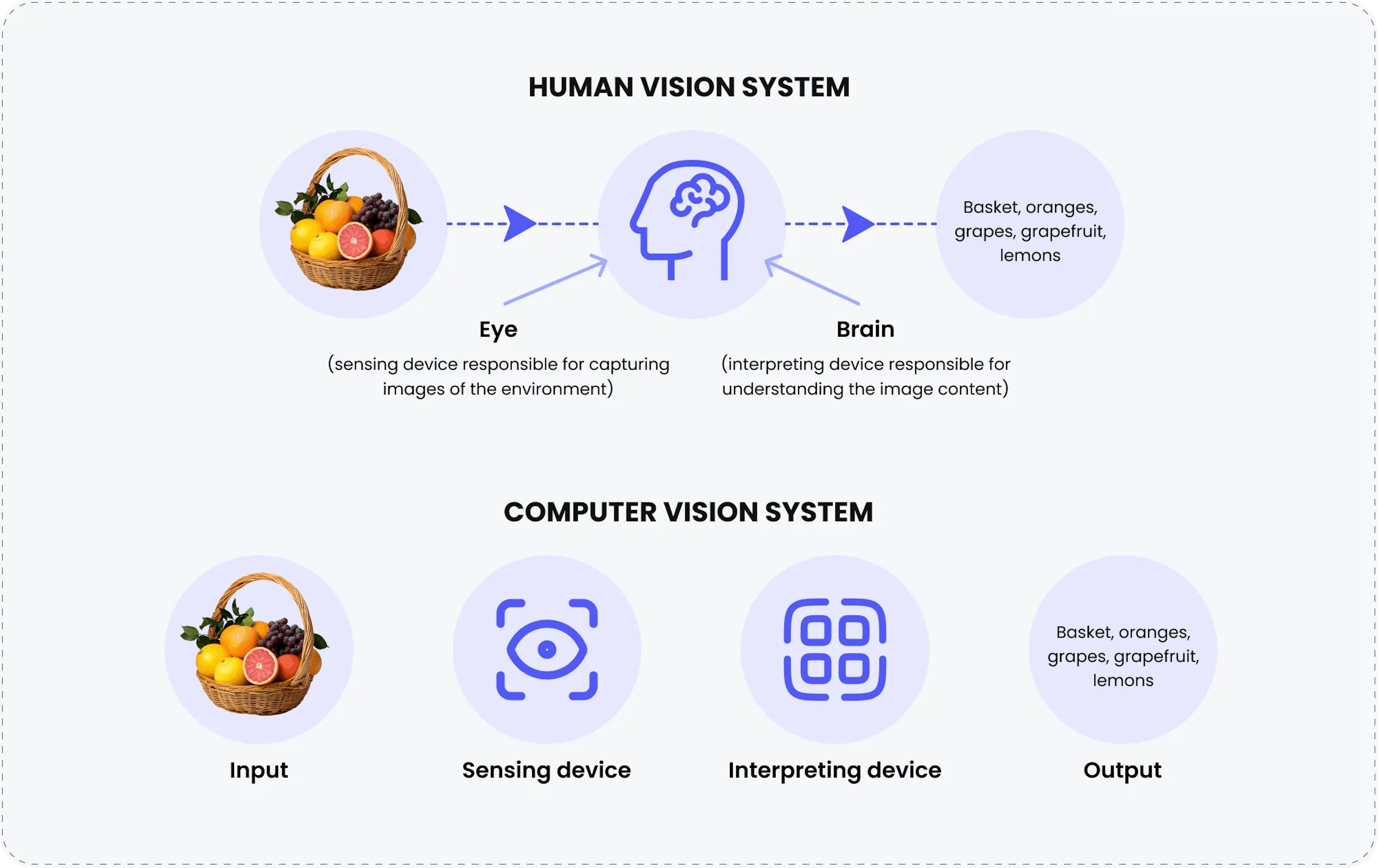
Why is computer vision important?
According to Statista, the computer vision market is poised for significant growth, with its market size projected to reach $29.27 billion by 2025. Over the period from 2025 to 2030, the market is expected to grow at a compound annual growth rate (CAGR) of 9.92%, expanding to a total value of $46.96 billion by 2030.
Globally, the United States is set to lead this growth, with an estimated market size of $7.8 billion in 2025, reinforcing its position as the most significant contributor to the computer vision industry.
Computer vision uses advanced software and algorithms to replicate human vision and cognition, enabling machines to perform tasks like object recognition, flaw detection, and quality control.
The core components of computer vision are:
Acquisition of an image
This step involves capturing images or visual data using digital cameras or sensors, storing the information as binary numbers. This raw data serves as the foundation for all subsequent processes.Image processing
Image processing extracts fundamental geometric elements and removes noise or unwanted elements through preprocessing. This step ensures a cleaner, more accurate image for further analysis.Analysis
In this phase, advanced algorithms analyze the processed image. Techniques such as deep learning and neural networks are used to identify objects, classify patterns, and make decisions based on visual data.
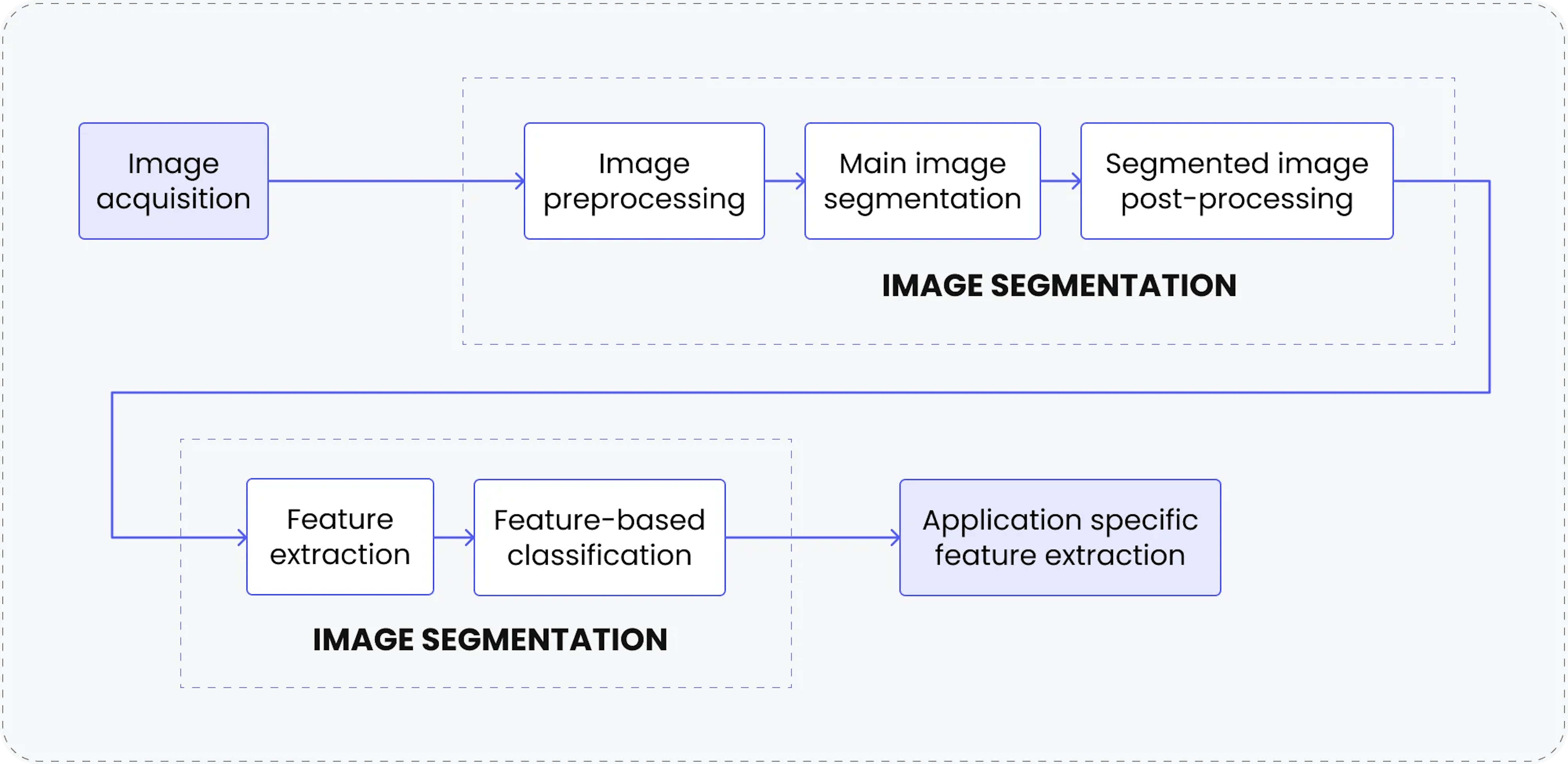
CV is revolutionizing numerous industries by enabling machines to interpret and act upon visual data, fostering innovation, and enhancing efficiency. From streamlining everyday processes to addressing complex challenges, CV drives advancements that are shaping the future. Below are key use cases and their profound impact:
Autonomous vehicles
Computer vision is the driving force behind the automotive industry’s push toward fully autonomous transportation. This technology is transforming safety standards and redefining mobility by equipping vehicles with the ability to analyze their surroundings, detect obstacles, and make instant decisions. The most prominent examples: advanced driver-assistance systems (ADAS), fully self-driving cars.
Healthcare
The integration of computer vision in healthcare is reshaping diagnostics and treatment methodologies. Algorithms assist in identifying anomalies in X-rays, MRIs, and CT scans, enabling early disease detection and personalized treatment plans.
Retail and e-commerce
Cashier-less stores use vision systems to track items in real time, creating a seamless checkout process. In e-commerce, virtual try-on tools for apparel and cosmetics allow customers to visualize products before purchasing, enhancing satisfaction and reducing returns. These advancements improve user experience and drive operational efficiency and profitability for retailers.
Manufacturing
These systems meticulously inspect products for defects, ensuring flawless output in assembly lines. By automating quality control and enabling predictive maintenance, computer vision reduces downtime, minimizes waste, and enhances overall production efficiency, driving more imaginative and more sustainable manufacturing processes.
Agriculture
Drones with vision systems monitor crop health, identify pest infestations, and assess soil conditions. Autonomous robots can handle tasks like weeding and harvesting, optimizing resource use, and boosting yields. By offering real-time insights and automation, computer vision supports sustainable agriculture and helps farmers meet global food demands.
Security and surveillance
AI-driven vision systems identify suspicious activities, enhance facial recognition, and provide real-time alerts, making public spaces safer.
Entertainment and media
Computer vision is revolutionizing how content is created and consumed in the entertainment industry. This technology brings new levels of creativity and precision, from detecting and preventing deepfakes to automating video editing and enhancing special effects. Vision algorithms are also used in immersive experiences like augmented reality (AR) and virtual reality (VR), pushing the boundaries of storytelling and user engagement.
11 computer vision algorithms: from classical to cutting-edge
CV has evolved significantly over the years, from foundational algorithms to modern AI-driven methods that redefine what's possible in image processing and analysis. Here is an overview that explores these algorithms' strengths, limitations, and unique use cases, highlighting their roles in shaping the future of computer vision:
1. SIFT (Scale-Invariant Feature Transform)
SIFT is an algorithm for detecting and describing local features in digital images. It identifies keypoints and assigns them descriptors—quantitative details used for object detection and recognition. Imagine trying to spot a friend in a crowded stadium—SIFT does something similar for images. It identifies unique features like corners or edges, acting like a "fingerprint" for objects.
Advantages:
- Robust to size and orientation changes.
- Performs well under varying lighting conditions.
- Effective for precise applications like medical imaging.
- Used in image stitching, object recognition, and 3D reconstruction.
Disadvantages:
- Unsuitable for real-time or large-scale tasks.
- Requires significant storage for keypoints and descriptors.
- Struggles with very noisy images.
Use cases:
- Image stitching — Creating panoramas by matching overlapping images.
- Object recognition — Identifying objects across images despite transformations.
- 3D reconstruction — Building models from multiple views.
- Medical imaging — Aligning diagnostic scans.
- Mapping — Feature detection for autonomous navigation.
2. SURF (Speeded-Up Robust Features)
SURF is an algorithm for detecting and describing local features in digital images, designed as a faster alternative to SIFT. It locates keypoints and assigns them descriptors for object detection and recognition. Think of SURF as a speedier version of spotting your friend in a crowd—it focuses on efficiency while retaining accuracy, identifying features like edges and blobs to create "fingerprints" for objects.
Advantages:
- Faster than SIFT due to simplified calculations.
- Robust to scaling, rotation, and minor lighting changes.
- Effective for real-time applications.
Disadvantages:
- Less robust than SIFT in extreme lighting or perspective changes.
- May miss fine details due to its focus on speed.
- Still computationally intensive for very large datasets.
Use cases:
- Real-time object recognition — Quick feature detection in applications like video processing.
- Image matching — Identifying similarities between images in real-time tasks.
- Augmented reality — Tracking objects for overlaying AR content.
- Navigation — Feature detection in robotics and autonomous vehicles.
ORB (Oriented FAST and Rotated BRIEF)
ORB is a fast, efficient algorithm for detecting and describing local features in digital images, developed as an open-source alternative to SIFT and SURF. It combines the FAST keypoint detector and BRIEF descriptor, adding rotation and scale invariance. ORB is the go-to choice for applications prioritizing speed and efficiency, particularly in real-time or resource-limited settings. While it may not offer the same level of precision as SIFT or SURF, its speed and versatility make it a popular choice for modern computer vision tasks. Widely used in AR/VR applications, robotics (for example, SLAM), and other resource-constrained scenarios.
Advantages:
- Extremely fast and efficient, suitable for real-time applications.
- Open-source, with no licensing restrictions.
- Rotation and scale invariant for reliable feature matching.
- Works well on large datasets and low-power devices.
Disadvantages:
- Less accurate than SIFT or SURF in complex or noisy environments.
- May struggle with extreme changes in illumination.
- Descriptors can sometimes lead to mismatches in high-dimensional data.
Use cases:
- Quick and efficient for tasks like facial recognition.
- Mobile applications — Ideal for AR apps or games on low-power devices.
- Robotics — Feature tracking for navigation and SLAM (Simultaneous Localization and Mapping).
- Image stitching — Faster panorama creation for real-time systems.
- Video processing — Frame-by-frame feature detection in dynamic scenes.
Viola-Jones
The Viola-Jones framework is a pioneering algorithm for real-time object detection, most famously used for face detection. Developed by Paul Viola and Michael Jones in 2001, it uses a cascade of classifiers to quickly and efficiently detect objects in digital images. Think of Viola-Jones as a sharp-eyed security guard scanning a crowd—it rapidly focuses on areas likely to contain the object of interest, skipping irrelevant details.
Advantages:
- Extremely fast and efficient for real-time applications.
- Accurate for detecting simple, well-defined objects like faces.
- Scales well to different image sizes and resolutions.
Disadvantages:
- Limited to specific object types; less effective for complex or cluttered images.
- Sensitive to variations in lighting, pose, and orientation.
- Prone to false positives if the detection window overlaps non-object regions.
- Outperformed by modern deep learning methods in accuracy and adaptability.
Use cases:
- Face detection — Widely used in camera apps, surveillance, and biometric systems.
- Object detection — Identifying predefined objects like eyes, mouths, or pedestrians.
- Image filtering — Rapid object filtering in preprocessing pipelines.
- Video surveillance — Real-time detection of faces or other objects in live video feeds.
- Augmented reality — Quickly locating faces or features to overlay AR elements.
While they aren't the "trending" algorithms in 2025, they remain essential in certain contexts and serve as a bridge between classical computer vision and modern AI-driven approaches.
Where do they still shine?
- Low-resource environments — ORB and Viola-Jones are ideal for edge devices with limited computational power.
- Niche applications — Tasks like image stitching, 3D reconstruction, or small-scale projects may still favor classical methods due to simplicity and interpretability.
- Educational value — These algorithms are staples for learning the fundamentals of computer vision and understanding feature extraction principles.
Understanding the fundamentals is crucial before diving into cutting-edge technologies. Now, let's explore the more advanced modern approaches.
Mask R-CNN
Mask R-CNN is an advanced deep learning model designed for instance segmentation, extending Faster R-CNN by adding a branch that predicts segmentation masks for each detected object. Introduced by Kaiming He in 2017, it identifies and localizes objects and generates precise pixel-level masks. A close example is a highly skilled artist—it doesn't just spot objects but carefully outlines their shapes.
Advantages:
- Combines object detection and segmentation for precise instance-level analysis.
- Works effectively across diverse tasks like segmentation, object detection, and keypoint detection.
- Adapts well to various datasets and object categories.
Disadvantages:
- Requires significant resources for training and inference.
- Segmenting each instance increases runtime compared to simpler models.
- More challenging to implement and fine-tune than basic detection models.
Use cases:
- Autonomous driving — Segmenting and detecting objects like pedestrians, vehicles, and traffic signs.
- Medical imaging — Identifying regions of interest, such as tumors or organs, in X-rays or MRIs.
- Video analysis — Tracking and segmenting objects frame-by-frame in video feeds.
- Retail analytics — Analyzing shelf stock by segmenting and counting individual products.
- Augmented reality — Overlaying AR elements on segmented objects for a seamless user experience.
YOLO (You Only Look Once) Series
The YOLO series is a family of real-time object detection models designed for speed and accuracy. First introduced by Joseph Redmon in 2016, YOLO reframes object detection as a single regression problem, predicting bounding boxes and class probabilities directly from an image in one pass. Think of YOLO as a lightning-fast scanner—it takes one look at an image and immediately identifies and localizes objects.
It is the most important representative of one-stage detectors, known for its efficiency in balancing speed and performance.
Advantages:
- Capable of processing videos and images at high frame rates.
- Treats object detection as a single unified task.
- Works effectively across a variety of domains, from autonomous driving to surveillance.
Disadvantages:
- Struggles with detecting very small or overlapping objects.
- Faster versions prioritize speed, potentially sacrificing some accuracy.
- Requires well-annotated datasets for optimal performance.
Use cases:
- Surveillance — Detecting objects or people in live security feeds.
- Autonomous vehicles — Identifying pedestrians, vehicles, and road signs in real time.
- Retail analytics — Counting customers, monitoring inventory, or detecting shelf stocking.
- Healthcare — Detecting abnormalities in medical images like X-rays or ultrasounds.
- Sports analytics — Tracking players and equipment in fast-paced games.
Vision Transformers (ViT)
Vision Transformers (ViT) are cutting-edge models that adapt the transformer architecture, originally designed for natural language processing, to process images. They divide an image into patches, treat each patch as a token, and leverage self-attention mechanisms to understand global relationships in the image. Think of ViT as a strategist, analyzing the entire "big picture" rather than focusing on local details alone.
Advantages:
- Captures relationships across the entire image, outperforming traditional methods on large datasets.
- Excels in tasks like image classification, object detection, and segmentation.
- Modern adaptations, such as DeiT, improve performance with smaller datasets.
Disadvantages:
- Requires extensive labeled datasets for optimal performance.
- It demands significant hardware resources and limits use in low-resource environments.
- More challenging to train and tune compared to classical methods.
Use сases:
- Image classification — High-accuracy classification in fields like medical diagnostics.
- Object detection — Advanced detection tasks in autonomous vehicles and robotics.
- Segmentation — Precise image segmentation for use in AR/VR and video editing.
- Medical imaging — Analyzing X-rays, MRIs, and CT scans with unmatched detail.
- Satellite imagery — Extracting meaningful patterns for geospatial analysis.
Neural Radiance Fields (NeRFs)
NeRFs are a groundbreaking technique for synthesizing 3D scenes from 2D images. Introduced by Ben Mildenhall et al. in 2020, NeRFs represent a scene as a continuous volumetric field, predicting color and density at any 3D point. Think of NeRFs as virtual sculptors—they take scattered 2D photographs and “carve” them into a realistic 3D model.
Advantages:
- Produces high-quality, detailed 3D reconstructions with realistic lighting and textures.
- Works with sparse or unstructured 2D image data.
- Encodes complex 3D scenes in a compact neural network.
Disadvantages:
- Requires significant training time and hardware resources.
- Primarily suited for static objects and environments, though dynamic NeRF variants are emerging.
- Relies on high-quality, diverse input images for optimal results.
Use cases:
- Virtual Reality (VR) and Augmented Reality (AR) — Creating immersive environments from real-world scenes.
- 3D reconstruction — Digitizing cultural heritage sites, sculptures, or environments for preservation and study.
- Special effects — Generating realistic backdrops or objects in movies and games.
- Mapping and simulations — Building accurate 3D maps for robotics, autonomous navigation, or geospatial analysis.
- E-commerce — Displaying 3D product models for a more interactive shopping experience.
Contrastive Learning (SimCLR, BYOL)
Contrastive learning is a self-supervised learning approach that trains models to distinguish between similar and dissimilar data points. Methods like SimCLR (Simple Contrastive Learning of Representations) and BYOL (Bootstrap Your Own Latent) leverage this technique to learn meaningful representations from unlabeled data by comparing augmented views of the same image. Imagine it as training your brain to recognize a friend from different angles or lighting conditions.
Advantages:
- Eliminates the need for large labeled datasets, reducing reliance on manual annotation.
- Produces general-purpose features applicable to various downstream tasks like classification or segmentation.
- Learns invariant features despite transformations like cropping, rotation, or color changes.
Disadvantages:
- Requires large batch sizes and powerful hardware for effective contrastive comparison.
- The quality of learned representations depends heavily on appropriate augmentations.
- Some methods (especially SimCLR) rely on large negative samples, which may complicate implementation.
Use cases:
- Image classification — Pretraining models for improved performance on downstream classification tasks.
- Medical imaging — Leveraging unlabeled scans to create robust feature representations for disease detection.
- Object detection — Enhancing detection models by learning invariant features from raw image data.
- Recommendation systems — Extracting patterns from user interactions or item attributes without explicit labels.
- Video analysis — Learning representations for action recognition or scene understanding from unlabeled video clips.
CLIP (Contrastive Language–Image Pretraining)
CLIP is a groundbreaking model developed by OpenAI that learns to connect text and images through contrastive learning. It is trained on a large dataset of image-caption pairs, enabling it to understand visual concepts and associate them with natural language. CLIP is similar to a bilingual translator for vision and language—it seamlessly links what you see to how you describe it.
Advantages:
- Bridges the gap between visual and textual data, enabling tasks like zero-shot classification.
- Can generalize to unseen tasks and domains without additional fine-tuning.
- Leverages large-scale datasets for robust performance across diverse scenarios.
Disadvantages:
- Performance is influenced by biases present in the training data.
- Training and deploying CLIP require significant computational resources.
- Struggles with tasks requiring fine-grained distinctions within a category.
Use cases:
- Zero-Shot classification — Classifying images into categories without task-specific training (e.g., labeling museum artwork).
- Content moderation — Identifying inappropriate or harmful content in images based on textual descriptions.
- Search and retrieval — Enabling image or text-based searches in multimedia databases.
- Creative applications — Generating artwork or curating visuals based on textual prompts.
- Augmented reality (AR) — Associating objects in the real world with descriptive labels for enhanced user interaction.
Diffusion models
Diffusion models are a class of generative models that create data by reversing a noise-adding process. Trained to model the stepwise addition and removal of noise, they can generate high-quality data such as images, audio, or even 3D structures. Diffusion models can be considered digital sculptors—they start with a block of noise and gradually "carve out" meaningful patterns.
Advantages:
- Produces photorealistic images and detailed data samples.
- Avoids common pitfalls of generative adversarial networks (GANs), like mode collapse.
- Suitable for various domains, including images, audio, and molecular generation.
Disadvantages:
- Requires significant resources for training and sampling due to multiple iterative steps.
- Generating outputs involves numerous steps, making it slower compared to other methods.
- Implementation and fine-tuning can be challenging for beginners.
Use cases:
- Image generation — Creating photorealistic images from noise or textual descriptions (DALL·E 2, Stable Diffusion).
- Text-to-image translation — Generating images based on text prompts for creative industries.
- Audio synthesis — Generating high-quality audio samples, such as speech or music.
- 3D model generation — Designing 3D objects or scenes for gaming, AR/VR, or design.
- Scientific applications — Modeling molecules, simulating physical processes, or generating data for research.

Key trends driving these CV algorithms popularity:
- These algorithms deliver state-of-the-art results while scaling across diverse industries.
- Many of these methods are optimized for speed and efficiency, essential for dynamic tasks like autonomous driving and AR.
- Lower data dependency. Algorithms like SimCLR and CLIP are minimizing the need for large labeled datasets, making AI more accessible.
- Their versatility allows adoption in healthcare, manufacturing, security, entertainment, and beyond.
- The rise of Edge AI and lightweight models addresses the need for computational efficiency in edge and mobile environments.
Provided algorithms are trending because they align with the key needs of 2025: adaptability, efficiency, and the ability to handle increasingly complex tasks.
To wrap up
Computer vision is no longer just about machines that see—it's about systems that understand, analyze, and interact with the world in transformative ways. In 2025, these algorithms are not just driving innovation but also shaping how businesses operate and scale.
While challenges like computational demands and data dependencies remain, the advancements in efficiency, adaptability, and scalability are paving the way for a smarter, more connected future.
From intelligent automation to AR/VR innovation, Mad Devs brings computer vision development services and machine learning solutions to help your business stay ahead. Let us tackle the complexities, so you can focus on growth.
Contact us today for a free consultation and bring the power of computer vision to your business.


Latest articles here




