


Analyze with AI
Get AI-powered insights from this Mad Devs article:
"If you can't measure it, you can't manage it"
Metrics are essential for a successful company. As a metric, we understand a set of measures used for assessing and comparing a company's performance. They are usually used to build a dashboard that's regularly reviewed by management or analysts.
There are several uses where a good metrics program is almost crucial:
- Problem analysis – metrics help identify the reasons why your company is failing to meet its ultimate business goal.
- Process improvement – metrics show what is working and what is not working and need adjustments.
- Recognition – metrics identify the processes and employees that are truly impacting high performance.
- Goal settings – metrics process have an impact on specific goal settings, key performance indicators, and milestones;
- Budgeting – metrics can be used to justify continuing or increasing funding.
- Trend development – good for developing trends that influence the dynamics of a company's process.
Many metrics are located in different systems, databases, and records. So, how to determine, collect, and monitor them? This article aims to explore the capabilities of Apache NiFi as a means of implementing a metrics collection system.

Tool overview
Apache NiFi (hereinafter "NiFi") is a system that implements ETL (Extract, Transform, Load) processes. The system is distributed under the shareware Apache 2.0 license (owned by the Apache Software Foundation). The system allows collecting data from various sources, transforming it "on the fly" and sending it to the receiving system. The system has a wide range of integration capabilities. The source/recipient of data can be:
- Systems with an HTTP interface, including REST API, gRPC, and WebSocket
- Queue managers: RabbitMQ, Apache Kafka
- Document-oriented systems: MongoDB, Cassandra
- Relational DBMS: MySQL, PostgreSQL, SQL Server, Oracle, and others, if there is an appropriate driver
- External utilities
To describe the processes, NiFi offers a web-based designer interface that allows describing the process of receiving, transforming, and sending data in the form of blocks and links between them. Accordingly, NiFi implements the FBP concept. The interface looks like this:
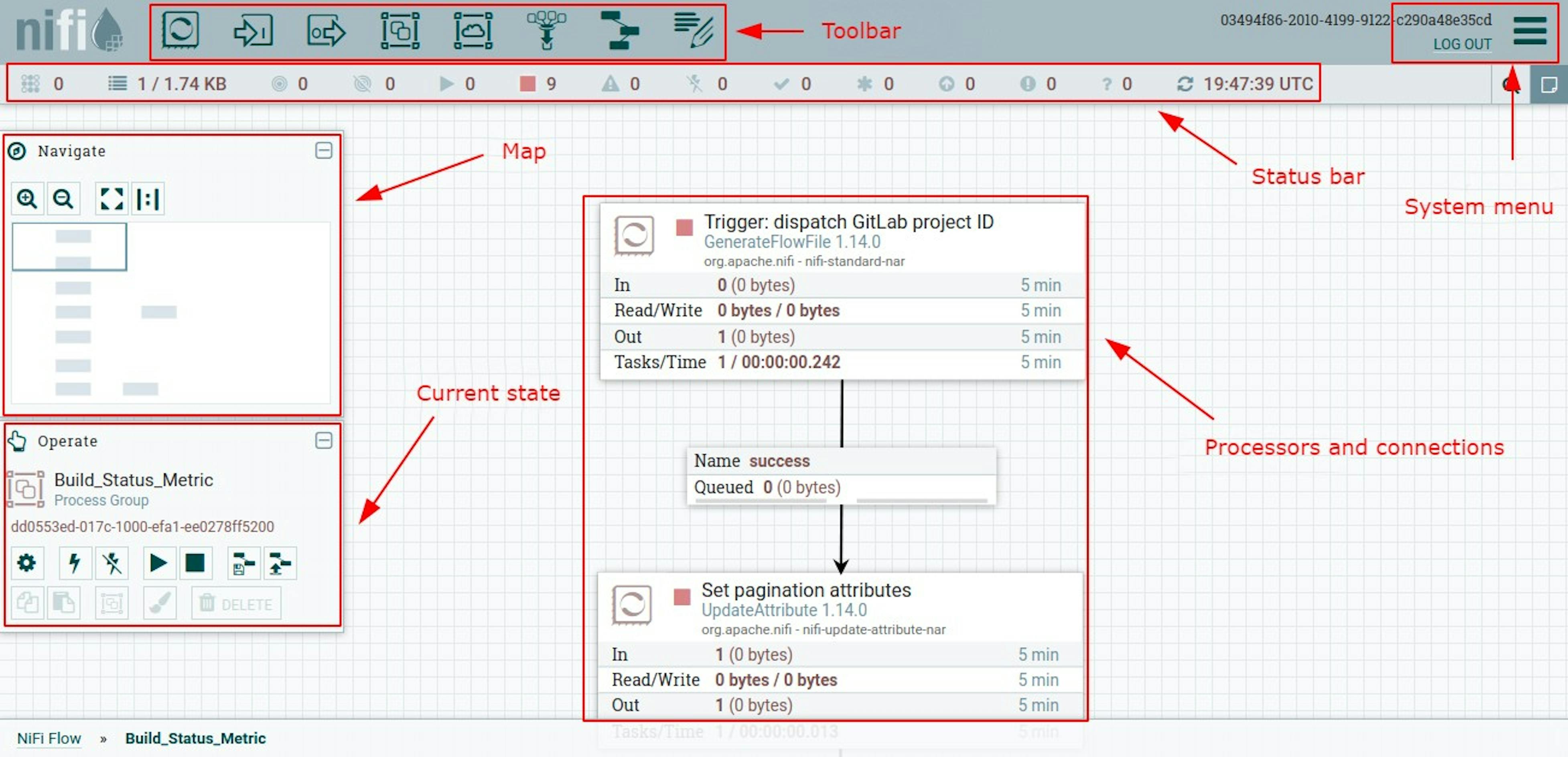
To describe the processes NiFi proposes to use, the following components:
1. FlowFile – a data packet capable of containing content and metadata in the form of attributes.
2. Processor – a handler capable of generating, redirecting, converting stream files, or performing other actions. The current version at the time of this writing contained 288 types of handlers. It is worth noting the following separately:
- It is possible to run external utilities for processing.
- It is possible to create programmable processors using Python, Lua, ECMAScript, Clojure, Groovy, and Ruby.
- It is possible to implement proprietary processors in Java.
You can read about this in the article Custom Processors for Apache NiFi on Bryan Bende's website and the article Creating Custom Processors and Controllers in Apache NiFi on Medium.
3. Connection – transferring stream files between processors.
4. Process group – a group of processors that form a single process.
5. Input port / Output port – to delegate data input between different project teams.
Each block of the process group, like the process groups themselves, can be stopped and started, thus controlling the work process. The installation type is "on-premise" and supports clustering (using Apache ZooKeeper) for fault tolerance and horizontal scalability. Change versioning is supported using the Apache NiFi Registry. Thus, it is possible to save and rollback process description models in NiFi.
Practical task
As part of the development of a metrics collection system, the Mad Devs team was tasked with integrating with different systems: Jira, GitLab, and SonarQube. Each of them has a REST-based HTTP interface. For Jira, there is already an article "Automating Jira Analytics with Apache NiFi," so we decided to consider integration with GitLab on a publicly accessible repository. For a practical task, the following requirements were determined:
- Get pipeline data
- Remove redundant data from packets
- Send the data to the receiving system (in the subsequent stages, it will be replaced by a bunch of PostgreSQL and Grafana)
Implementation of a practical task
Conventions
To interact with GitLab, we will take as a basis GitLab Pipelines API v4 and the current Apache NiFi 1.14.0 version in the form of a Docker container. We will use "AutowareAuto" as a publicly available GitLab project.
Installation
Installation and launch:
The system will be available at localhost:8443/nifi (it may take about a couple of minutes for the container to fully start) and will ask for authorization.
Login and password are generated when the system is first started. To find them out, run the following command:
Once in the container shell, run grep on the 'Generated' phrase on the logs/nifi-app.log file:
We get:
To exit the shell, execute the command:
We enter the data without brackets when requesting authorization at the local address localhost:8443/nifi/login.
Process description
The first step is to add a new process group and name it "Build Status Metric":
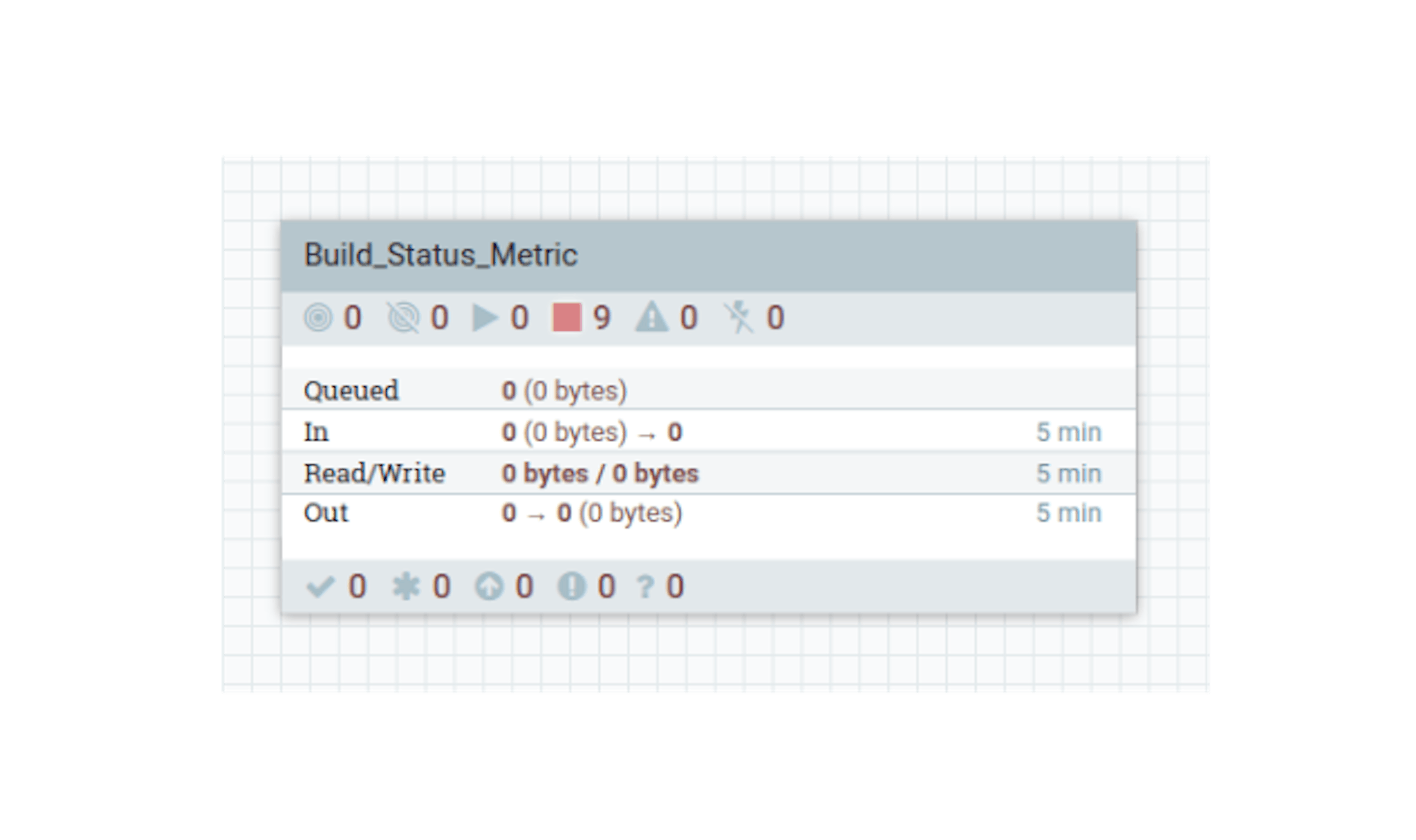
Double-click on the process group to switch to its local context. To access the GitLab API Pipelines, we need to generate the following URL:
Where:
- PROJECT_ID – identifier of the GitLab project;
- CURRENT_PAGE – current page (default 1);
- PER_PAGE – number of items per page (default 20).
In order to start a process in NiFi, an initiating trigger must be defined. For this, the "GenerateFlowFile" processor is suitable, which generates a stream file on a timer. Let's place the "GenerateFlowFile" processor and define its following properties:
- Name "Trigger: dispatch GitLab project ID."
- Scheduled start "60 seconds" - can be adjusted arbitrarily so that stream files are not generated too often.
- In the properties, add the attribute "PROJECT_ID" with the value "8229519" (ID of the selected GitLab project).
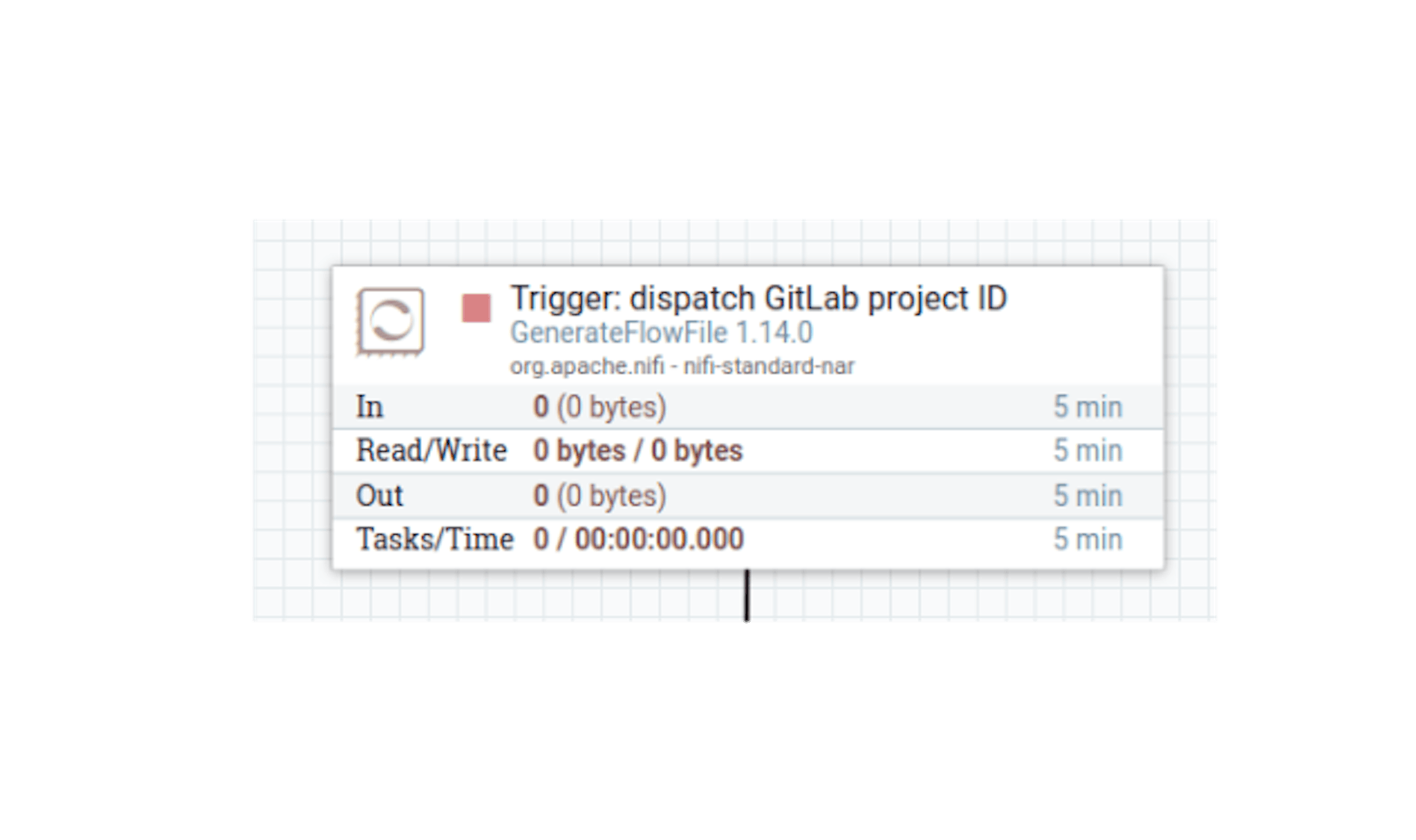
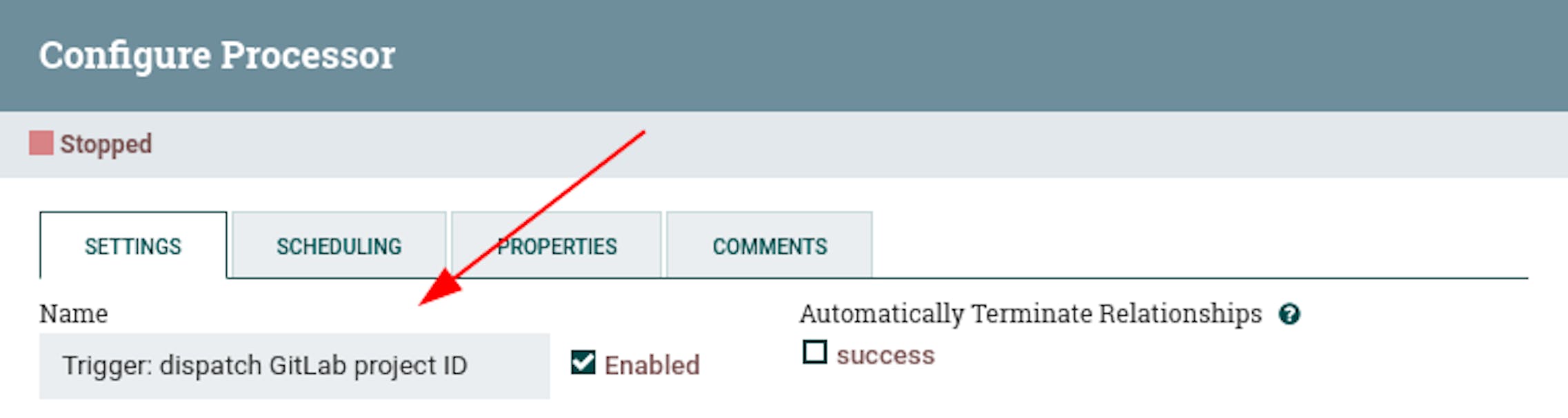
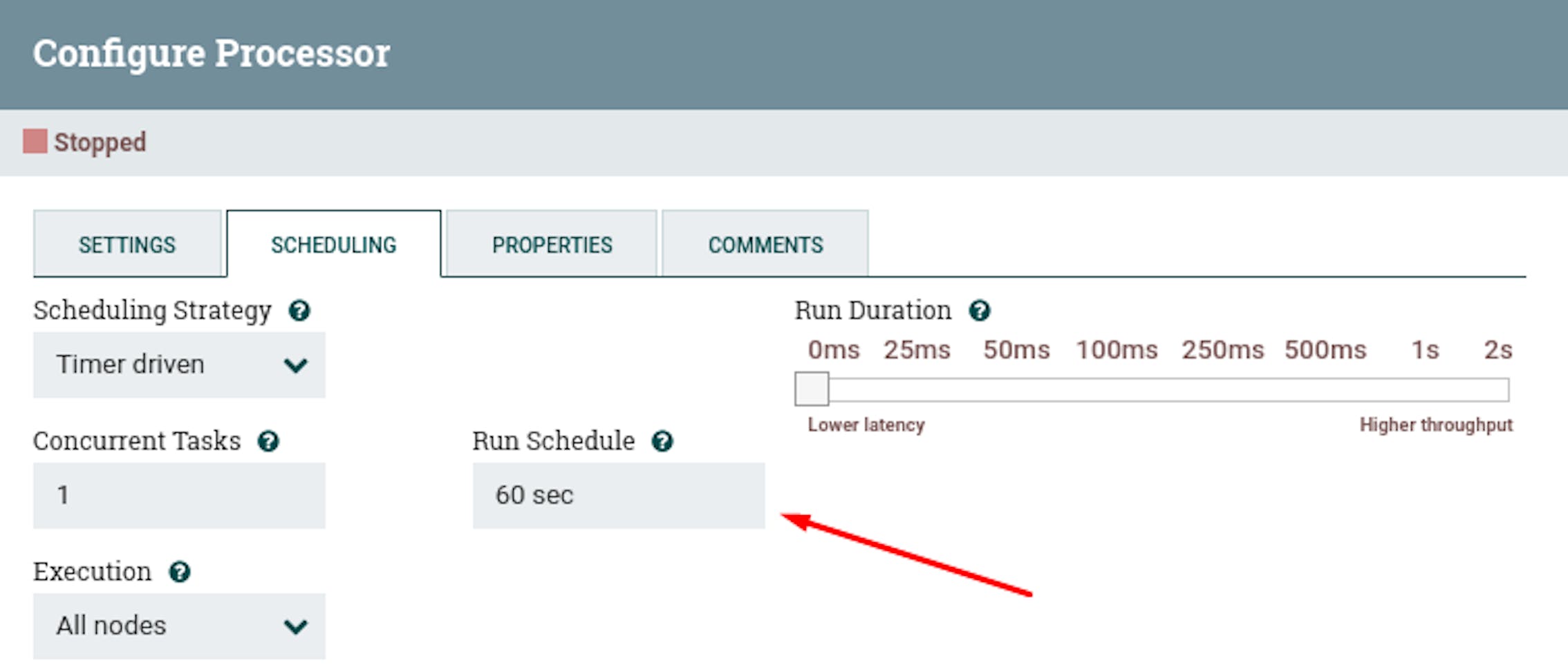
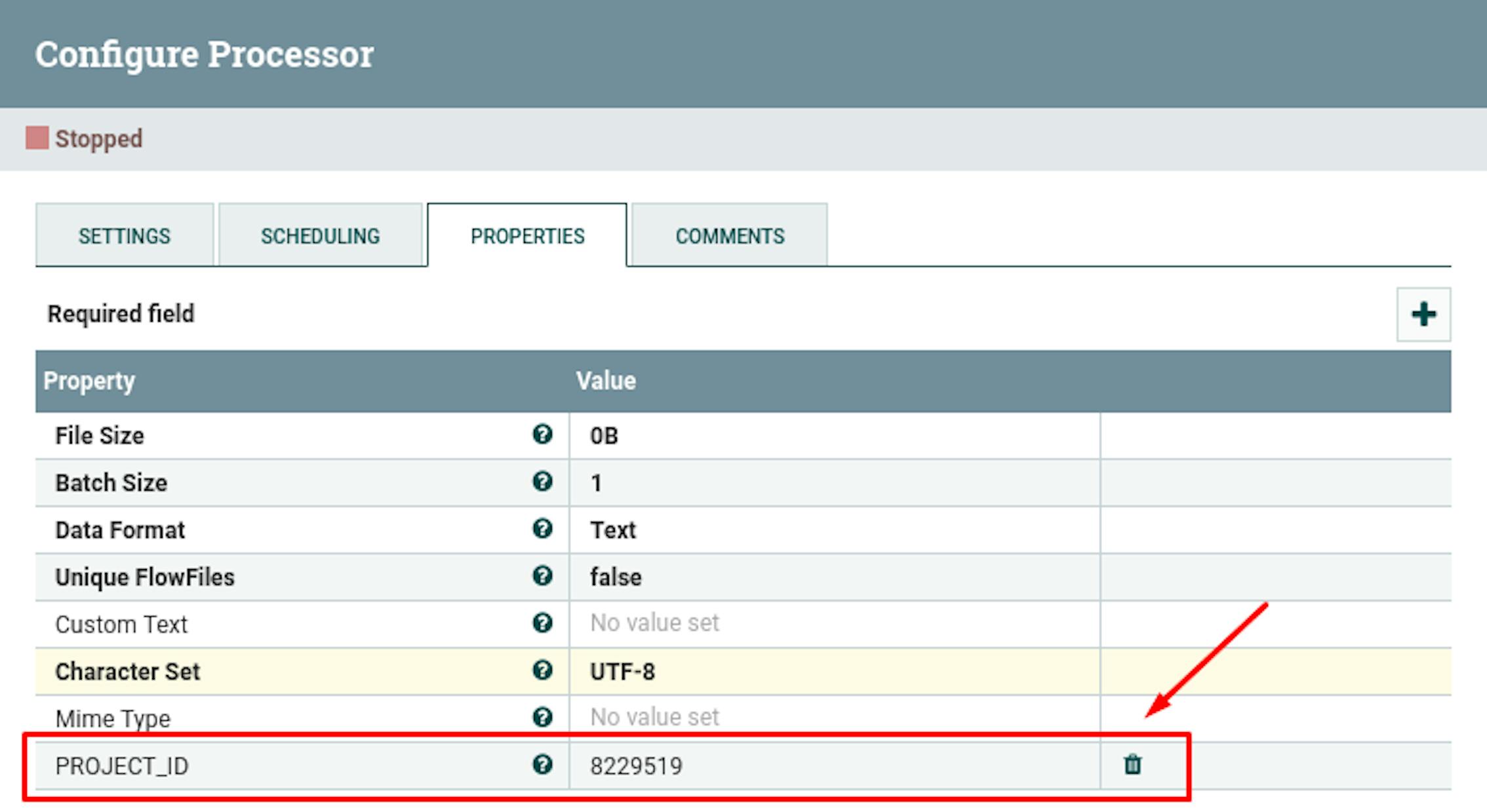
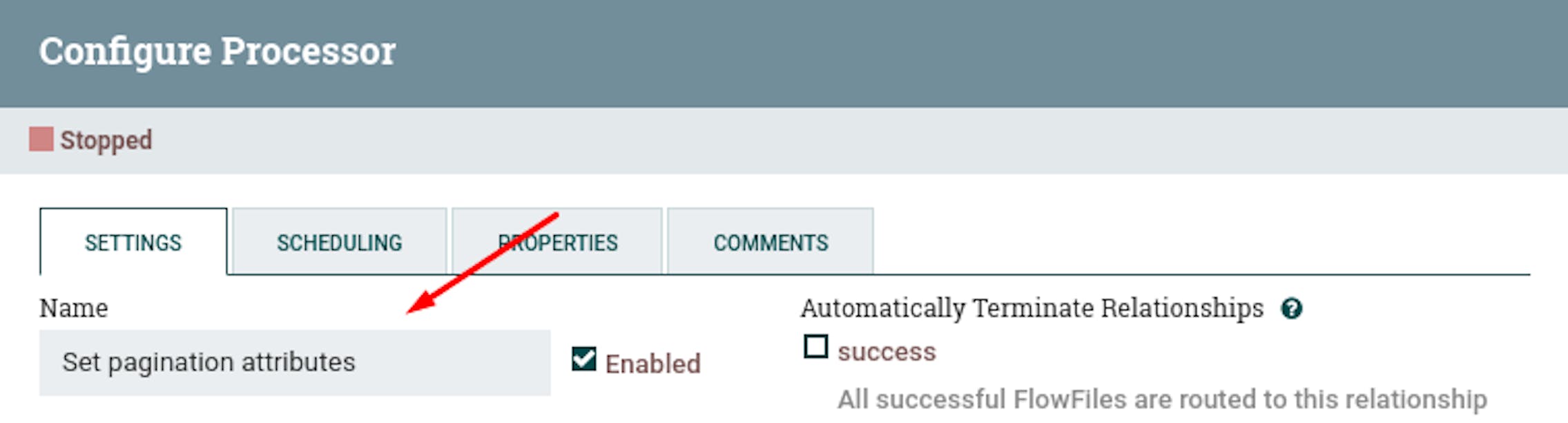
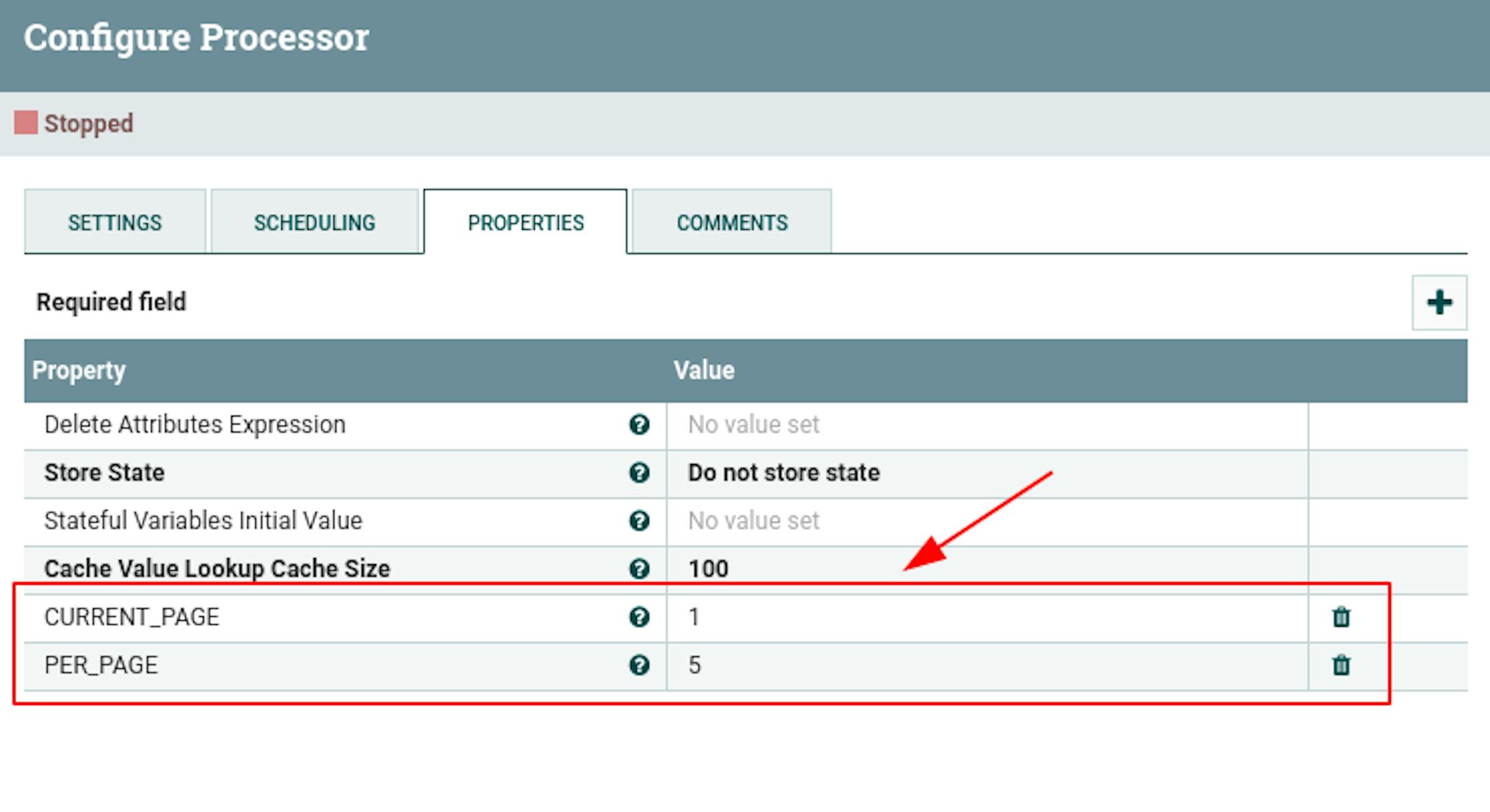
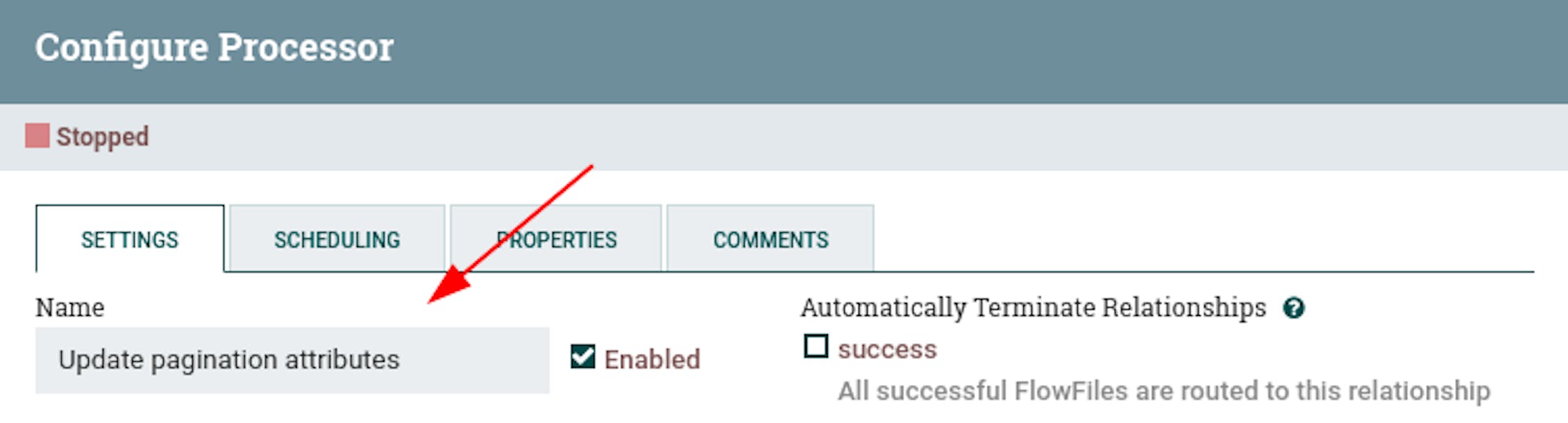
We have defined an initiating trigger that generates a stream file with the project ID as a metadata attribute. Let's add a processor that additionally sets pagination attributes, since it is not possible to get all the data in one request. To do this, place the "UpdateAttribute" processor and define the following settings for it:
- Name "Set pagination attributes".
- Add the following attributes to the properties:
"CURRENT_PAGE" with value "1" (start page).
"PER_PAGE" with value "5" (arbitrary number of elements per page).
Let's connect the processors with the "success" link (stretching the arrow icon from the first to the second, respectively):
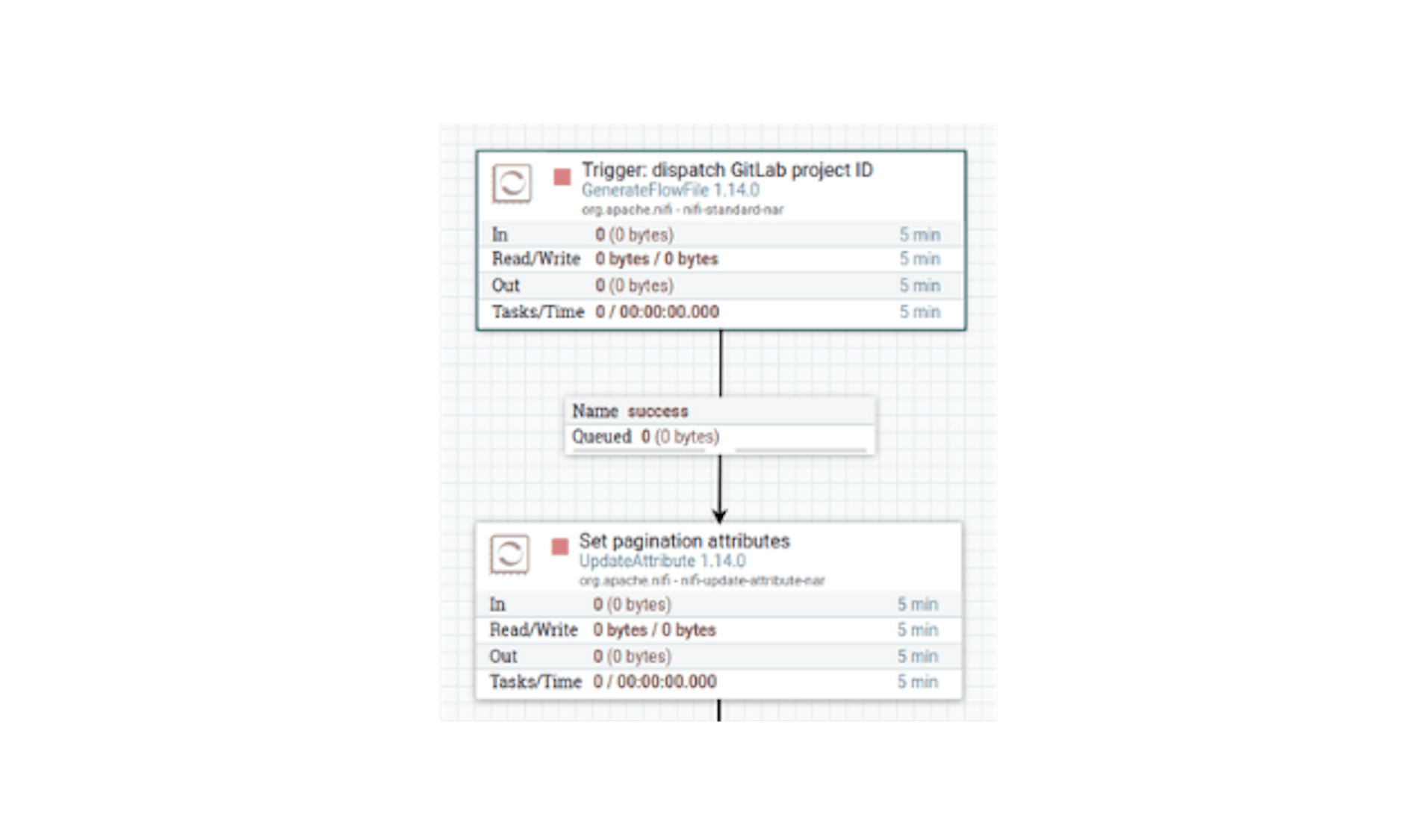
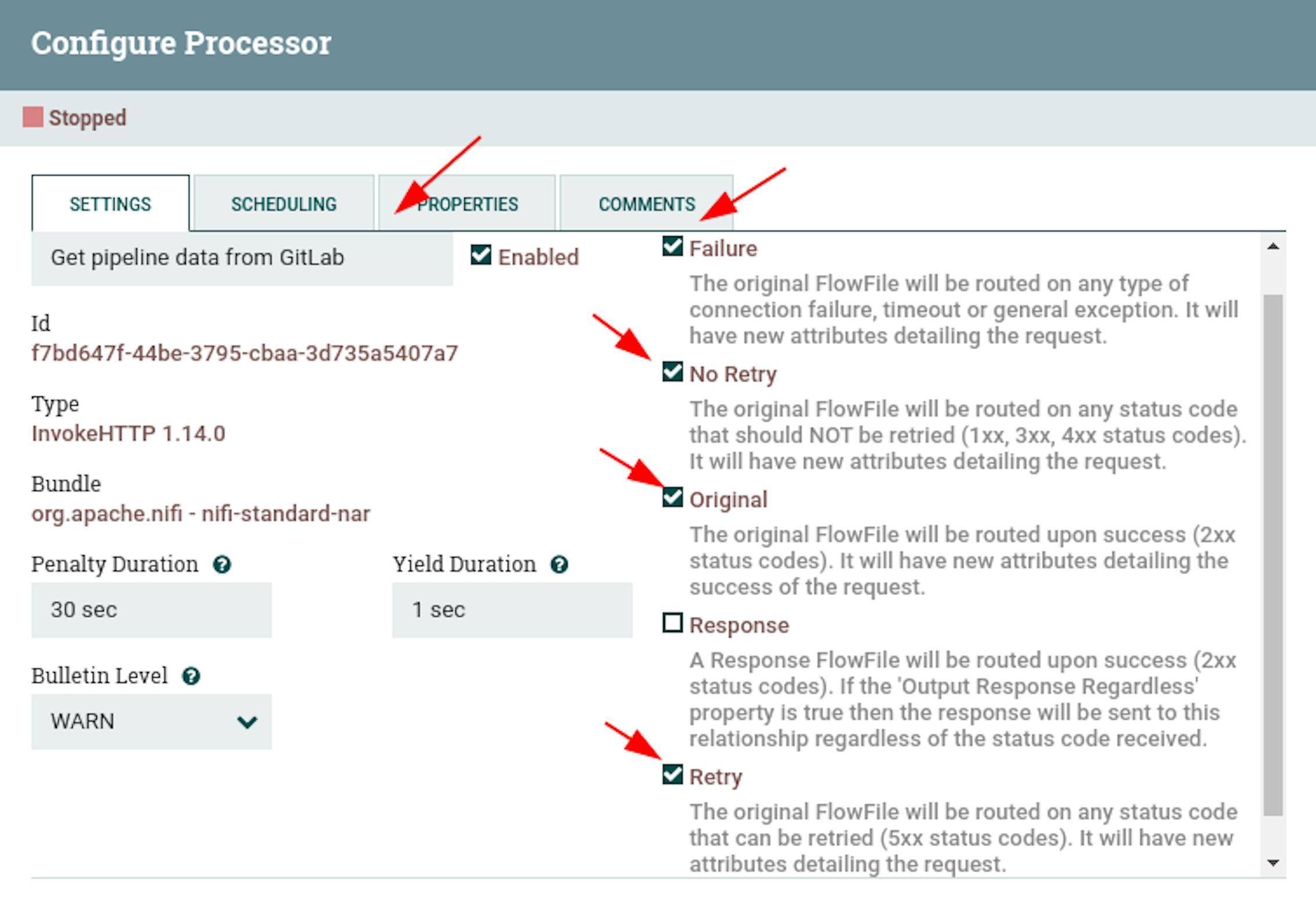
At this stage, we have all the data to make an HTTP request to the GitLab API. In NiFi, the most functional processor for this is the "InvokeHTTP". Let's place this processor and define its following settings:
- Name "Get pipeline data from GitLab".
- Configure automatic termination of sending stream files in the states "Failure", "No Retry", "Original", "Retry".
- In the properties, configure the following existing attributes:
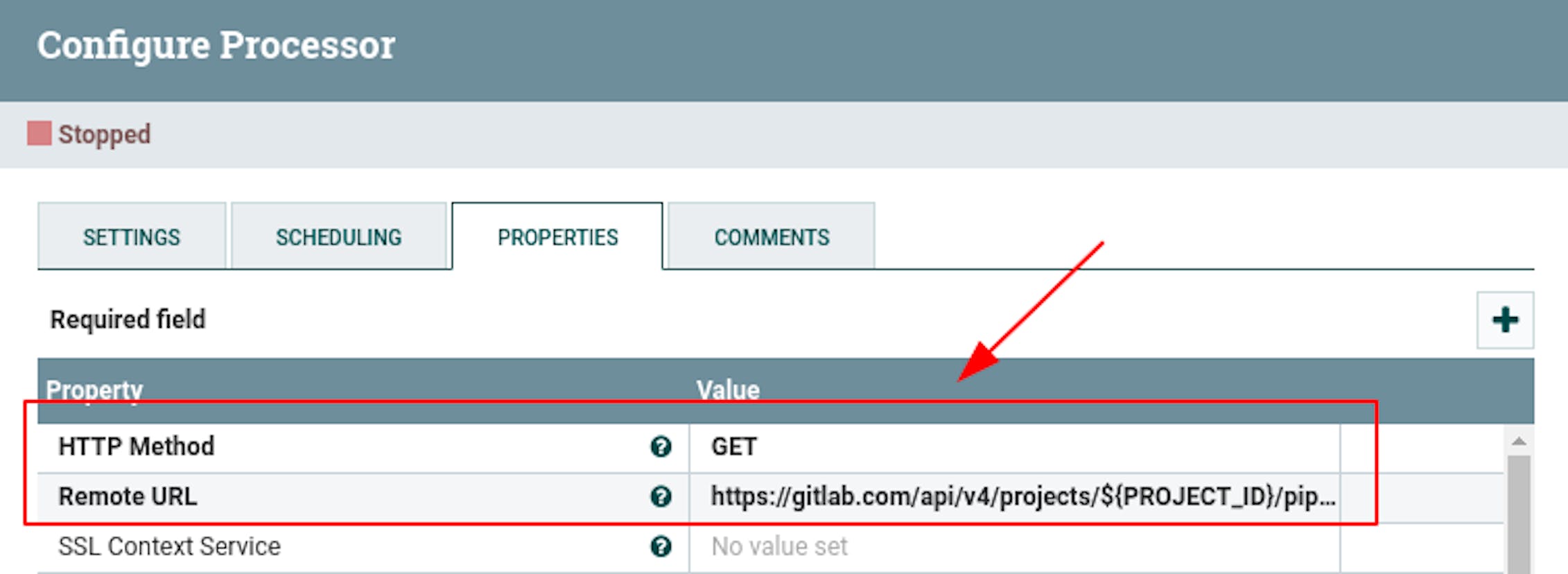
For "HTTP Method" set the value "GET".
For "Remote URL", set a value using the built-in expression language instructions for substituting data from attributes:
Make sure that "Ignore response's content" is set to "false."
Connect the processors with the "success" link:
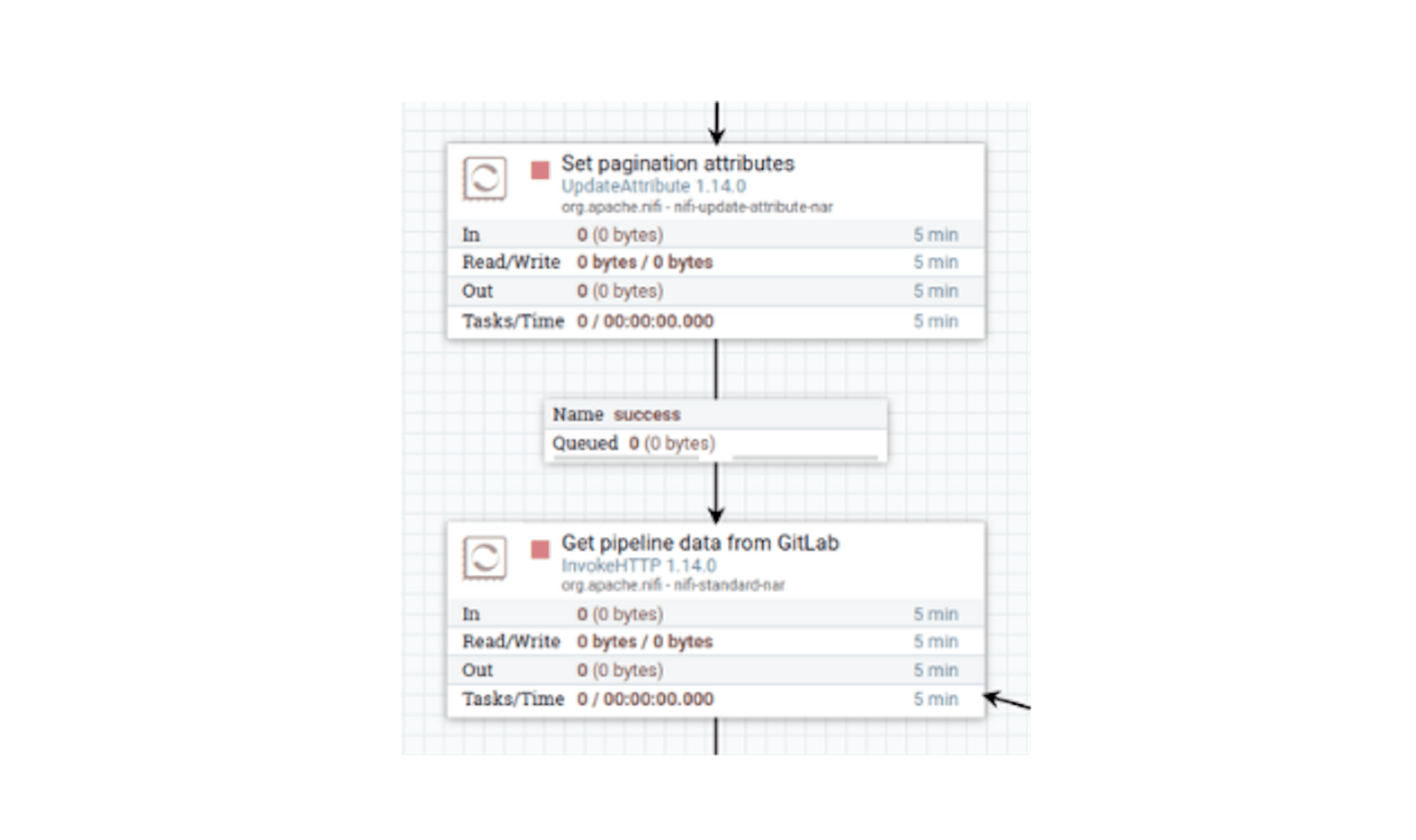
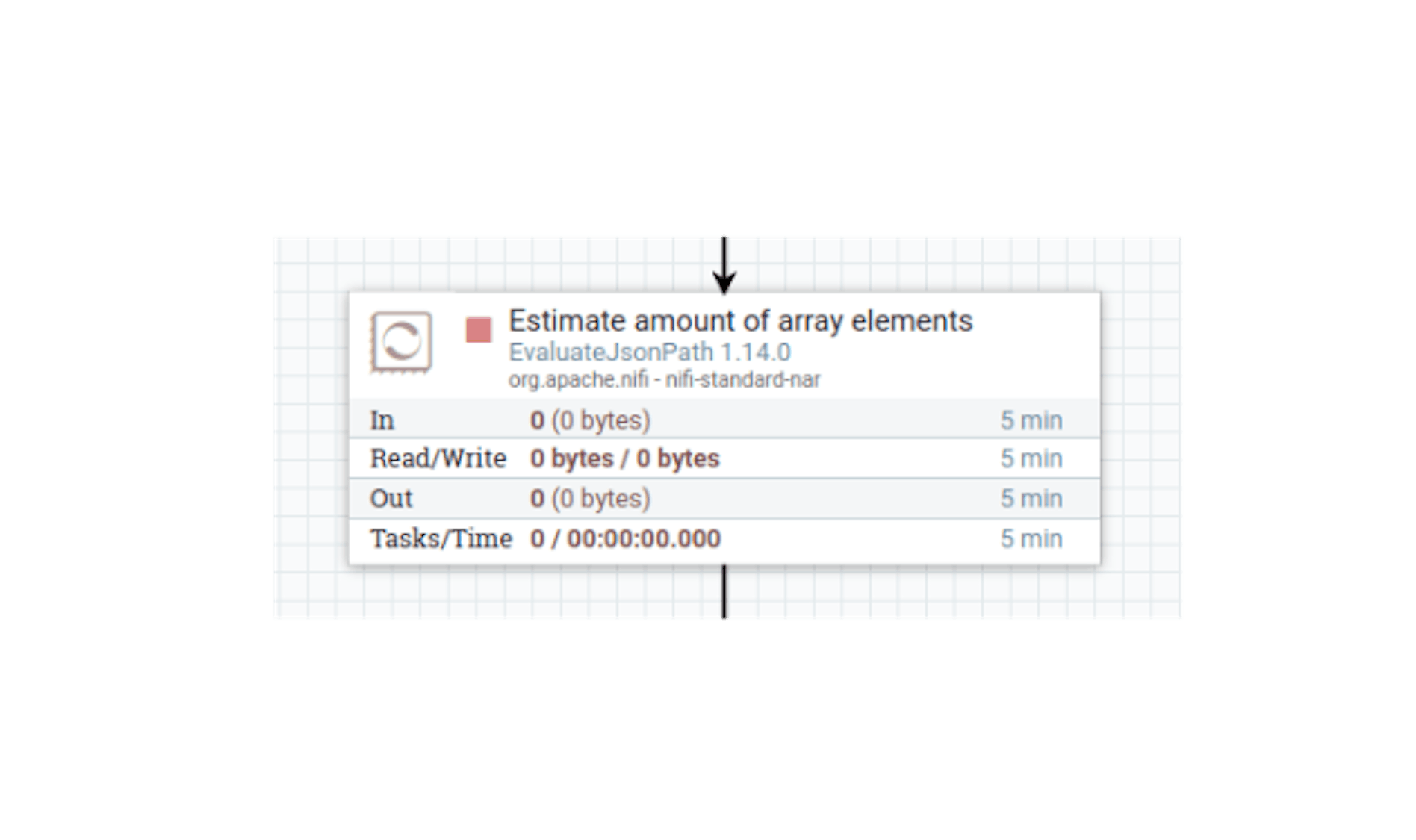
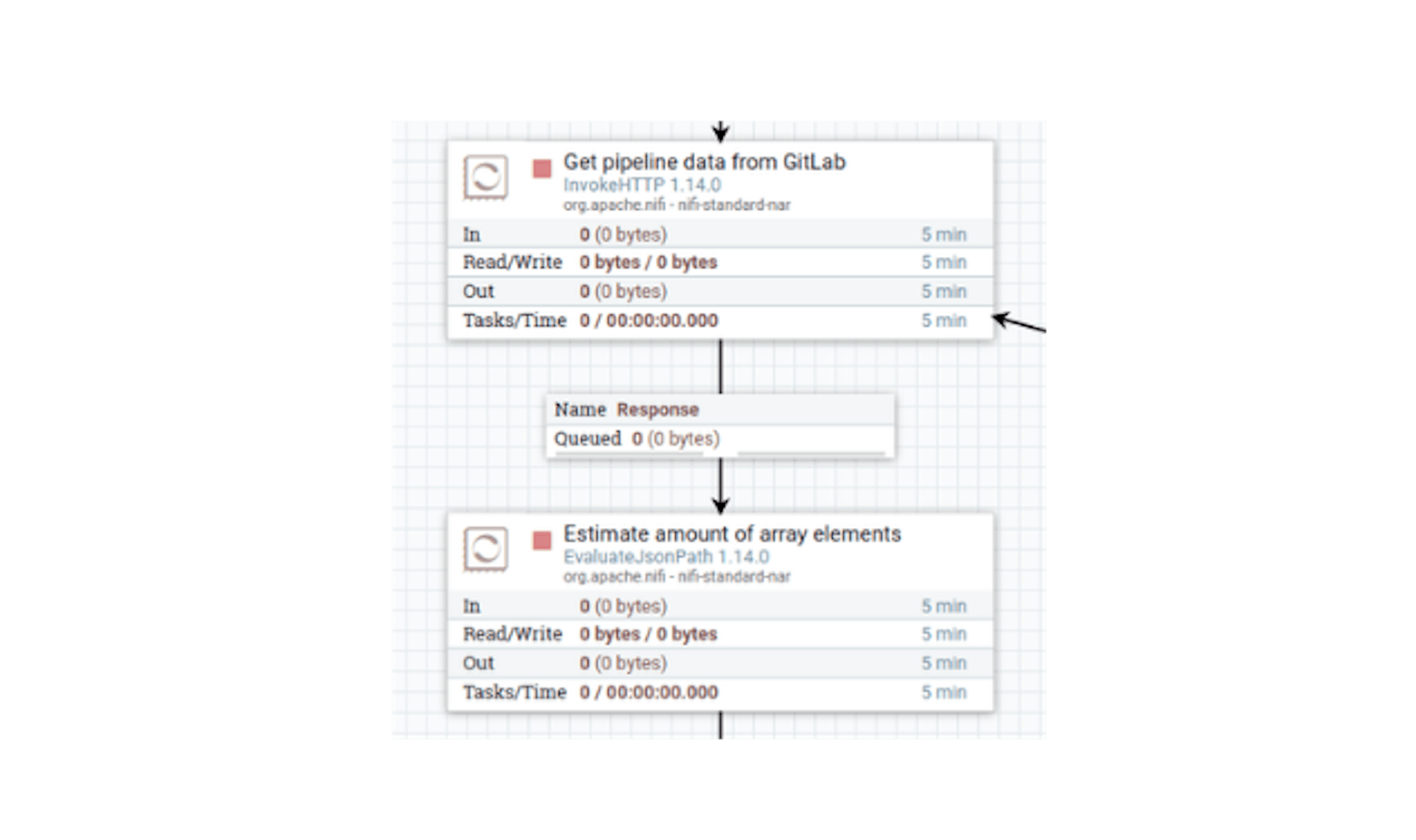
GitLab API, if there are elements to be returned, will return them as an array in JSON. If there are no elements, an empty array will be returned - in this case, no further action is required. It is possible to calculate the length of an array with elements using the "EvaluateJsonPath" processor. Let's place this processor and define its following settings:
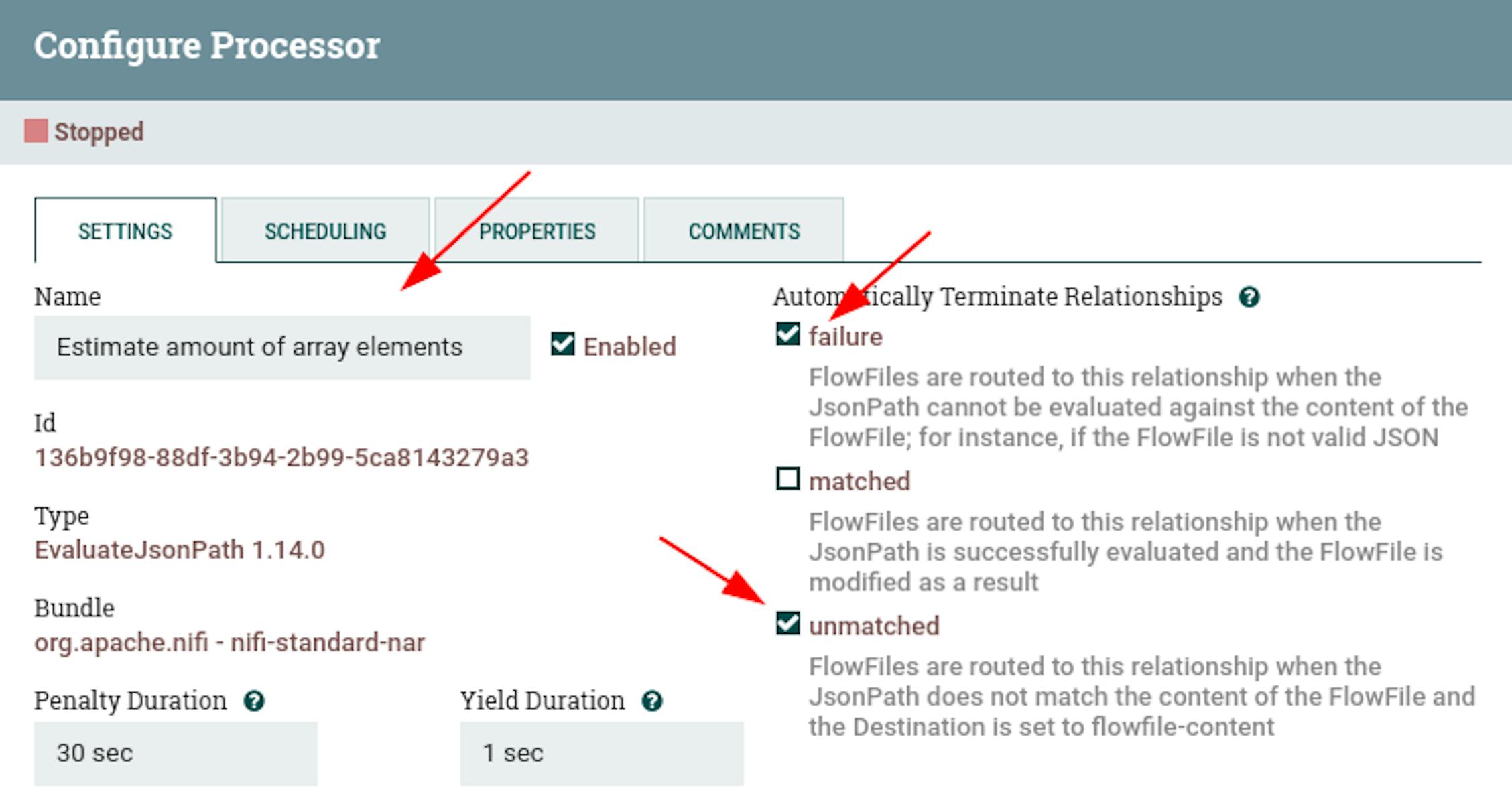
- The name "Estimate amount of array elements".
- Configure automatic termination of sending stream files in the states "failure", "unmatched".
- In the properties, configure the following existing attributes:
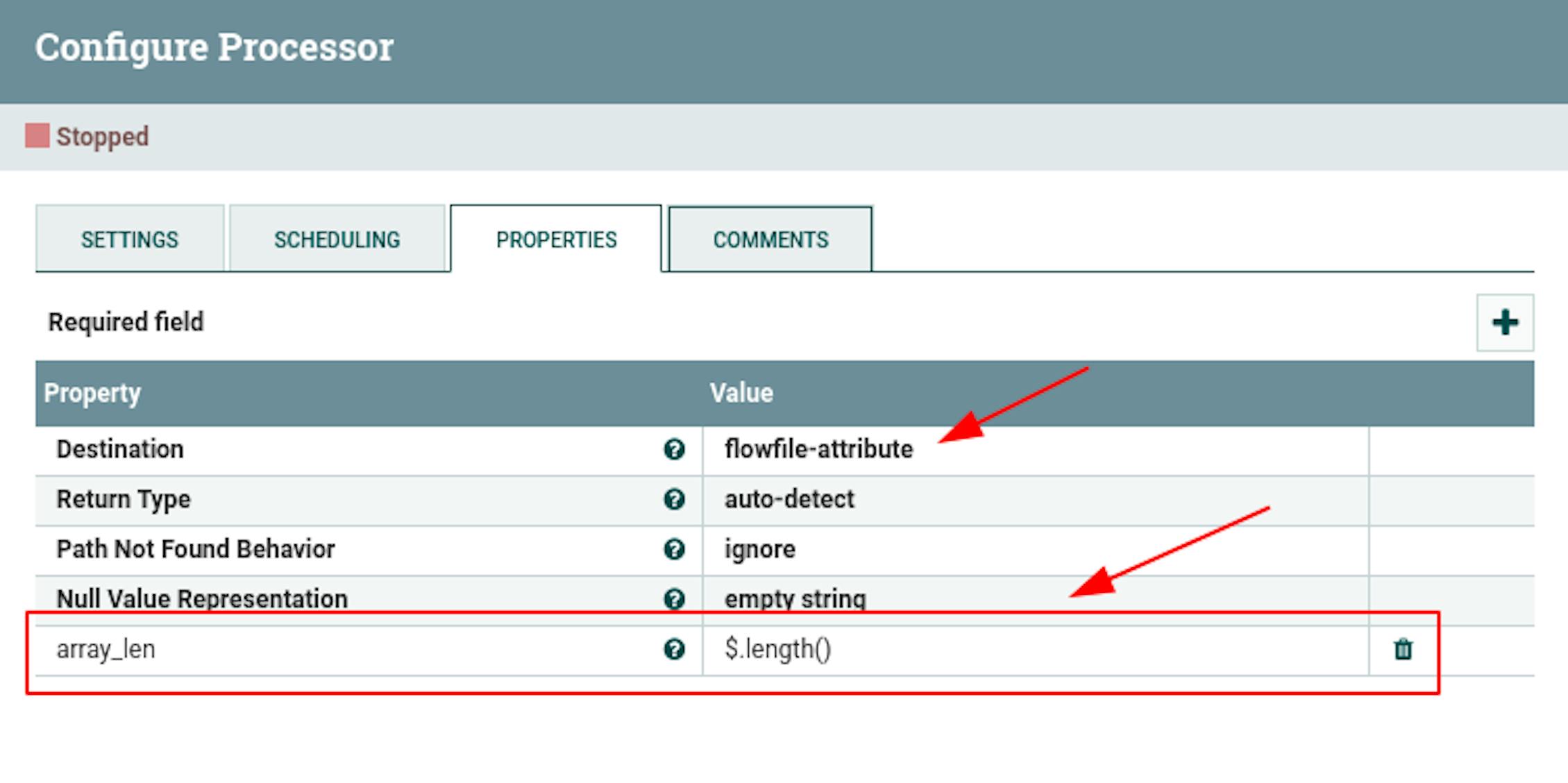
For "Destination", set the value "flowfile-attribute" (i.e., write it as a metadata attribute, not as content).
Add the following attributes to the properties:
"array_len" with the value$ .length ().
After we connect the processors with the "Response" link:
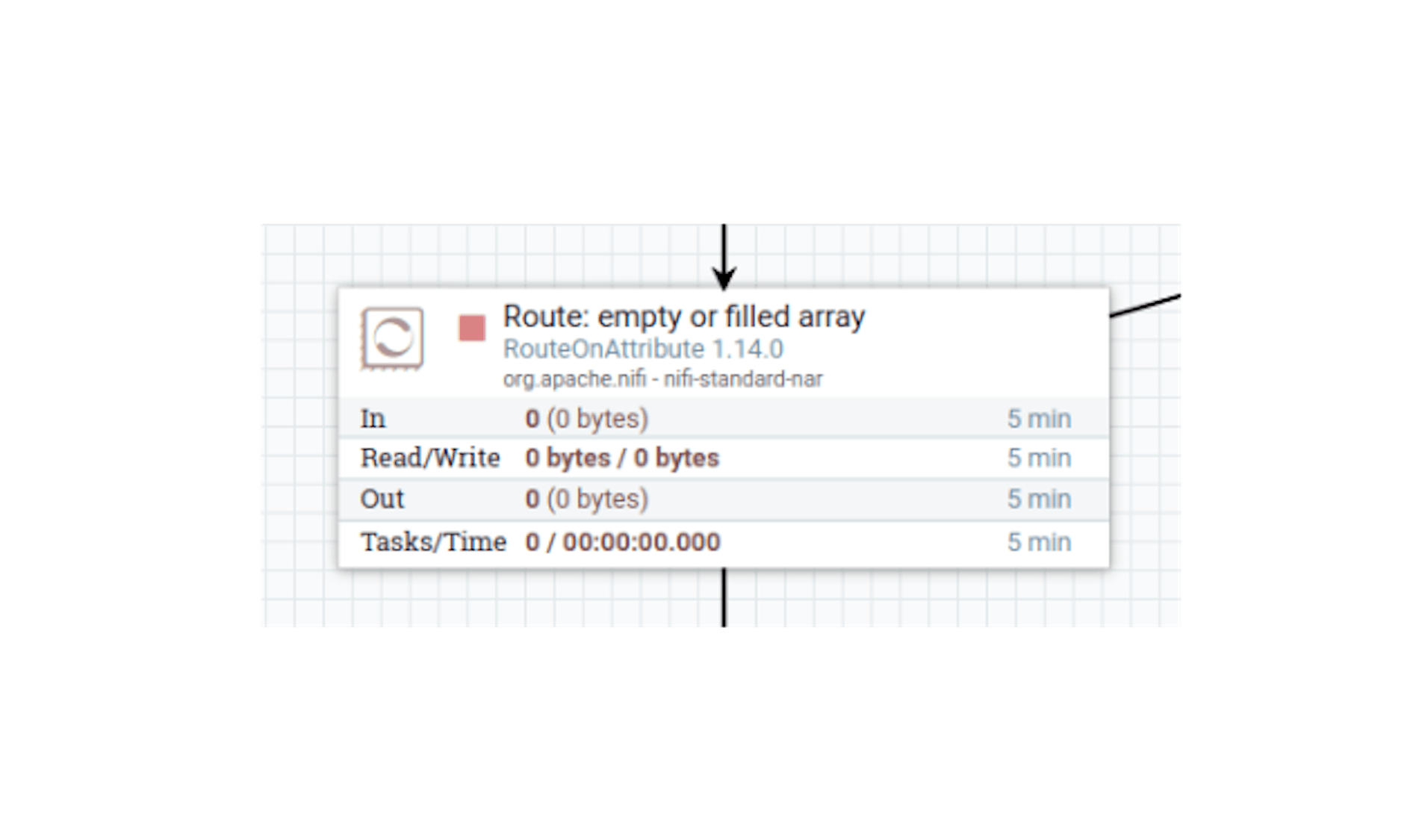
Now we redirect the stream files, provided that the length of the array is greater than or equal to zero. Let's place the "RouteOnAttribute" processor and define the following settings for it:
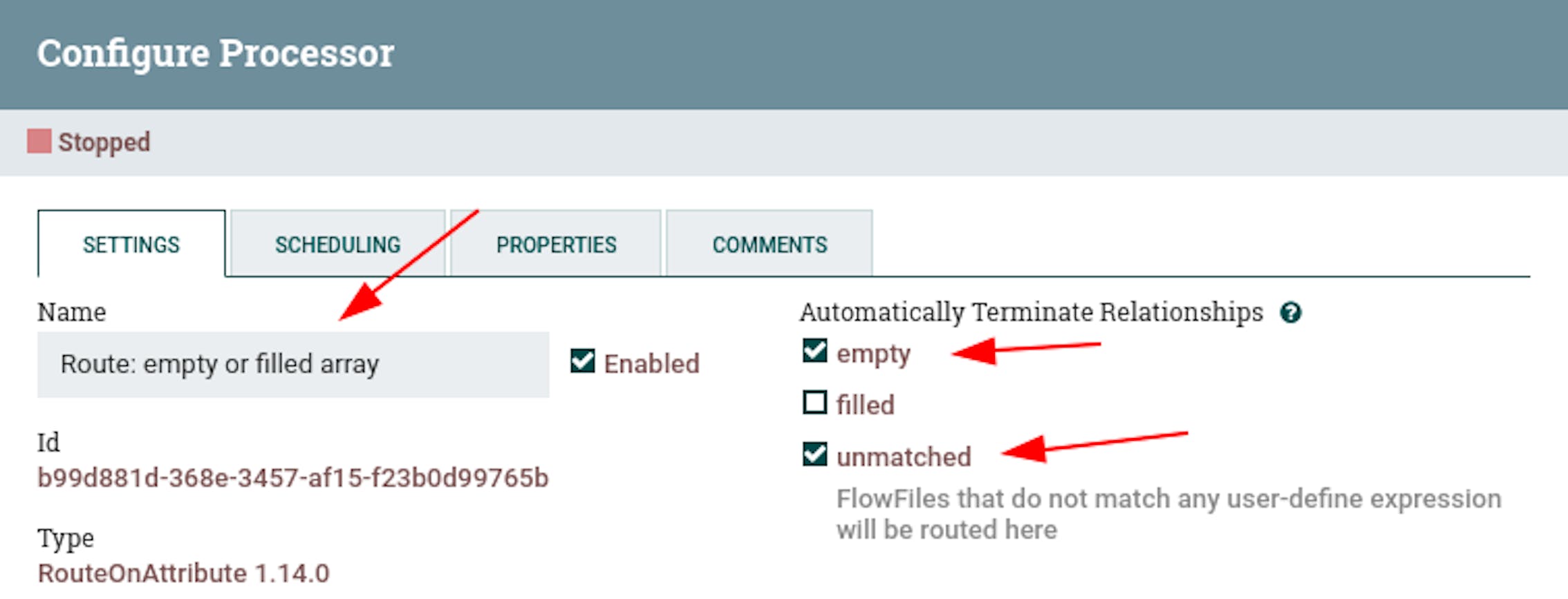
- Name "Route: empty or filled array".
- In the properties, configure the following existing attributes:
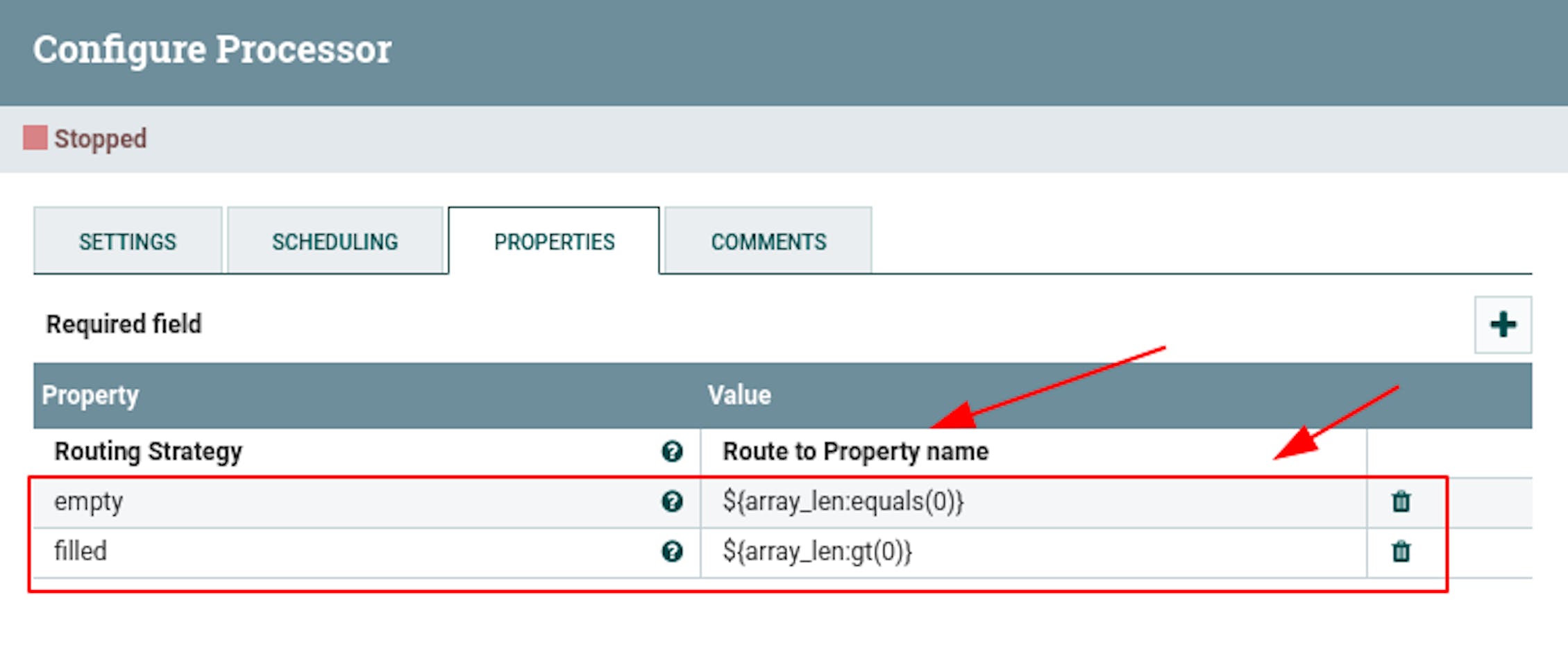
For "Routing Strategy" set the value "Route to Property name". - Add the following attributes to the properties:
"empty" with the value$ {array_len: equals (0)}.
"filled" with the value$ {array_len: gt (0)}.
Configure automatic termination of sending stream files in the "empty", "unmatched" states.
Then we connect the processors with a "matched" link:
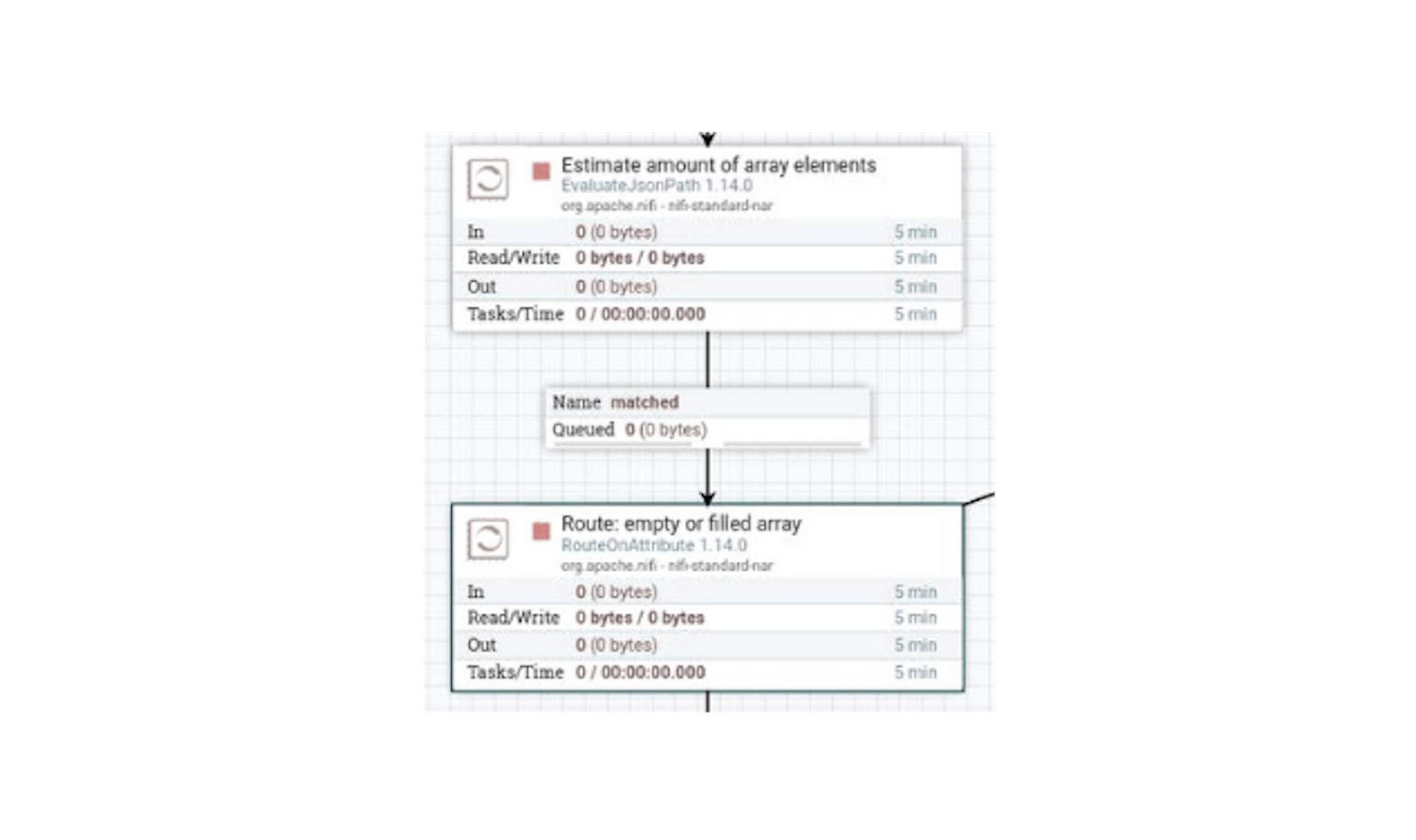
If the array passes empty then the "empty" rule will stop transferring files from the stream. If the length of the array is positive, then you need to do 2 types of actions:
- enlarge the page and restart fetching data from GitLab;
- process the current data.
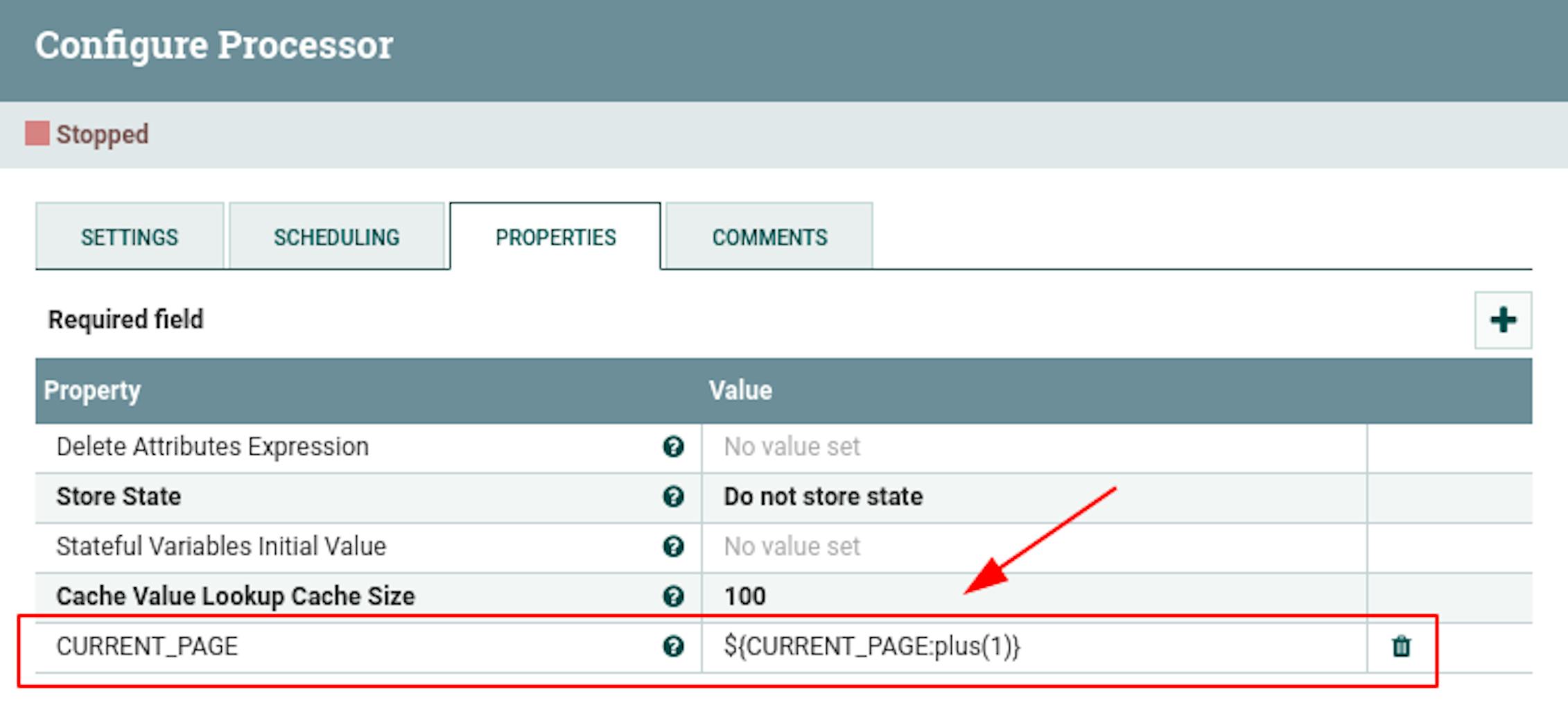
First of all, we will loop receiving data using one more "UpdateAttribute" processor. We place the processor and define the following settings for it:
- The name is "Update pagination attributes".
- Add the following attributes to the properties:
"CURRENT_PAGE" with the value$ {CURRENT_PAGE: plus (1)}(next page).
We will also connect the processors of redirecting, updating pagination and receiving data from GitLab in the manner shown in the screenshot below:
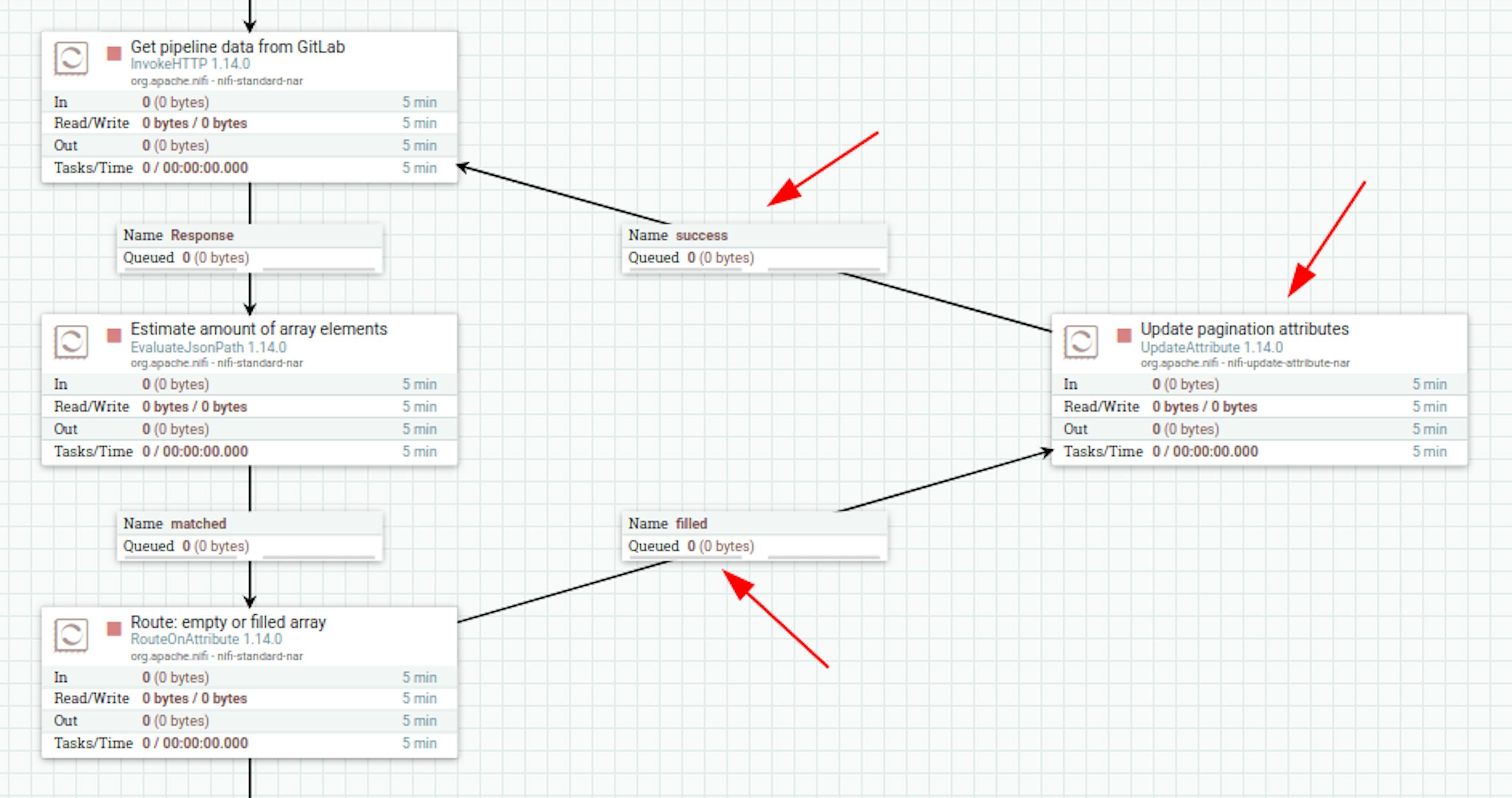
Now we continue working on the existing data. The array of data returned by the GitLab API contains several elements that have the following structure:
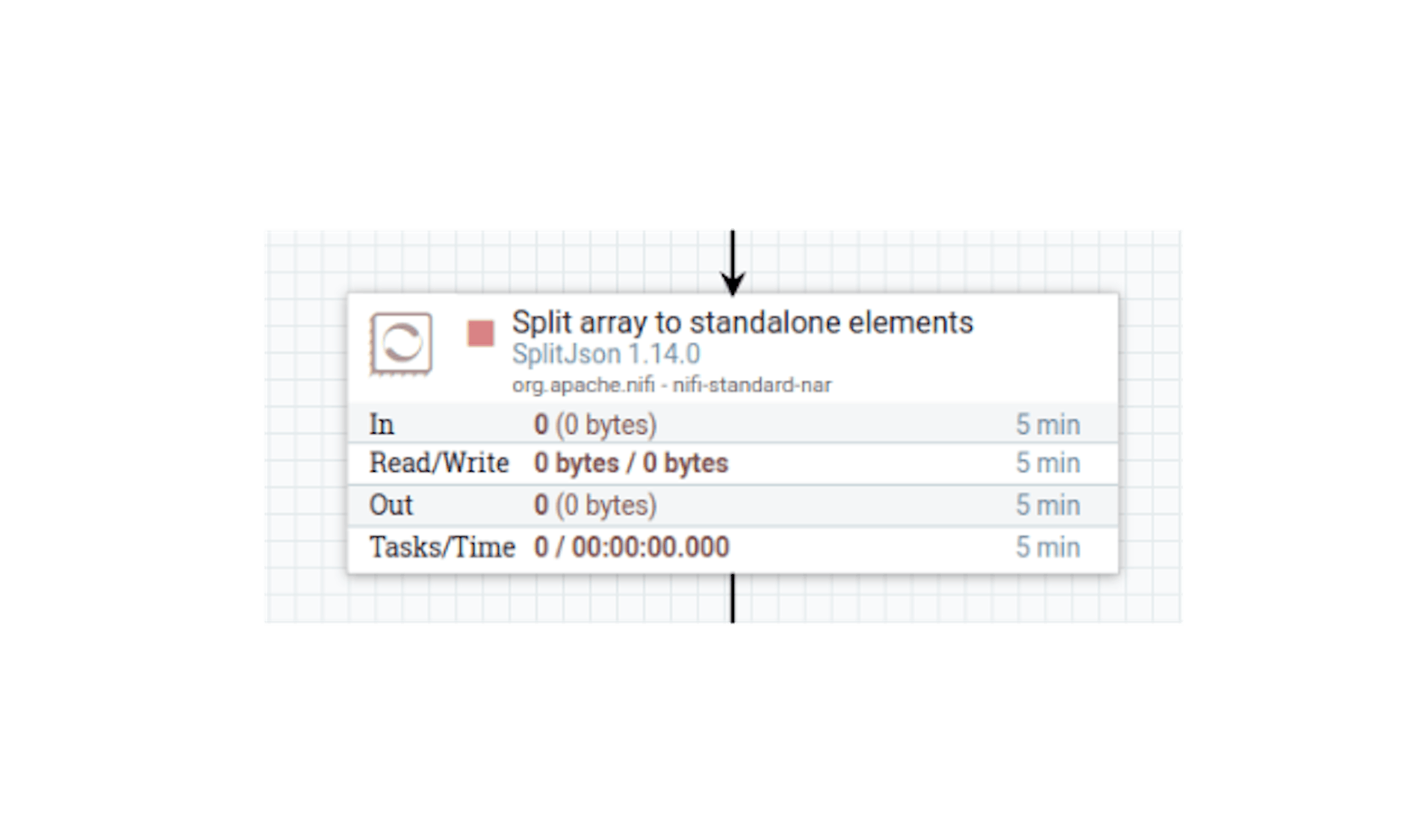
We see that there is more data than required. To clean up data from redundant data, first split the stream file with the array into small stream files with its elements. Let's do it using the "SplitJson" processor. We place the processor and define the following settings for it:
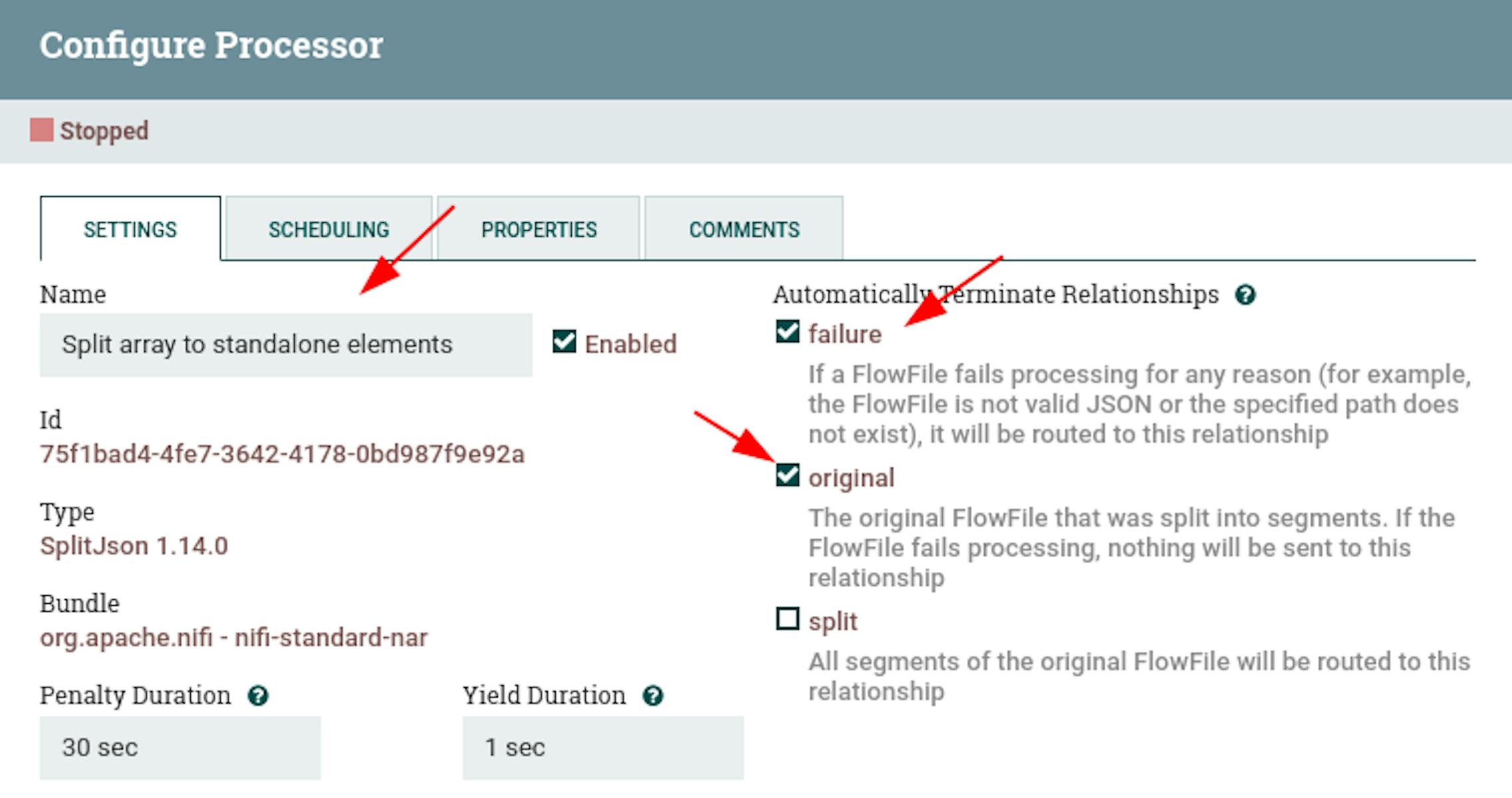
- Name "Split array to standalone elements".
- Configure automatic termination of sending stream files in the states "failure", "original".
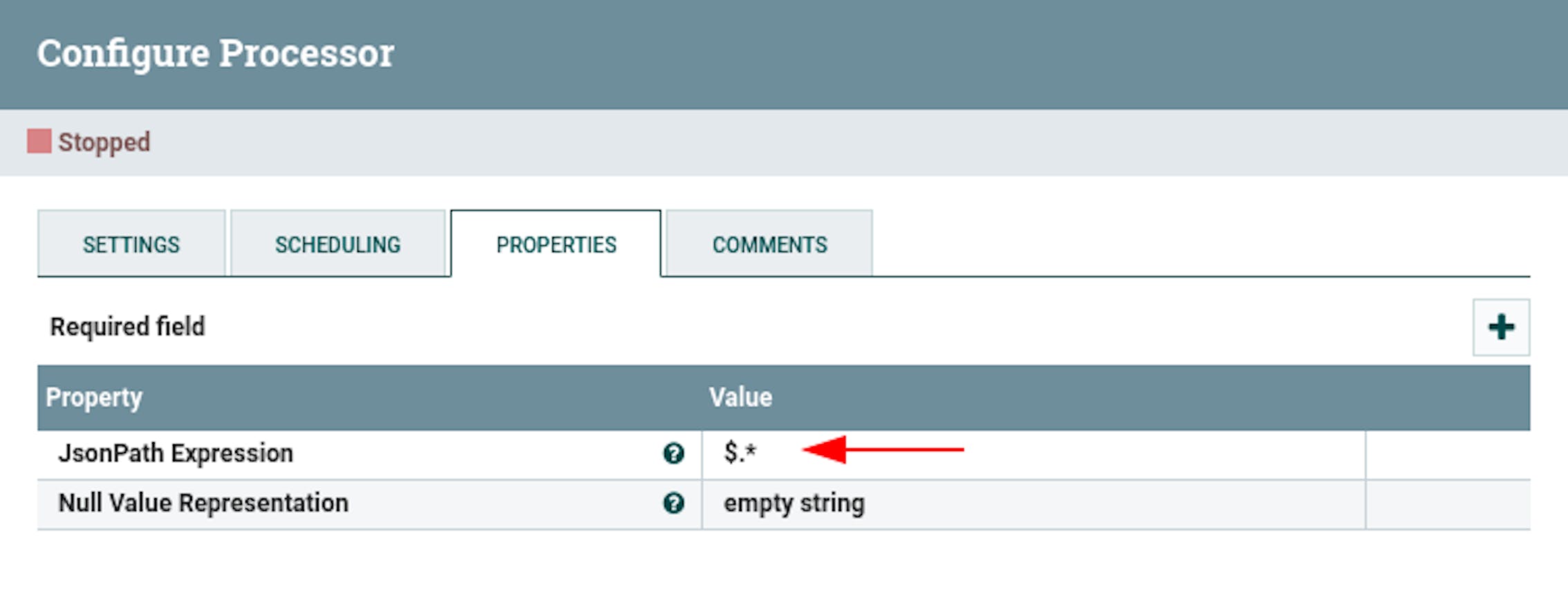
- In the properties, configure the following existing attributes:
"JsonPath Expression" with the value$.*.
Connect the processors with the "filled" link (as with the pagination attribute update processor):
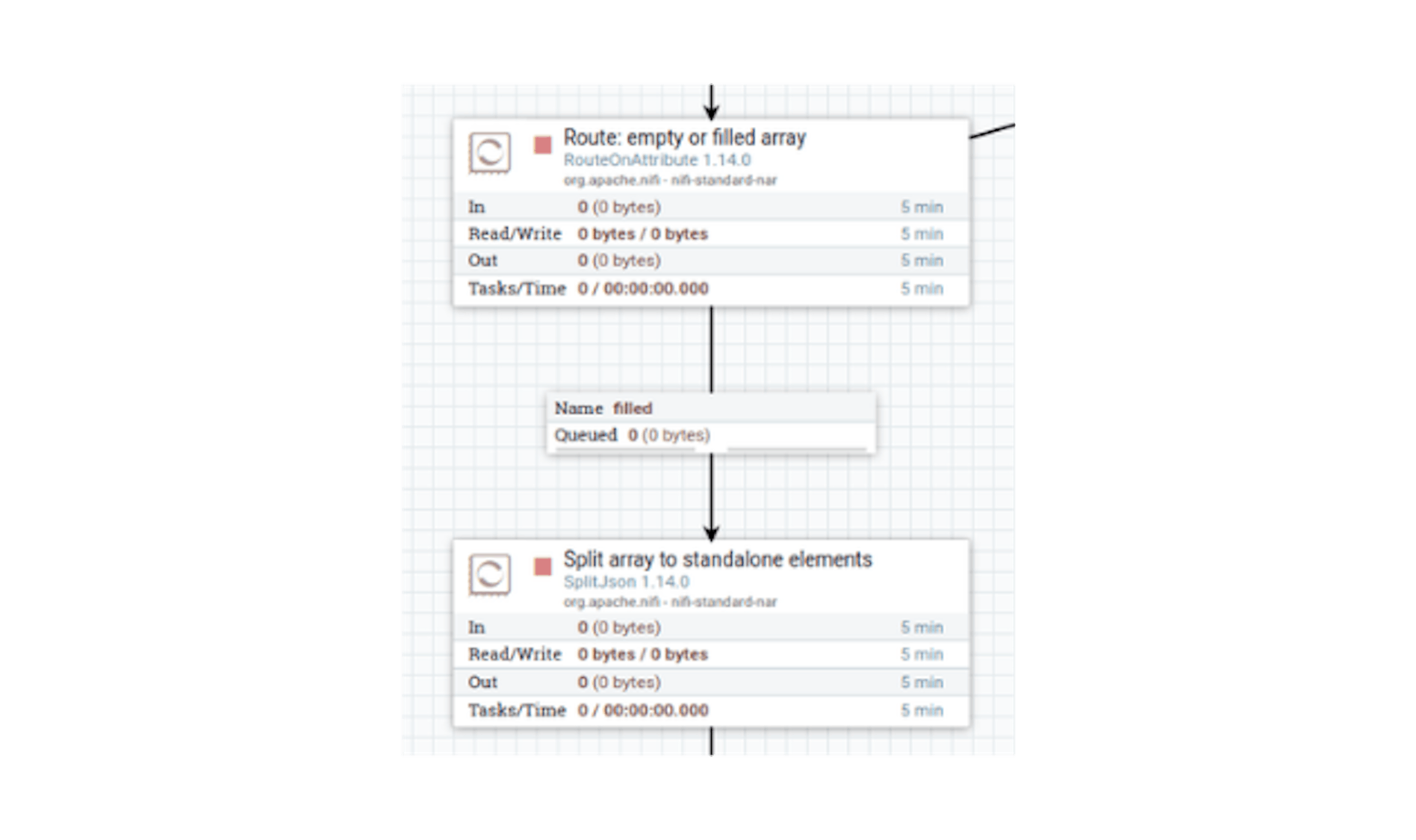
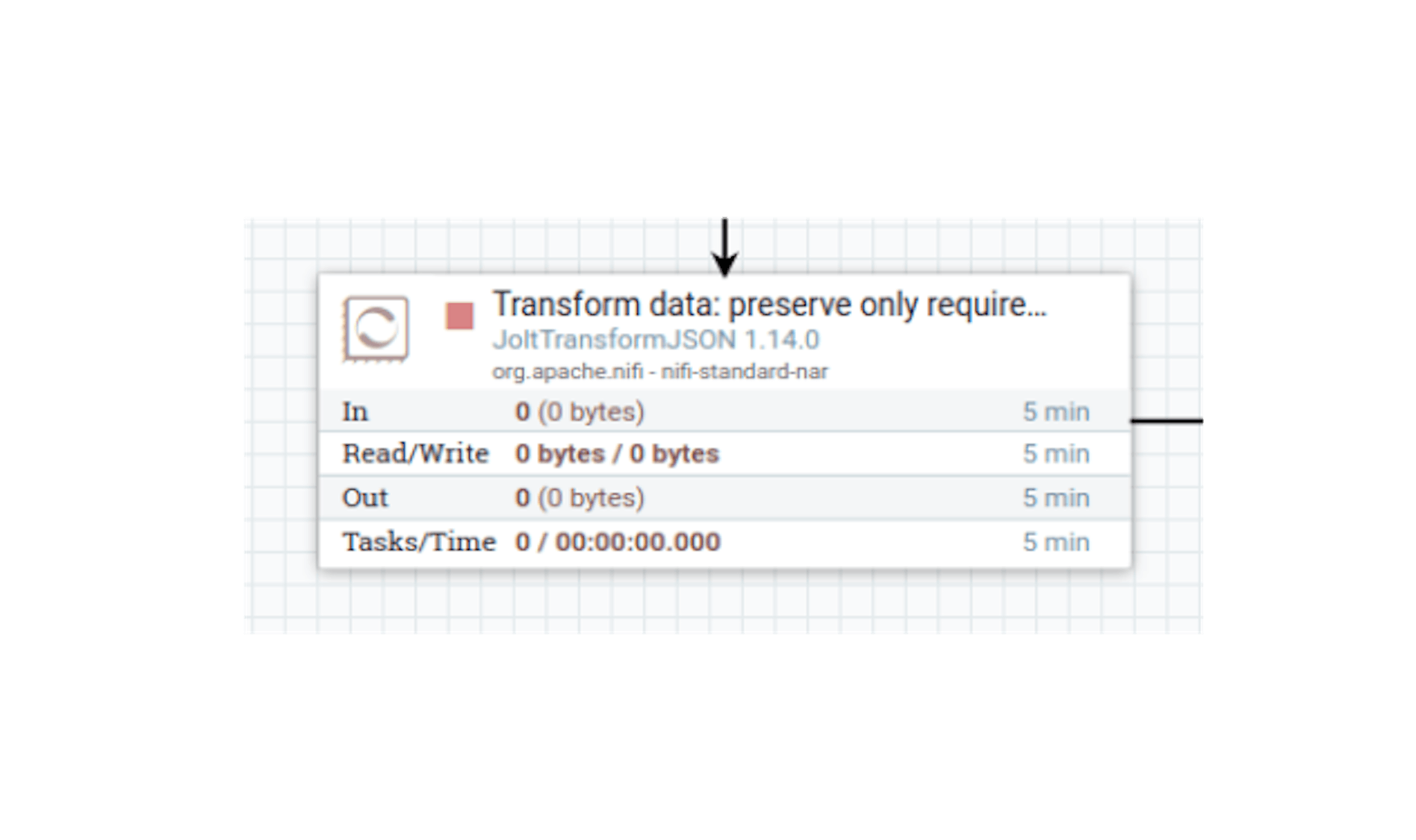
Now several stream files will be generated, and each of them will contain a separate pipeline data object. Let's finish cleaning up the redundancy using the "JoltTransformJSON" processor. It will allow the Jolt transformation notation to be applied to the data of stream files (sandbox). Let's place the processor and define the following settings for it:
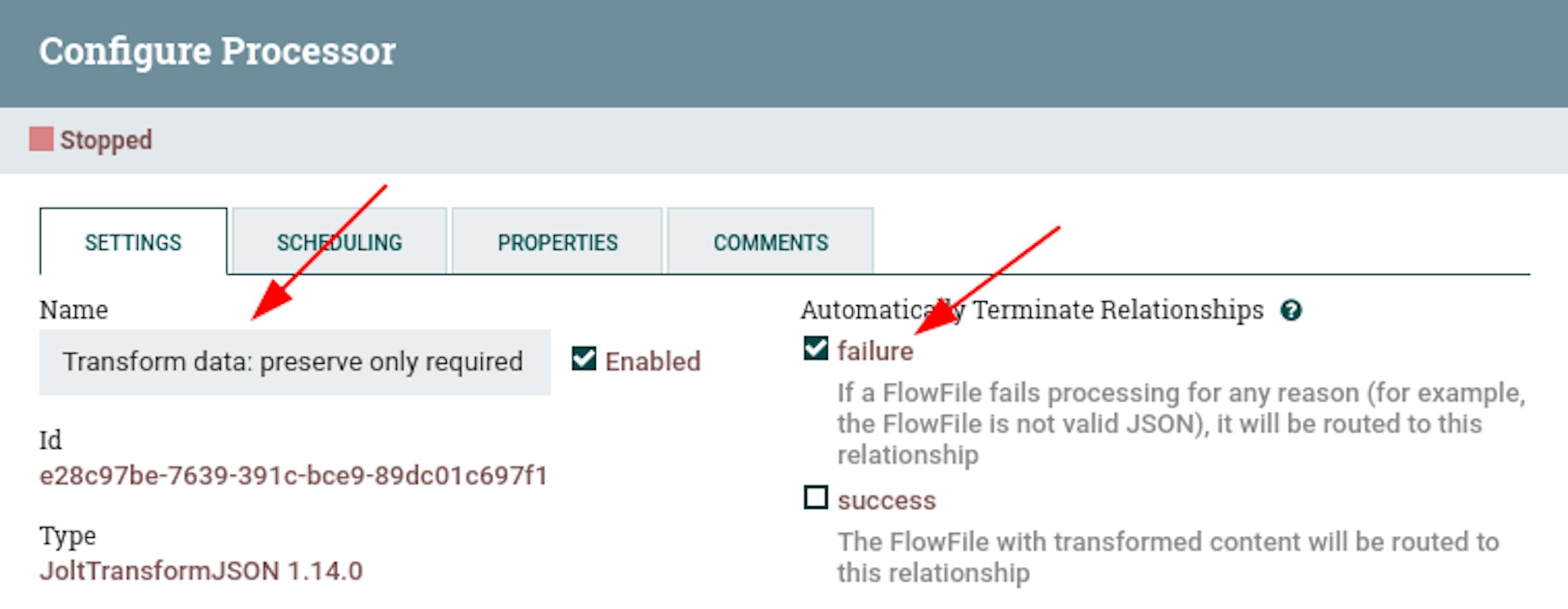
- Name "Transform data: preserve only required".
- Configure automatic termination of sending stream files in case of "failure" state.
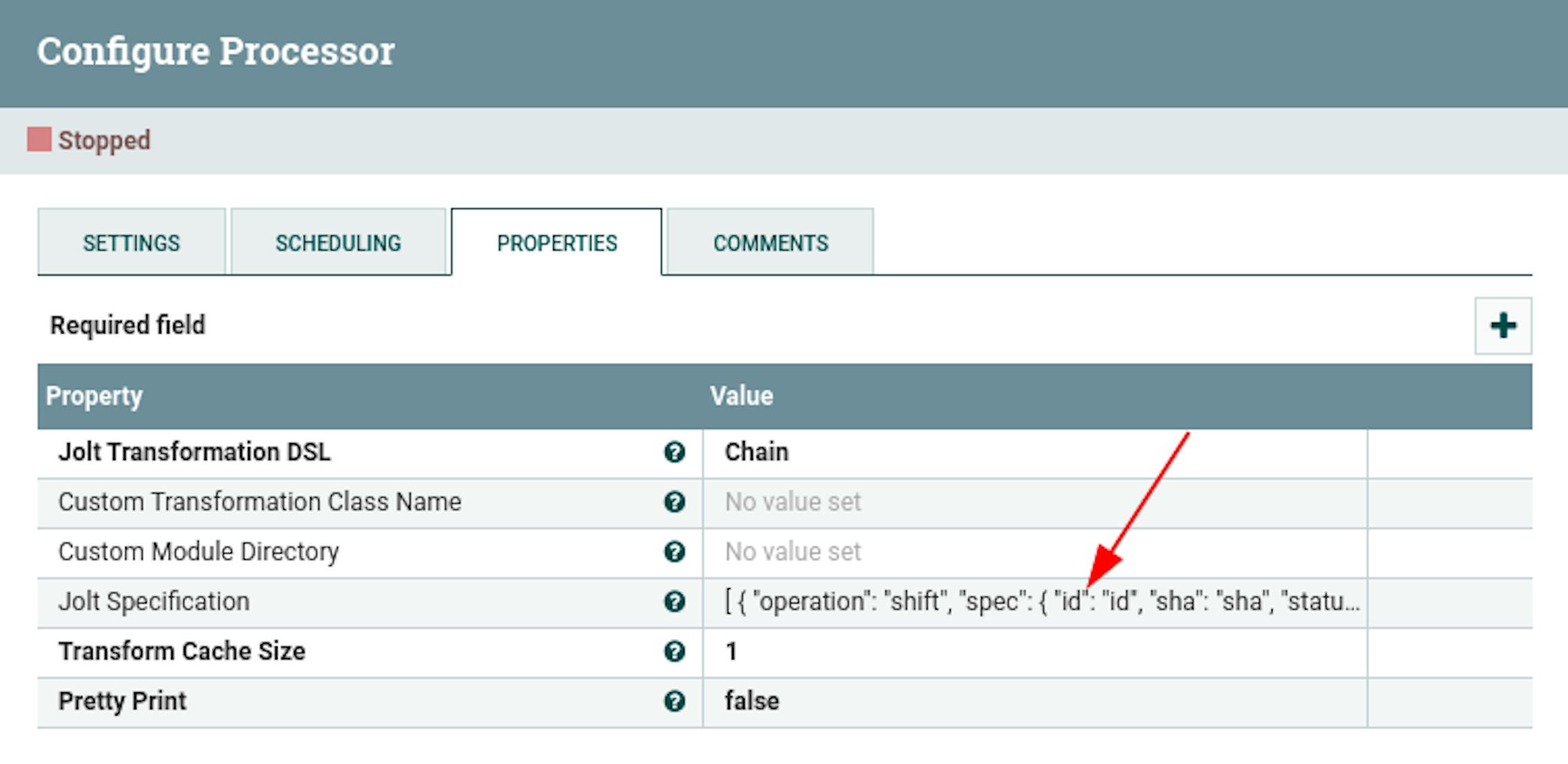
- In the properties, configure the following existing attributes:
"Jolt Specification" with meaning:
So we connect the processors with a "split" link:

At this stage, it remains to send the converted data to the receiving system. For simplicity of experiment, let's implement a simple web server on the NodeJS platform and the ExpressJS framework:
- Create a new directory and execute the command in it:
- Update the package.json manifest file as follows:
- Install dependencies using the command:
- Create an index.js file with the following content:
- Start the server using the command:
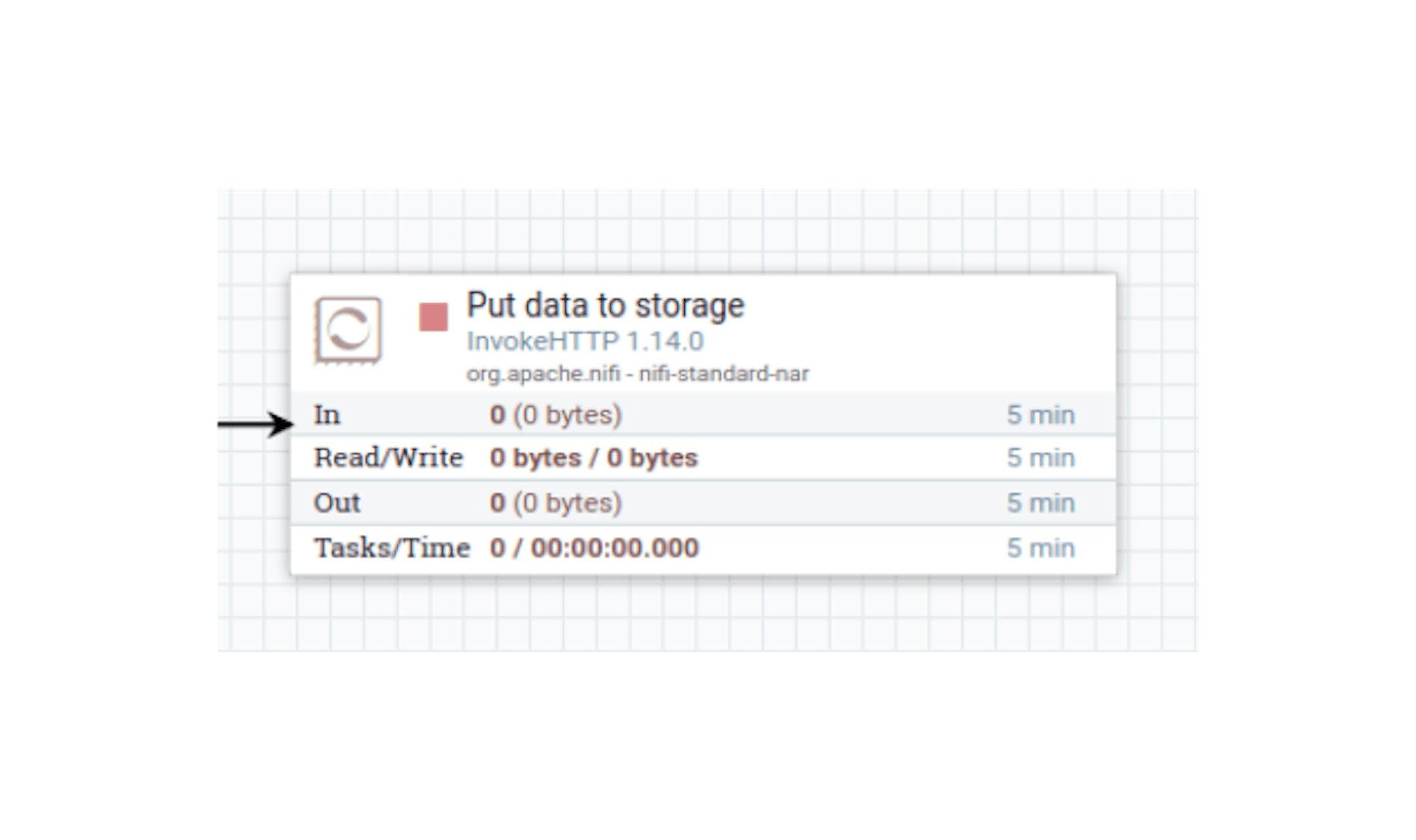
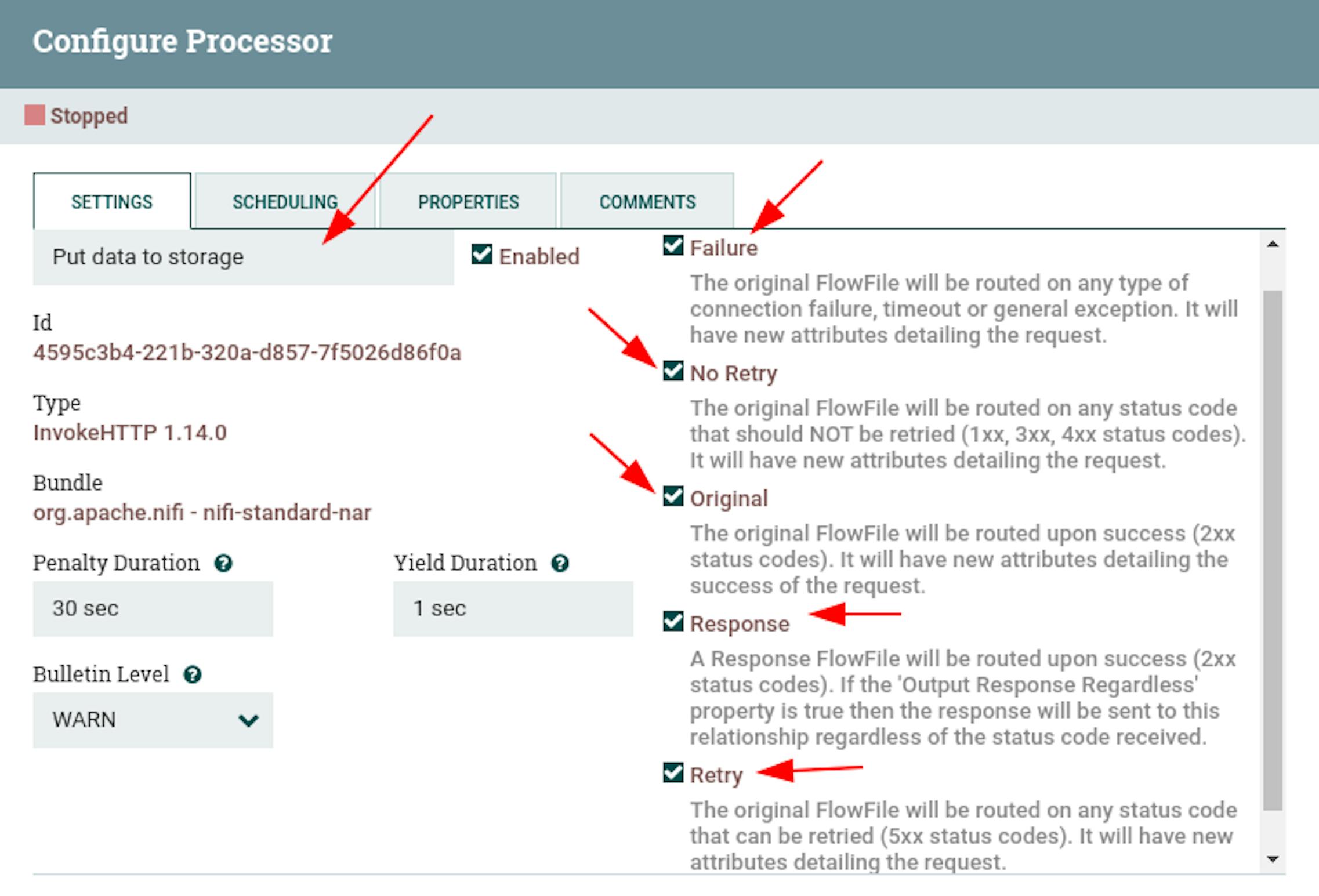
Add one more processor "InvokeHTTP" to NiFi and define the following settings for it:
- Name "Put data to storage".
- Configure automatic termination of sending stream files in the states "Failure", "No Retry", "Original", "Retry", "Response".
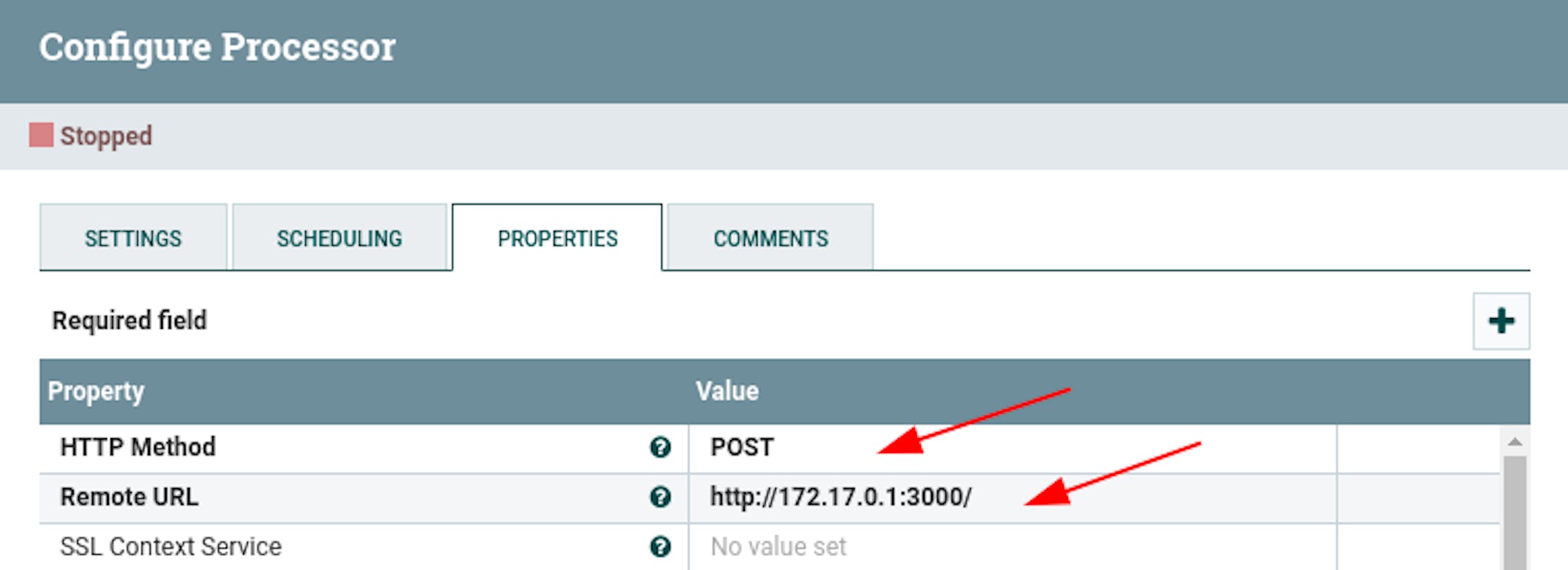
- In the properties, configure the following existing attributes:
"HTTP Method" with the value "POST".
"Remote URL" with a value that corresponds to the server address being routed from the NiFi container. In our case, it was the address http://172.17.0.1:3000/.
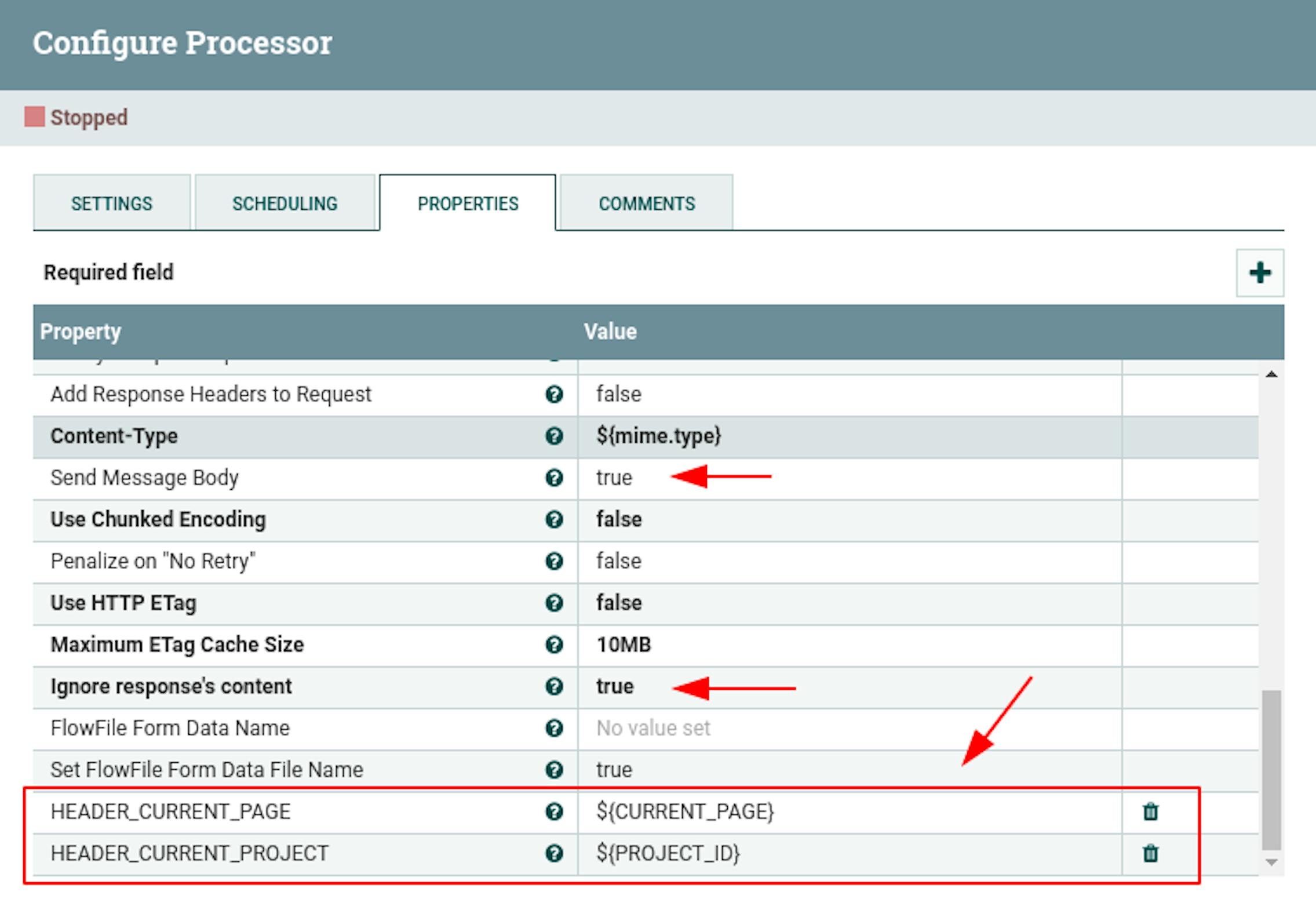
"Send Message Body" with the value "true".
"Ignore response's content" with the value "true". - Add the following attributes to the properties:
"HEADER_CURRENT_PAGE" with the value$ {CURRENT_PAGE}.
"HEADER_CURRENT_PROJECT" with the value$ {PROJECT_ID}.
Connect the processors with the "success" link:
Open the context menu on an empty space in the workspace by right-clicking
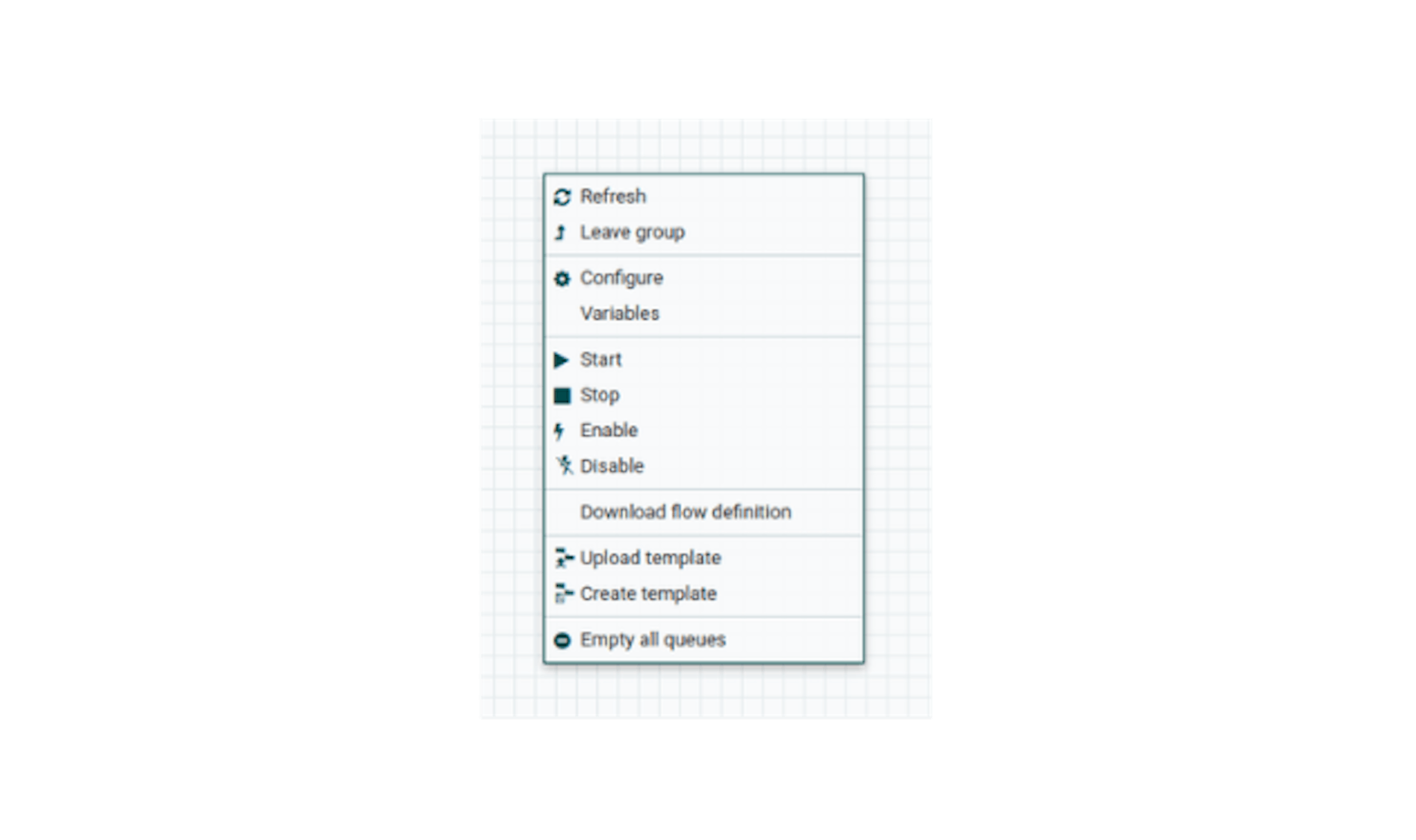
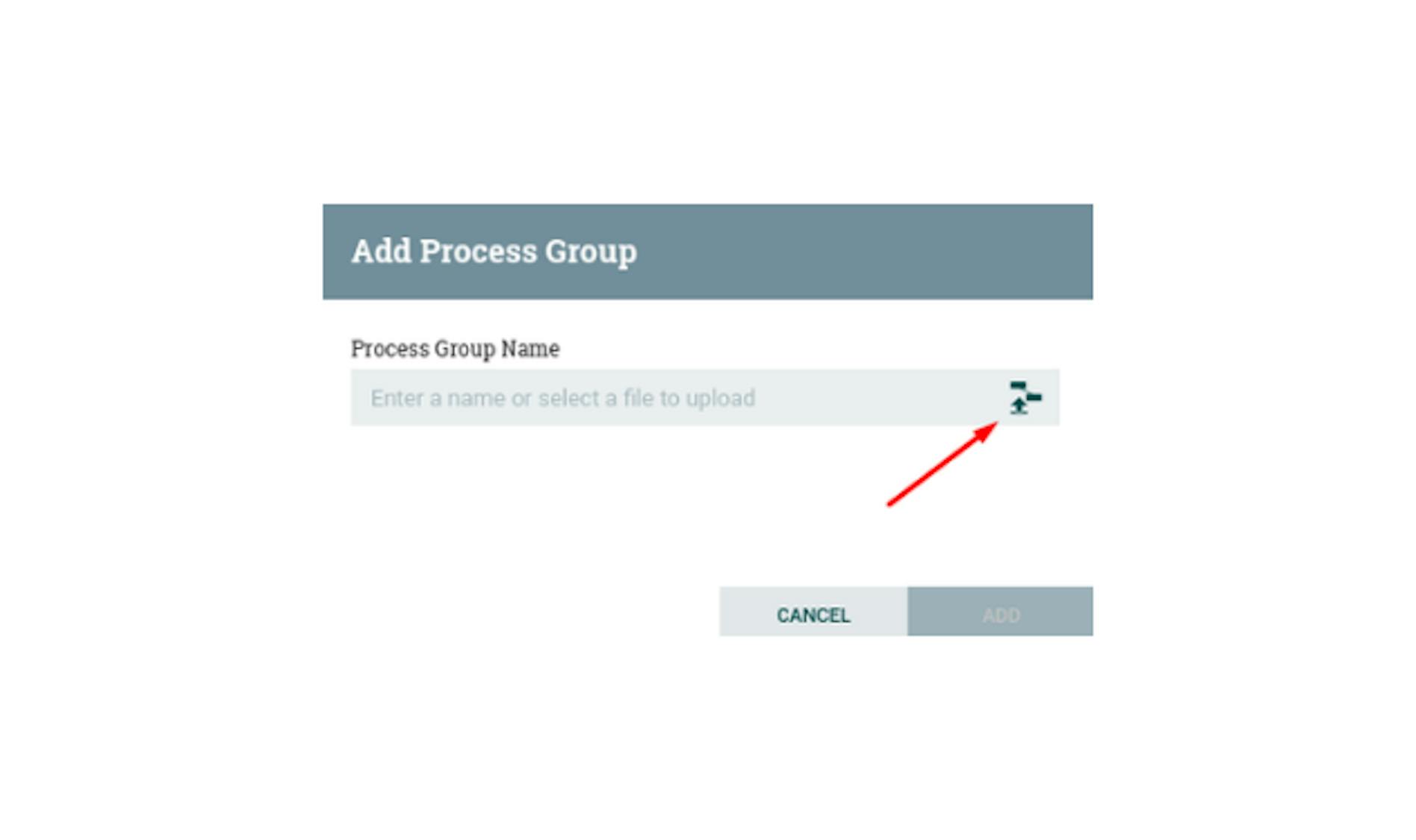
Items "Start"/"Stop" should lead to the start and stop of data transfer. The item "Empty all queues" should empty the queues that could have accumulated during stops. The item "Download flow definition" will save the current process as a JSON file. It can be loaded when adding a process group:
Configurator competencies and qualities
Consider the competencies and qualities required by the user, who will subsequently be responsible for configuring and maintaining the system:
Key features:
- Knowledge of network communication protocols (HTTP, TCP, UDP).
- Knowledge of application programming interfaces for data exchange (REST API).
- Knowledge of data transfer formats and methods of working with them (JSON, XML).
- General skills in working with relational databases (RDBMS). Knowledge of SQL (DDL, DML).
- Analytical mindset.
- Decomposition skills.
Optional features:
- Experience with GitLab, knowledge of the GitLab API.
- Experience with Jira, knowledge of Jira API and JQL.
- Knowledge of APIs other than REST, such as GraphQL.
- Knowledge of JsonPath.
- Knowledge of Jolt.
- Experience and knowledge of one of the programming languages Python, Lua, ECMAScript, Clojure, Groovy, Ruby for the implementation of programmable processors, or Java for the implementation of proprietary processors.
- Experience and knowledge of principles of working with message brokers such as RabbitMQ or Apache Kafka.

Conclusion
When your company is already swimming in data, metric collection helps you focus on only useful data for improving processes and achieving business goals. For this purpose, the Apache NiFi system is considered. The generated process definition illustrates the possibilities when used as a tool for a metrics collection system. The system is suitable because it has the necessary functionality and characteristics for the implementation of these processes.


Latest articles here





