


Analyze with AI
Get AI-powered insights from this Mad Devs article:
In the contemporary world, where information systems have become an integral part of our lives, the complexity of their intertwinement continues to grow exponentially. From financial operations to managing critical infrastructure — we rely on these systems across many crucial domains.
However, as the complexity of systems increases, so does the scale of potential threats, from hardware failures to cyberattacks. So a newer, more comprehensive approach to ensuring their reliability and security is needed. This is where chaos engineering comes into play.
What is chaos engineering?
Chaos engineering is a methodology designed to improve system reliability through the active induction of failures and abnormal scenarios. Instead of waiting for something to go wrong, chaos engineers deliberately "break" the system under controlled conditions to better understand its weaknesses and rectify them before they cause real issues.
Why is chaos engineering important for modern distributed systems
In modern distributed systems, where each component may be deployed across different geographical locations and on various types of infrastructure, managing reliability becomes an especially challenging task. Here are some specific reasons why chaos engineering is a key element in ensuring the reliability of such systems:
Detecting hidden dependencies. Distributed systems often have non-obvious interrelations and dependencies. Chaos engineering helps uncover them, preventing cascading failures that could lead to a system-wide breakdown.
Testing failure scenarios. In real-world operations, systems are subjected to various kinds of stresses and failures—from network issues to hardware malfunctions. Chaos engineering enables the simulation of these scenarios under controlled conditions.
Validating backup and recovery systems. Chaos experiments can be utilized to check the effectiveness of backup systems, and recovery plans post failures.
Evaluating monitoring system performance. If the monitoring system does not trigger during artificially induced failures, it's a signal that it won't be effective under real conditions.
Enhancing team readiness. Chaos engineering trains the team of developers and operators, teaching them to respond effectively to abnormal scenarios, which is critically important for minimizing downtime.
Resource optimization. Conducting chaos experiments can uncover redundant resources and allow for their optimization, leading to reduced operational costs.
Comprehensive assessment of SLA and SLO. Chaos engineering enables a practical check on how well the system adheres to the stated Service Level Agreements (SLA) and Service Level Objectives (SLO).
These aspects make chaos engineering not merely a tool for testing but a strategic asset for comprehensive management of the reliability and security of modern distributed systems.
Chaos engineering principles
In chaos engineering, principles are not merely recommendations; they constitute fundamental building blocks that ensure effectiveness and measurability. Let's delve deeper into these principles.
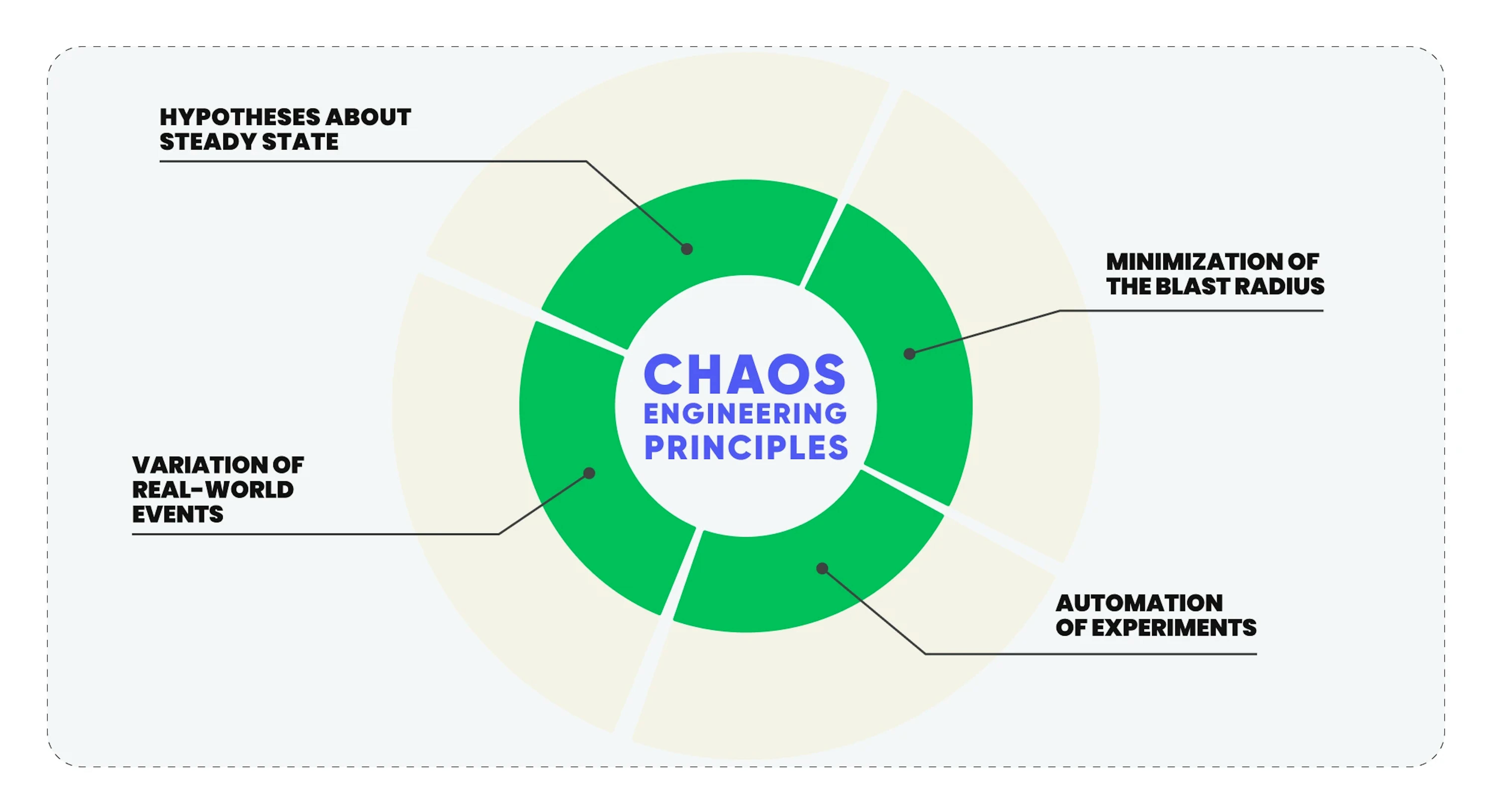
Hypotheses about steady state
Hypotheses regarding the steady state of a system are nothing but formalized expectations concerning the system's behavior under “normal” conditions. These hypotheses are grounded in specific metrics: server response time, the number of concurrent users, the percentage of successful transactions, and so forth. They serve as a starting point for experiments, allowing for comparing system behavior before and after introducing “chaos.”
Variation of real-world events
Variation of real-world events is a methodology where various types of failures or changes mimicking real conditions are introduced into the system. This can encompass everything from simulating a network device failure to creating artificial traffic spikes. The goal here is to ascertain how the system responds to unforeseen events and to identify weaknesses that might be overlooked with standard testing methods.
Minimization of the blast radius
Minimizing the blast radius reduces the potential negative impact of an experiment on the system and, ultimately, on the users. This is achieved through canary testing, phased rollouts, and other methods that allow confining the experiment to a smaller subset of the system. Thus, if something goes awry, the impact will be localized.
Automation of experiments
Automating experiments not only simplifies the process but also makes it more reliable and repeatable. This encompasses automatic selection of target components, failure injection, metrics monitoring, and data collection for analysis. Modern tools such as Gremlin or Chaos Monkey offer a broad spectrum of capabilities for automating these tasks.
These principles guide the practical application of chaos engineering and ensure that the methodology is applied in a structured, effective, and safe manner. It is essential for achieving the desired outcomes of enhanced system resilience and reliability. By following these principles, organizations can systematically explore, identify, and mitigate the weaknesses within their systems, enhancing their preparedness for real-world operational challenges.
Extended chaos engineering principles
Based on an in-depth analysis of distributed computing, L. Peter Deutsch and his colleagues at Sun Microsystems have identified additional principles that warn against common false assumptions engineers make about distributed systems:
The network is reliable. Network communication is always dependable and free from failures or data loss.
There is zero latency. There is no delay in data transmission over the network.
Bandwidth is infinite. The network has unlimited data transmission capacity.
The network is secure. The network is immune to security threats and vulnerabilities.
Topology never changes. The network structure remains constant over time.
There is one admin. A single administrator manages the entire system, leading to potential management and coordination issues.
Transport cost is zero. There are no costs (both in terms of time and resources) associated with data transmission over the network.
The network is homogeneous. All network segments operate under the same conditions and constraints.
These false assumptions are easily made, which creates the basis of the seemingly random problems arising from complex distributed systems. Understanding and accounting for these false assumptions help build more reliable and robust systems, aiming for a near-ideal mark of "five nines" (99.999%) availability instead of an unattainable 100% reliability.
Chaos engineering approach overview
Chaos engineering didn't emerge in a vacuum; its roots extend into system reliability research and scalability problem-solving. In the early 2010s, Netflix became one of the pioneers of this discipline. Facing growing demands for the availability and reliability of their services, Netflix developed the initial tools and methodologies for chaos engineering, including the well-known Chaos Monkey.
Since then, chaos engineering has undergone significant evolution and adaptation. Initially focused on cloud services and microservice architecture, this approach is now employed across various critical sectors, from fintech to healthcare. This has been made possible by the development of new tools and methodologies that enable the adaptation of chaos engineering principles to various types of systems and infrastructure.
With the growing popularity of chaos engineering, there's been a necessity for the formalization of this discipline. In recent years, guidelines from tech giants like IBM, Amazon, and Google have been published that assist organizations in systematically applying chaos engineering. This includes defining key metrics, methodologies, and best practices that ensure effective and safe experimentation.
Chaos engineering has also found its place in broader DevOps and Site Reliability Engineering (SRE) practices. In these contexts, chaos engineering is utilized for automated reliability and resilience testing of systems at various stages of the development lifecycle.
Overall, the evolution of chaos engineering depicts its progression from a niche tool for cloud services into a universal methodology for ensuring the reliability of large and complex systems.
Systems theory and probability theory in chaos engineering
It's important to note that despite its relatively recent transition from a niche tool to a universal methodology, chaos engineering has always had a solid and stringent scientific foundation, primarily consolidated in the following elements.
The systems theory role
Systems theory is one of the fundamental elements of chaos engineering. It provides a conceptual framework for understanding complex, interrelated components in distributed systems. In this context, systems theory aids engineers in comprehending how alterations in one part of the system can trigger cascading reactions affecting the entire system. This is especially crucial when analyzing failures and their repercussions, as well as when designing experiments to identify potential vulnerabilities.
The probability theory role
Probability theory introduces a quantitative element to chaos engineering. It enables engineers to model various failure scenarios and assess their likely repercussions. This includes utilizing statistical methods to analyze data collected during experiments and applying this data to identify the most probable failure points within the system.
The interplay between systems theory and probability theory
Systems and probability theory don't operate in isolation; their interaction creates a unique dynamic in chaos engineering. Systems theory helps identify which system elements should be explored, while probability theory provides the tools for a quantitative assessment of risks and repercussions. Together, they form a methodological foundation for designing and conducting experiments that not only reveal system weaknesses but also provide quantitative metrics for their evaluation.
What is chaos testing
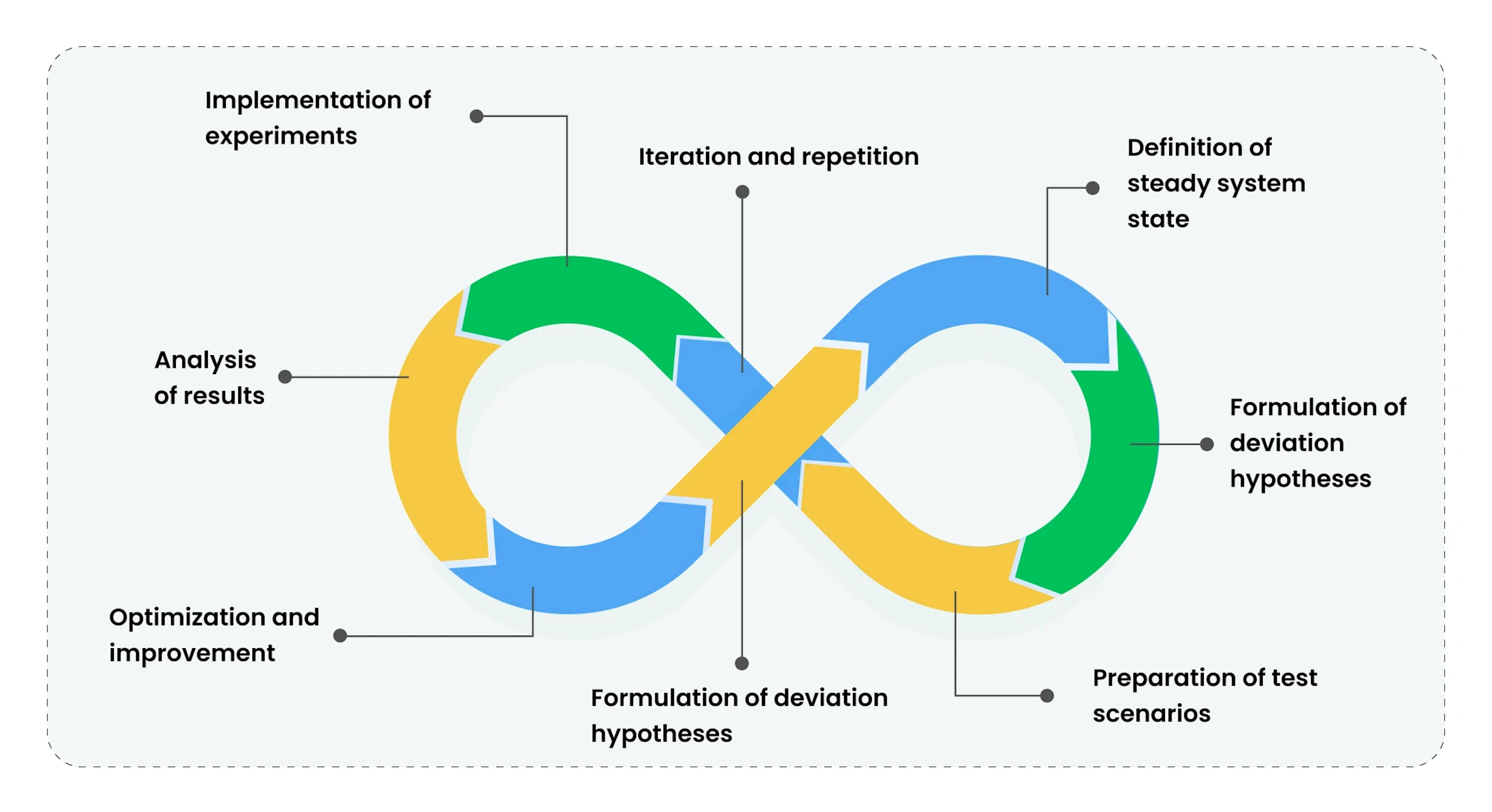
Definition of steady system state
Before commencing any experiment, it is crucial to determine what is considered a "steady" state of the system, through the selection of specific metrics, such as response time, error rate, and throughput. These metrics serve as the baseline for all subsequent measurements and comparisons.
Additionally, at this stage, threshold values for each metric are established to understand when the system begins to “falter.” These threshold values can be set based on historical data or through consultations with the development team and business analysts.
For instance, if the average response time is 200 milliseconds typically, a threshold value may be set at 250 milliseconds. If the response time exceeds this threshold, it will be considered a deviation from the steady state.
Formulation of deviation hypotheses
At this stage, the team develops hypotheses regarding possible deviations of the system from the steady state under various conditions. These hypotheses are based on historical data, the team's knowledge of the system, and an analysis of potential failure points. By analyzing previous system performance data, the team can predict how changing certain parameters will affect the system.
A scenario may include increasing traffic, leading to higher load on some system components and increasing the response time to 300 milliseconds. The team will then need to determine which system components require optimization to return to a steady state.
Implementation of experiments
During the experiment implementation stage, the team commences the execution of prepared test scenarios to identify possible system weak points. Experiments are conducted in a controlled environment to minimize risks and ensure result accuracy. It is crucial to meticulously monitor the system behavior during each experiment to notice deviations and problems promptly. The team can also adjust experiment parameters in real time for more precise hypothesis testing. The stage concludes with an assessment of how closely the experiment results align with the initial hypotheses.
Increasing the load on one of the components indeed led to an increase in response time to 350 milliseconds, indicating the need for optimizing that particular component.
Analysis of results
After conducting the experiments, the team transitioned to analyzing the obtained results. This stage involves comparing experiment data with initial hypotheses and determining to what extent the system meets expectations. This encompasses analyzing known and understandable aspects, studying partially understood elements, identifying non-obvious yet understandable characteristics, and addressing areas that remain unexplored and incomprehensible. It is crucial to document all findings and discuss them with the team for planning further steps.
Analysis reveals that a microservice's increased load leads to an unacceptable response time increase due to insufficient throughput in another microservice, necessitating further optimization.
Optimization and improvement
Based on the result analysis, the team embarks on optimizing and improving the system. This may involve changing the system architecture, enhancing the code, or increasing resources. All changes should be thoroughly tested to ensure their effectiveness and the absence of negative impact on other system aspects. This stage may require several iterations to achieve the desired results.
Optimizing request processing algorithms can reduce the average response time to 200 milliseconds, even under increased load.
Iteration and repetition
Part of the chaos testing process is an iterative approach that allows for the continuous improvement of system resilience. After each optimization and improvement cycle, the team reverts to the hypothesis formulation stage for conducting new experiments and further improving the system. This ensures that the system still meets all requirements and is ready for operation under changing conditions.
After optimizing the response time, the team formulates new hypotheses regarding the system behavior under an even larger traffic increase and plans new experiments to test these hypotheses.
What is the difference between software testing and chaos testing
It may not be immediately apparent how chaos testing differs from traditional software testing. However, there are several distinct differences, both conceptual and technical, between chaos testing and traditional testing.

| SOFTWARE TESTING | CHAOS TESTING | |
|---|---|---|
| Testing environment | Often conducted in isolated or staging environments, which helps provide more controlled conditions and avoid risks to real users and data. | Typically conducted in a real production environment to more accurately model real-world operating conditions and unpredictable failures. |
| Testing objective | Focuses on verifying specific functions or components of the system against pre-defined requirements and standards. | The objective is to identify obscure weaknesses in the system that may only manifest during unforeseen failures or high-load conditions. |
| Types of failures | Focuses on expected and known usage scenarios and errors to verify how the system behaves under normal or predictable conditions. | Simulates real-world failures such as network outages, high load, and hardware failures to see how the system reacts to these changes. |
| Automation | Can be either automated or manual but usually does not include automatic fault injection. | Often include automatic fault injection into the system to simulate real-world operating conditions, helping to create more realistic testing scenarios. |
| Metrics and analysis | Focuses on functional metrics such as the performance of individual components and the correctness of functions. | Focuses on system metrics such as response time, availability, and resilience to assess the overall performance and reliability of the system. |
| Blast radius | Conducted in an isolated environment usually does not affect real users. | Conducted with minimizing impact on real users in mind, including utilizing rollback strategies and real-time monitoring. |
| Development stage | Can be conducted at any stage of development to ensure compliance with requirements and standards at each stage of the process. | Usually conducted at later stages of development or even after the system launches to ensure it can withstand real-world operating conditions. |
Who is chaos engineering for?
Generally speaking, chaos engineering is a good fit for any company with digital assets, as it takes the stability and availability of their operations to a new level. More specifically, chaos engineering is essential for large companies, where any disruption to operations can cause huge financial losses, and for organizations that provide critical infrastructures and where operation disruption can lead to even worse threats than any monetary defaults.
Let's take a closer look at the main examples:
Cloud services
In cloud services, where most enterprises build their infrastructure on remote servers, any instability or service failure can have a cascading effect, impact the business operations of millions of companies, and result in billions of dollars in losses within minutes. Chaos engineering helps ensure the high availability and reliability of cloud resources by simulating failures in cloud infrastructure, testing auto-scaling, and maintaining performance under high loads.
Streaming platforms
For streaming platforms, competition for user attention is intense, and the reliability and quality of content delivery become key factors for success. Issues such as streaming interruptions or service unavailability can lead not only to customer loss but also to a loss of audience trust. Chaos engineering here aims to ensure stability during periods of high user activity and prevent issues that could impact reputation and competitiveness. This is achieved through stability and reliability testing of systems during mass simultaneous connections and the ability to adapt during peak activity periods.
Financial institutions and services
In the financial industry, where every transaction matters and reliability is a key factor, chaos engineering becomes an indispensable tool for ensuring the stability of financial systems. Problems such as transaction processing delays or failures in banking services not only affect customer satisfaction but can also result in significant economic losses and even threaten financial stability on both enterprise and national levels. The primary goal of chaos engineering here is to ensure the continuous operation of financial transactions and protect customer information by testing the response of financial systems to network failures, fake transactions, and other potential threats.
Medical information systems
Any issues in medical information systems can have serious consequences for the diagnosis and treatment of patients if medical data becomes unavailable or experiences processing failures. Confidentiality, integrity, and data availability are paramount, and chaos engineering plays a crucial role in ensuring the stability and security of these systems. It allows testing systems for resilience to failure recovery after data loss and provides high security for critical medical data.
Telecommunication providers
Communication is integral to everyday life and critical in emergencies, so any network issue can have far-reaching consequences. Communication reliability is not just a matter of convenience but also a question of safety, with incidents potentially affecting individuals and entire societies. Chaos engineering here aims not only to prevent failures but also to ensure the stability and continuity of communication by testing the network's response to emergencies such as network traffic overload or failures in specific nodes and other scenarios.
Urban infrastructures
In urban infrastructures, where the effective functioning of transport, energy, and communal systems is crucial for the lives and comfort of citizens, chaos engineering becomes an essential element in ensuring stability and safety. The goal of chaos engineering in this area is to detect and prevent potential failures and situations that could impact the lives of city residents. The software identifies vulnerabilities by simulating loads on traffic control systems, energy, water supply, and other urban infrastructures.
Logistics platforms
In the logistics industry, where effective tracking and management of goods are key components of successful operations, issues in these systems can lead to delays, loss of goods, disruptions in supply chain integrity, and even ecological disasters. Chaos engineering becomes an important tool in ensuring continuity, stability, and efficient operation of logistics platforms by testing tracking systems under high loads, changes in routes and the status of goods, among other scenarios.
Government institutions and services
Digital government resources are the primary channels for citizen interaction, and problems with the availability of digital government portals or failures in its services can significantly impact citizens' lives. Chaos engineering here ensures the stability and reliability of government information systems by simulating attacks, attempting to edit information, and creating high loads.
Сhaos engineering tools
Today, several solutions for chaos engineering provide a wide range of tools and implement a set of principles and practices we discussed earlier. Most of them are open source, can be used mostly for free, and often overlap in functionality. However, they all have some unique features, which we will discuss below.
Chaos engineering tools for AWS, Azure, and APIs of various cloud providers
Focus on the specific features and services of cloud providers. Optimized for cloud environments.

Chaos Monkey is a resilience enhancement tool developed by Netflix for testing its tech infrastructure by randomly terminating virtual machines and containers in a production environment.
Key features:
- Random termination of virtual machines and containers.
- Integration with the continuous delivery platform Spinnaker.
- Support for various backends supported by Spinnaker (AWS, Google Compute Engine, Azure, Kubernetes, Cloud Foundry).
Advantages:
- Encourages engineers to build resilient services through frequent interaction with failures.
- Supports multiple platforms and cloud providers.
Disadvantages:
- Requires Spinnaker for deployment management.
- Requires MySQL version 5.X.
- Limited failure mode: injection of only one type of failure.
- Lack of coordination and recovery capabilities.
- No user interface.
- Limited auxiliary tools for audit, shutdown verification, and tracking job completion.
Price: Free (open source)
G2 Rating: N/A
TrustRadius Rating: N/A

Gremlin is a chaos engineering platform that assists SRE teams and platforms in improving uptime, verifying system reliability, and building a reliability culture. This is achieved through the meticulous injection of failures into services, hosts, containers, and serverless workloads, as well as replicating real incidents through sequential execution of chaos engineering experiments.
Key features:
- Supports various cloud environments, including AWS, Azure, and GCP.
- Failure injection into services, hosts, containers, and serverless workloads.
- Experiment library to see how systems respond to different common failure conditions.
- Execution of multiple chaos engineering experiments sequentially to mimic real incidents.
- Toolset library for creating different failure conditions, including CPU, memory, disk, network issues, and more.
- Functionality for organizing effective GameDays.
Advantages:
- Ease of use and safety.
- Automatic analysis and result storage.
Disadvantages:
Price. Gremlin is a paid platform, which may be a barrier for some users or small teams.
Price: On-premises
G2 Rating: 4.5 stars
TrustRadius Rating: N/A
Tools for multiple platforms
Versatile tools that can be applied across multiple environments — cloud, on-premises, virtual machines, and even at the individual application level.

The Chaos Toolkit is a tool for creating custom tools and chaos engineering experiments. It supports the full life cycle of experiments, allowing for verifications (referred to as probes) at the beginning of the experiment, performing actions to induce system instability, and verifying the achievement of the expected end state.
Key features:
- Focus on extensibility for creating custom chaos tools.
- Support for the full life cycle of experiments.
- Ability to install existing extension packages such as AWS Driver or Kubernetes Driver.
- Open Chaos Initiative for standardizing chaos engineering experiments through Chaos Toolkit Open API specifications.
Advantages:
- Extensibility for creating custom tools and experiments.
- Support for multiple platforms through the installation of additional drivers.
- Initiative for standardizing chaos engineering experiments.
Disadvantages:
It may necessitate custom coding or additional tooling for advanced or specific chaos experimentation scenarios not covered by the standard suite of experiments.
Price: Not specified (open source)
G2 Rating: N/A
TrustRadius Rating: N/A
Chaos engineering tools for Docker and Kubernetes
Specialized tools for testing and monitoring containerized applications and their orchestration.

LitmusChaos is an open-source chaos engineering tool designed with developers' and SREs' needs in mind, enabling chaos experimentation at the application and infrastructure levels across various CI/CD stages.
Key features:
- An extensive set of chaos experiments at both infrastructure and application levels.
- Integration with popular CI/CD platforms such as Jenkins, GitLab, and others.
- Support for cloud and on-premises environments, including Kubernetes.
- Chaos experiments with minimal time investment.
- Various chaos experiments can be ordered sequentially or parallelly to create chaos scenarios.
- Verification of stable hypothesis states using Litmus probes.
- Export of Prometheus metrics for real-time chaos impact analysis.
- Support for multi-user environments in Kubernetes through namespaces.
Advantages:
- Broad possibilities for expansion and integration with other tools.
- An active community is contributing to platform development and adding new features.
- Ability to create custom experiments and drivers.
Disadvantages:
- Initial setup and familiarization may take time.
- Lack of some management and monitoring features compared to commercial counterparts.
Price: Free (open source)
G2 Rating: 4.5
TrustRadius Rating: N/A

PowerfulSeal is a standalone chaos engineering tool that automates the process of failure injection at both infrastructure and application levels using policies to define and launch failure scenarios.
Key features:
- Failure injection at the infrastructure and application level.
- Autonomous operation without the need for integration with external systems.
- Policy-based failure scenarios.
Advantages:
- Ease of use and setup.
- Ability to create custom failure scenarios.
- Disadvantages:
- A limited basic set of built-in failure scenarios.
Price: Free (open source)
G2 Rating: N/A
TrustRadius Rating: N/A

Chaos Mesh is a chaos engineering platform for Kubernetes, offering various types of failure simulation and failure scenario orchestration, with a focus on simplifying experimentation in production environments without altering application deployment logic.
Key features:
- Integration with Kubernetes through CustomResourceDefinition (CRD).
- Easily deployed on Kubernetes clusters without special dependencies.
- Provides multiple filtering rules for injection target selection.
- Supports failure injection for networks, disks, file systems, operating systems, etc.
- Orchestration of complex failure scenarios using workflows.
Advantages:
- Ability to conduct chaos experiments in production environments without changing the application deployment logic.
- Quick creation of chaos experiments through a control panel, allowing users to observe the experiment status in real time and rapidly roll back injected failures.
Disadvantages:
It may not distinguish the production environment from others, which can cause issues without appropriate precautions.
Price: Not specified (open source)
G2 Rating: N/A
TrustRadius Rating: N/A

Pumba is a resilience testing tool aimed at simulating random failures of Docker containers. The core idea is to "randomly" kill, stop, and delete running containers, thereby testing the system's ability to recover from such failures.
Key features:
- Container-level failure simulation: killing, stopping, and deleting containers.
- Network failure emulation: delay, packet loss, bandwidth limitation, etc.
- Ability to select containers for failure simulation using regular expressions or specifying particular container names.
Advantages:
- Opportunity to conduct tests in real production environment conditions.
- Ability to introduce failures manually or automatically based on set parameters.
Disadvantages:
Lack of built-in monitoring and reporting mechanisms, requiring integration with existing monitoring infrastructure.
Price: Not specified (open source)
G2 Rating: N/A
TrustRadius Rating: N/A
Chaos engineering best practices
Chaos engineering is a complex approach. Thus, it requires strict adherence to all its principles not only to reap its benefits but also to avoid harming the system. For the same reason, certain practices also make its use more effective and safe. Here are some of them:
Integration of chaos engineering in DevOps pipelines
Integrating chaos engineering into DevOps pipelines allows development teams to automatically conduct resilience and fault-tolerance tests at various stages of development. This helps to identify and rectify potential weak spots in the system at the early stages of development, in turn reducing the time and resources needed to fix issues post-product launch. Implementing chaos experiments in the CI/CD pipeline also fosters a culture of continuous improvement and learning, as teams can immediately see the impact of code changes on the overall stability of the system.
Utilization of "Game Days"
The practice of "Game Days" entails regular sessions where the team gathers to conduct and analyze chaos experiments in a controlled environment. This creates a safe setting for testing and improving the system, as well as for staff training. Each session offers unique learning opportunities and improves the team's incident response skills, which in the long term contribute to creating more resilient and reliable systems.
Scenarios based on real events
Creating scenarios based on real incidents involves detailed analysis of past failures and errors, enabling more accurate recreation of problematic situations. This may include logs, metrics, and error reports analysis to understand which system components were involved and what conditions led to the failure. Subsequently, scenarios that mimic these conditions, including sudden server shut-offs, network packet loss, or unexpected changes in input data, are developed. Implementing such scenarios in a controlled environment allows the team to better understand how the system reacts to real failures and develop the most practical strategies.
Continuous calibration and adaptation
Continuous calibration and adaptation of experiments are vital to ensure their relevance in a changing technological landscape. This may involve regularly updating testing scenarios and adapting parameters and metrics to account for new system features or infrastructure changes. Calibration may also include analyzing previous experiment results to improve the design of future experiments and enhance testing methodologies. This helps ensure rapid and efficient service recovery, minimizing the impact on users and businesses. It also provides an opportunity to continuously improve recovery plans based on feedback from chaos experiments.
Integration with recovery plans
Integrating chaos experiments with recovery plans implies that experiments are designed considering existing recovery procedures. This may involve aligning testing scenarios with incident recovery teams to ensure that experiments do not conflict with recovery procedures and that experiment results are utilized to improve these procedures. It also may include staff training to ensure that teams are ready to respond to experiment results and can swiftly restore the system post-failures.
Training and simulations for staff
Training and simulations are an essential part of mastering chaos engineering. They help staff better understand how the system reacts to different types of failures and what steps are needed to restore normal operations. Regular training helps improve incident response skills and enhance post-failure recovery procedures. Through simulations, staff can practice problem-solving in a controlled setting, which aids in improving their skills and confidence. Conducting simulations based on real chaos testing scenarios helps team members better understand the challenges that may arise under real conditions and how to effectively deal with them.
Pre-launch checklist
The pre-launch checklist for a chaos engineering experiment ensures that all necessary steps have been taken to minimize risks. This includes checking configurations, ensuring the availability of all required monitoring tools, and readiness of the team for potential incidents. The checklist may outline steps for preparing the infrastructure, validating experiment parameters, and recovery procedures in case of failures. It's also important to ensure that all team members understand the experiment objectives and potential risks. Meticulous preparation and adherence to all checklist items help ensure successful experiment conduct and achievement of set objectives.
These additional practices will help enhance the use of the chaos engineering approach for your organization and help consistently ensure your infrastructure's reliability and resilience.
Summary
Chaos engineering is much more than just one type of testing. It has evolved from a narrow solution for cloud solutions into a separate discipline capable of testing the resilience of systems at the most thorough level under a wide variety of scenarios.
Now you know that it is an entire methodology with its own set of core and extended principles, practices, and tools that provide resilience testing beyond standard service and functional quality testing.
Mastering and applying all of this requires a lot of attention to get the most out of it and, more importantly, not to damage your system or interrupt your business processes on which your organization's success depends.
We, at Mad Devs, always make transparency, continuity, and process efficiency a key focus, and if you need help implementing solutions without compromising your processes, contact our experts for a free consultation. We will carefully examine your case and propose the most proven and beneficial solution for your organization.


FAQ
What is chaos engineering?
What are the principles of chaos engineering?
Why is chaos engineering important?
How is chaos engineering performed?
What are some best practices in chaos engineering?
Latest articles here




