


Analyze with AI
Get AI-powered insights from this Mad Devs article:
Artificial intelligence (AI) has long been a captivating concept: its roots trace back to the academic education and philosophy of the last century. Since then, it has significantly evolved, especially in the realm of machine learning (ML).
49% of organizations use ML and AI in their marketing and sales processes, whether in production or in pilots, to identify sales prospects or to gain insight into their prospects and customers.
Applying ML in business has transformed from a small, localized endeavor into a full-fledged industrial operation. MLOps, an amalgamation of DevOps and AIOps, plays a pivotal role in this evolution, although scaling it can be challenging.
In this article, we talk about what MLOps are and look at the difference between DevOps vs. MLOps vs. AIOps.
We share how we build and apply important MLOps processes at Mad Devs, best practices, and successful case studies from specific companies. And, of course, we closely examine the MLOps market itself, its dynamics, and trends in precise figures. Get a bunch of useful information, after which it will be much clearer to you why and how to increase business growth with MLOps.
What is the difference between MLOps and AIOps and DevOps
MLOps and AIOps are two related approaches to improving the efficiency and effectiveness of tech operations. However, they have different strengths and use cases.
MLOps is a set of practices for managing the entire lifecycle of machine learning models, from development to deployment and production. Its main goal is to bridge the gap between data scientists and tech operations and make deploying and maintaining ML models in production environments easier.
Contrariwise, AIOps (artificial intelligence for tech operations) uses AI and machine learning to automate and improve tech operations tasks like incident management, root cause analysis, and performance monitoring. AIOps aims to help teams identify and resolve problems more quickly and efficiently and to improve the overall reliability and performance of tech systems.
And on the other side, DevOps is focused on automating and streamlining the software development and delivery process. It aims to bridge the gap between development and operations teams and make deploying and maintaining software applications in production environments easier.
In the table below, we will compare the key characteristics of MLOps, AIOps, and DevOps to help you better understand their similarities and differences. This will assist in determining which of these methodologies is most suitable for you.
| Features | MLOps | AIOps | DevOps |
|---|---|---|---|
| Focus | Machine learning development and deployment. | Tech operations automation and improvement. | Software development and delivery. |
| Key practices | Continuous integration, delivery, and testing, infrastructure as code, containerization, continuous training, model monitoring, and data management. | Event correlation, anomaly detection, cause and effect finding, diagnostics. | Continuous integration, continuous delivery, continuous testing, infrastructure as code, containerization. |
| Primary users | Data scientists, ML engineers, DevOps engineers. | Tech operations teams, DevOps and MLOps engineers, and data scientists. | Software developers, DevOps engineers. |
| Benefits | Faster and more efficient ML development and deployment, improved ML model performance and reliability. | Reduced time and effort for manual tech processes, improved tech problem-solving speed and accuracy. | Faster and more efficient software development and delivery, improved software quality and reliability. |
If you need to unlock peak efficiency and agility with DevOps, contact us to get on the path to optimized solutions, reduce costs, and improve efficiency.
The best approach for your organization will depend on your specific needs and goals. DevOps is a good option to consider if you are developing and deploying traditional software applications. If you are developing and deploying ML models, then MLOps is a good option. In case you want to automate and improve your tech operations, AIOps is for you.
Many organizations are using a combination of DevOps, MLOps, and AIOps to improve their tech operations. For example, an organization might use DevOps to automate its software development and delivery process and then use MLOps to automate the deployment and management of its ML models. They might also use AIOps to monitor their tech systems for anomalies and automate problem resolution.

What is the impact of MLOps quality on model capabilities and business value
As we mentioned above, MLOps focuses on automating and streamlining the machine learning development and deployment process.
Netflix claims that the combined effect of ML-based personalization and recommendations saves the company $1 billion annually by improving customer retention.
So what benefits do you get with quality MLOps? Let's break them down.
With quality MLOps
- The capabilities of the model are constantly increasing, which allows you to process more new types of data and make more profound conclusions. From the behavior of the entire market to the behavior of a particular consumer.
- The model's accuracy is constantly increasing, making more comprehensive predictions and conclusions, and more complex decisions with greater certainty.
- Automatically tested and qualitatively updated versions of the model seamlessly integrate into the used services and allow you to have the most relevant tool for analysis and prediction at any given time.
- The model continues to add more value to the business, improving the quality of decisions previously made or even enabling decisions that were formerly not even discussed.
Without quality MLOps
- Model capabilities remain flat at best, notwithstanding competition.
- Model accuracy slowly decreases, which leads to an increase in inaccurate conclusions and more erroneous decisions.
- Updates to the model do not reach the service with the necessary frequency or quality, making the service less usable.
The model continues to require at least minimal resources for its maintenance, but cannot even recoup them. Overall, it brings no real value to the business and even produces losses due to inaccurate conclusions and erroneous decisions.

MLOps best practices
It is a set of guidelines and recommendations for developing, deploying, and managing machine learning models in a production environment. These practices can help you improve the efficiency, reliability, and scalability of your ML operations.
Hybrid commands. Build hybrid teams, where each member excels in their role. Employ an adept MLOps engineer to oversee and uphold high standards.
Pre-agreed metrics. Define metrics early, influencing algorithm choice and guiding development from design to deployment.
Focus on processes and consistency. ML models often lack transparency, prioritizing accuracy over understanding. Focus on processes to predict outcomes and systematically identify influential factors.
Data pipelines. Data transformation in real-time can be challenging, but data pipelines are a solution. These independent pipelines can automate various transformations, making it easy to adapt to different data sources and needs, whether for model training or real-time use.
Model and data versioning. Models are mutable and much more defined by data than by code. So you should not misunderstand directly associating a specific model version with a particular code version but rather treat it more comprehensively.
Comprehensive unit testing of models. Unlike traditional software, models can't simply pass or fail a test due to their inherent lack of 100% accuracy. Models should be evaluated based on their historical iterations rather than static tests. Similar to comprehensive unit testing, model testing should involve various data types. Automating online model training based on extensive test coverage is essential.
Comprehensive unit testing of data. Testing data is crucial for machine learning models because they rely on both code and data. Neglecting separate data testing can skew the model's performance. Comprehensive unit testing of data should encompass various data types and processing methods, with data pipelines offering versatile testing possibilities.
Data licensing. Licensing the training data, especially publicly sourced data, is a valuable practice to avoid legal issues and build a reputable image. This practice is gaining prominence in the reputation landscape.
Monitoring. Robust infrastructure is crucial to monitor the performance of the machine learning model in a real-world setting. It tracks metrics like latency, traffic, errors, and prediction performance. Data pipelines and advanced unit testing play a vital role in achieving this too.

What is the MLOps platform?
MLOps platforms are software products that help automate and manage all phases of the machine model lifecycle, from their initial build and training to their deployment and retraining, as well as the necessary data and operations on it.
Typically, MLOps platforms provide the following list of features:
- MLOps frameworks integrations to build and train models
- Tools for version control of datasets and pipelines
- Tools for controlling and training versions of models
- Tools for systematic optimization of hyperparameter values
- Tools for deploying and monitoring a model in a production environment.
Top MLOps platforms
Let's look at the list of top MLOps platforms, which can include both global MLOps companies and MLOps startups that provide a variety of tools.
Amazon SageMaker
One of the most popular MLOps platforms for building, training, deploying, and managing ML models. It is great for any level solution, but especially suitable for enterprises. The special thing is that it works great with AWS; you'll be twice as comfortable if you're already familiar with it.
| Advantages | Disadvantages |
|---|---|
|
|
Azure Machine Learning
One of the biggest MLOps platforms for building, training, deploying, and managing ML models. Also great for businesses of all sizes.
| Advantages | Disadvantages |
|---|---|
|
|
Google Vertex AI
This is a unified data and AI platform that provides a comprehensive set of tools for building, deploying, and managing ML models. It includes features for data preparation, model training, deployment, and monitoring.
| Advantages | Disadvantages |
|---|---|
|
|
Kubeflow
A full-fledged MLOps open-source platform simplifies several machine learning stages, including training, pipeline development, and Jupyter laptop maintenance. Also, Kubeflow offers integration with many specialized services. It is great for businesses of all sizes, especially for small and medium ones.
| Advantages | Disadvantages |
|---|---|
|
|
MLflow
Extremely handy MLOps open-source platform is designed to let you quickly and efficiently do experiments and work with ML libraries, algorithms, and deployment tools. Perfect for small and medium-sized businesses.
| Advantages | Disadvantages |
|---|---|
|
|
Algorithmia
One of the most powerful MLOps platforms for research and quick, secure, and effective model delivery.
| Advantages | Disadvantages |
|---|---|
|
|
Bottom line
These platforms range in functionality and number of tools they offer. Still, it's essential to understand that those at the bottom focus more on specific stages of the model lifecycle, which they handle just fine.
In fact, looking at what set of features each MLOps platform can provide, and what features they have is a broad topic. If you'd like us to expand on this list and do a detailed breakdown and comparison of them, share it in the comments.
MLOps use cases
The market for MLOps is estimated to grow from USD 1.1 billion in 2022 to USD 5.9 billion by 2027.
In fact, 10% of enterprises now use 10 or more AI applications. Plus, 73% of all CEOs and CHROs in the US plan to use more AI in the next 3 years.
And for a good reason — according to Salesforce Research, 69% of tech leaders believe ML is transforming their business.
Of course, the numbers are constantly changing as the desire to implement ML for various reasons in different industries and companies keeps growing. However, anyone who wants to develop or add ML to their company or products in a valuable way has to implement quality MLOps. Let's take a closer look at examples of industries and companies in them.
Tech industry
Of course, here it's the first use because, within the tech industry, it's much easier to implement and realize than in others. Also, tech companies accumulate a crazy amount of data, which gives them a tremendous opportunity to build and train their own models.
If divided by the percentage, about 75% of companies implement MLOps for service operations, 45% for product or service development, 38% for marketing and sales, 26% for supply-chain management, 22% for manufacturing, 23% for risk predictions, 17% for increasing human capacity, and 17% for strategy and corporate finance.
Constru
Constru is an Israeli tech company that used ClearML to implement MLOps, and the results were quite great.
- Reduce the time for reproducing experiments by 50%
- Twice as much ML work is handled without additional staff
- Projected savings of $1.3 million over the next year.
NetApp
NetApp is a US-based company that used the Iguazio platform to deploy MLOps and had great results.
- Improved the time to develop and deploy new AI services by 6-12x
- Reduced operating costs by 50%.
KONUX
KONUX is a German tech company that uses the Valohai platform.
- Running 10X the number of experiments with the same amount of effort by automated machine orchestration and experiment tracking.
Sharper Shape is a US tech company that also uses the Valohai platform to implement MLOps.
- Automation of infrastructure and experiment management tasks that take a third of data scientists' time
- New data scientists can be onboarded in a quarter of the time.
E-commerce
Another important area is e-commerce because the large flow of users and the ever-expanding set of services require more complex and accurate machine learning models, thus better MLOps.
You can see in these statistics that about 23% of companies implement MLOps for service operations, 13% for product or service development, 52% for marketing and sales, 38% for supply-chain management, 7% for manufacturing, 9% for risk predictions, and 8% for increasing human capacity.
Booking.com
Booking.com, a company everyone knows, has implemented MLOps with great returns.
- Ability to scale AI with 150 customer-facing ML models.
Finance
We also have great examples from finance, where there has always been a huge flow of users and transactions, the accuracy of which has always had to remain high. As financial services become more functional, they also need quality MLOps to manage the increasing number of models that apply there.
Statistics say that 49% of companies implement MLOps for service operations, 26% for product or service development, 33% for marketing and sales, 7% for supply-chain management, 6% for manufacturing, 40% for risk predictions, 9% for increasing human capacity, and 14% for strategy and corporate finance.
Payoneer
Another famous company, Payoneer, implemented MLOps using Iguazio.
- Built a scalable and reliable fraud prediction and prevention model that analyzes fresh data in real-time and adapts to new threats.
Insurance
Another incredibly important area where machine learning is necessary is insurance. To forecast events and build solutions with maximum accuracy, directly determine the profit of this industry. Here, there are some interesting cases too.
NTUC Income
NTUC Income, a Singaporean company, implemented MLOps using the DataRobot platform.
- Reduced the time to generate results from a few days to less than an hour.
Topdanmark
Topdanmark, a large European insurance company, has also implemented MLOps for a number of its machine learning models.
- It saves us significant time previously spent on maintenance and investigation
- Allows us to track model performance in real-time and compare it to our expectations
- Automatically detected a drift that previously would have taken months to detect.
Manufacturing
Manufacturing is one area where machine learning is making more money and solving previously unsolvable problems of incredible complexity. So with the increasing development of ML, manufacturing is adopting it, and it requires more quality MLOps, which provides huge benefits.
Oyak
Oyak, a Turkish cement manufacturing company, implemented MLOps using the DataRobot platform and got great results.
- Increased alternative fuel usage by 7 times
- Cut 2% of total CO2 emissions
- Reduced costs by $39 million.
Transportation
Traditionally, the transportation industry is very complex, as it involves many variables, most of which are incredibly difficult to analyze and predict. Of course, this is also an industry where ML not only increases profits but also solves a huge number of previously unsolvable problems. As model adoption in this industry grows, so does the models' complexity and asks for the adoption of quality MLOps.
Statistics say that 51% of companies implement MLOps for service operations, 34% for product or service development, 34% for marketing and sales, 18% for supply-chain management, 4% for manufacturing, 4% for risk predictions, 2% for increasing human capacity, and 3% for strategy and corporate finance.
Uber
The famous US company Uber uses a lot of ML models to ensure quality and profitability. However since their investment opportunities are great, they decided to develop everything from scratch. Apparently, it was a good decision.
- Developed their own ML platform, Michelangelo,
- From zero to hundreds of ML products in three years, thanks to MLOps practices.
Healthcare
Another vital industry where ML is solving problems that until recently were beyond human capabilities. The excellent results of ML implementation are so telling that its adoption is growing rapidly, and hence the demand for quality MLOps implementation.
Statistics show that 46% of companies implement MLOps for service operations, 48% for product or service development, 17% for marketing and sales, 21% for supply-chain management, 9% for manufacturing, 19% for risk predictions, 18% for increasing human capacity, and 13% for strategy and corporate finance.
Philips
Philips, a famous Dutch company, is probably best known to many people as a manufacturer of home electronics, but it's also a very big provider of medical equipment. The company has many products across different industries, which makes its work more challenging. So they've been actively implementing ML and MLOps using the ClearML platform, which has yielded good results.
- Hours saved through streamlined experiment tracking and automatic documentation.
Steward Health Care
Steward Health Care US is a company that has implemented MLOps using the DataRobot platform and has shared some amazing results in numbers, which gives an extremely clear indication of how valuable a truly quality MLOps is.
- $2 million/year in savings from nurse hourly wages per patient day
- $10 million/year in savings from reducing patient length of stay.
Theator
And another US company called Theator, which has implemented MLOps through ClearML, also showed staggering numbers, once again proving the earlier point.
- $130K-$170K annual savings directly related to MLOps.
Chemical and pharma
When we talk about big things, they can seem infinitely complicated. But sometimes, the small things and dealing with them can be many times more complicated, and that's the case with the chemical and pharmaceutical industry. This is one industry where ML not only allows you to make a lot more money or even solve unsolvable problems but has already managed to change the industry fundamentally.
For so many companies, developing new chemical components and drugs is not a long and costly manual job with a lot of trial and error in the real world. Now it's modeling the behavior of complex molecules and their properties with more advanced machine learning models, for which maximum quality MLOps are vital.
Statistics tell us that 31% of companies implement MLOps for service operations, 31% for product or service development, 27% for marketing and sales, 13% for supply-chain management, 28% for manufacturing, 3% for risk predictions, 6% for increasing human capacity, and 4% for strategy and corporate finance.
Ecolab
For example, US company Ecolab has implemented MLOps using the Iguazio platform to improve its models. The results are telling, especially for such an important industry.
- Decreased model deployment times from 12 months to 30-90 days.
How to implement MLOps
AI and ML is not a magic pill that will solve all problems. Implementing it requires a lot of effort and some investment.
However, avoiding AI and ML altogether can be a big problem for so many companies to ensure their future success and ability to compete in the market. For some industries, it can be a stumbling block that can bring growth to a halt.
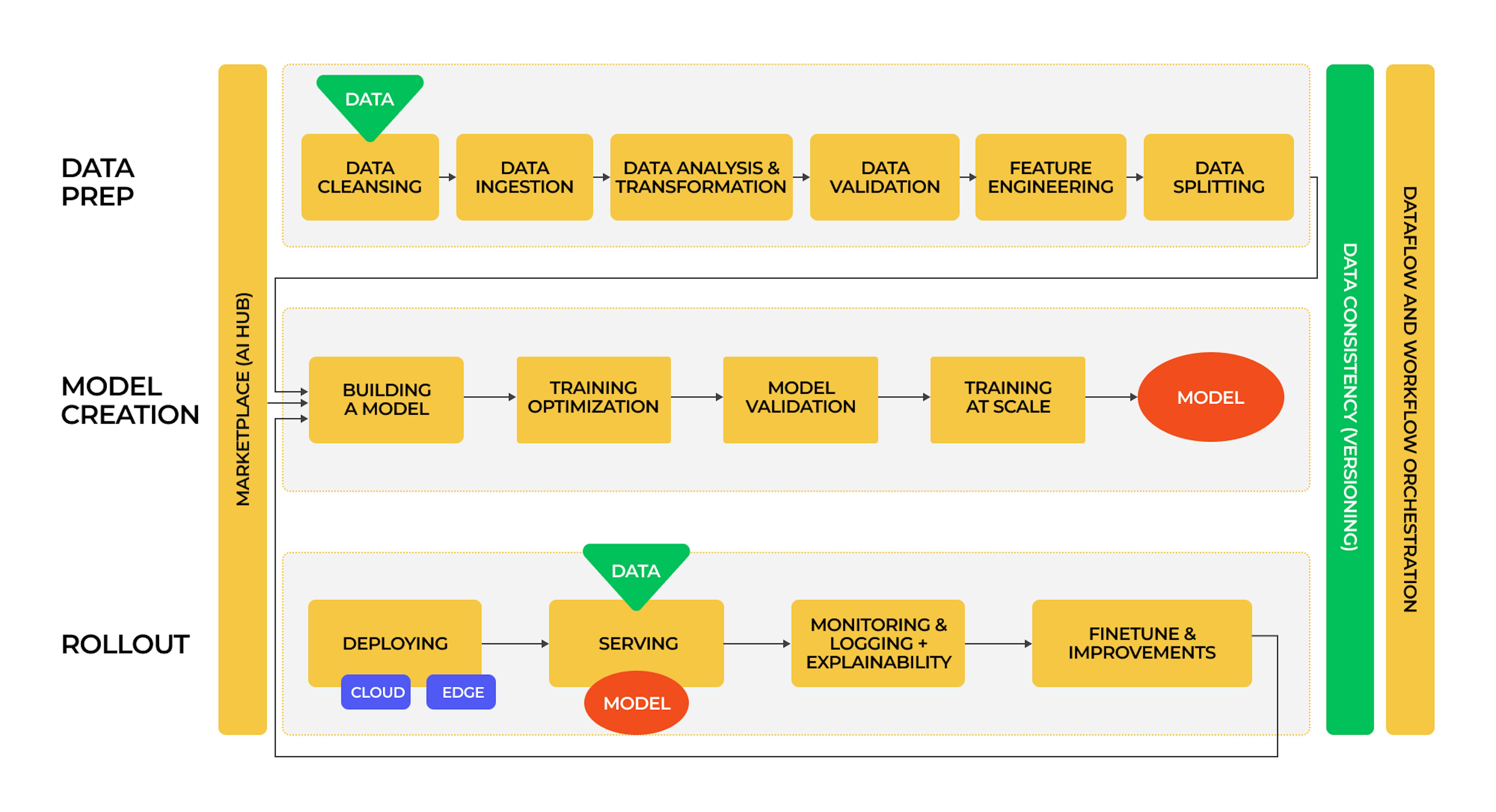
How to implement MLOps
Let's look at the general process of MLOps implementation relevant to most companies and industries based on our experience at Mad Devs.

What are the levels of automation
The level of automation determines the maturity of the machine learning process, and indicates the speed at which new models can be trained based on new data or new implementations. There are three levels of MLOps, ranging from the most to the least common, which involve no automation, to automating both ML and CI/CD pipelines.
MLOps level 0 or manual process
This choice is for companies that are just starting to introduce ML and are not yet sure how much they need it and how to use it. Also, if the company is unsure how often they will update the model.
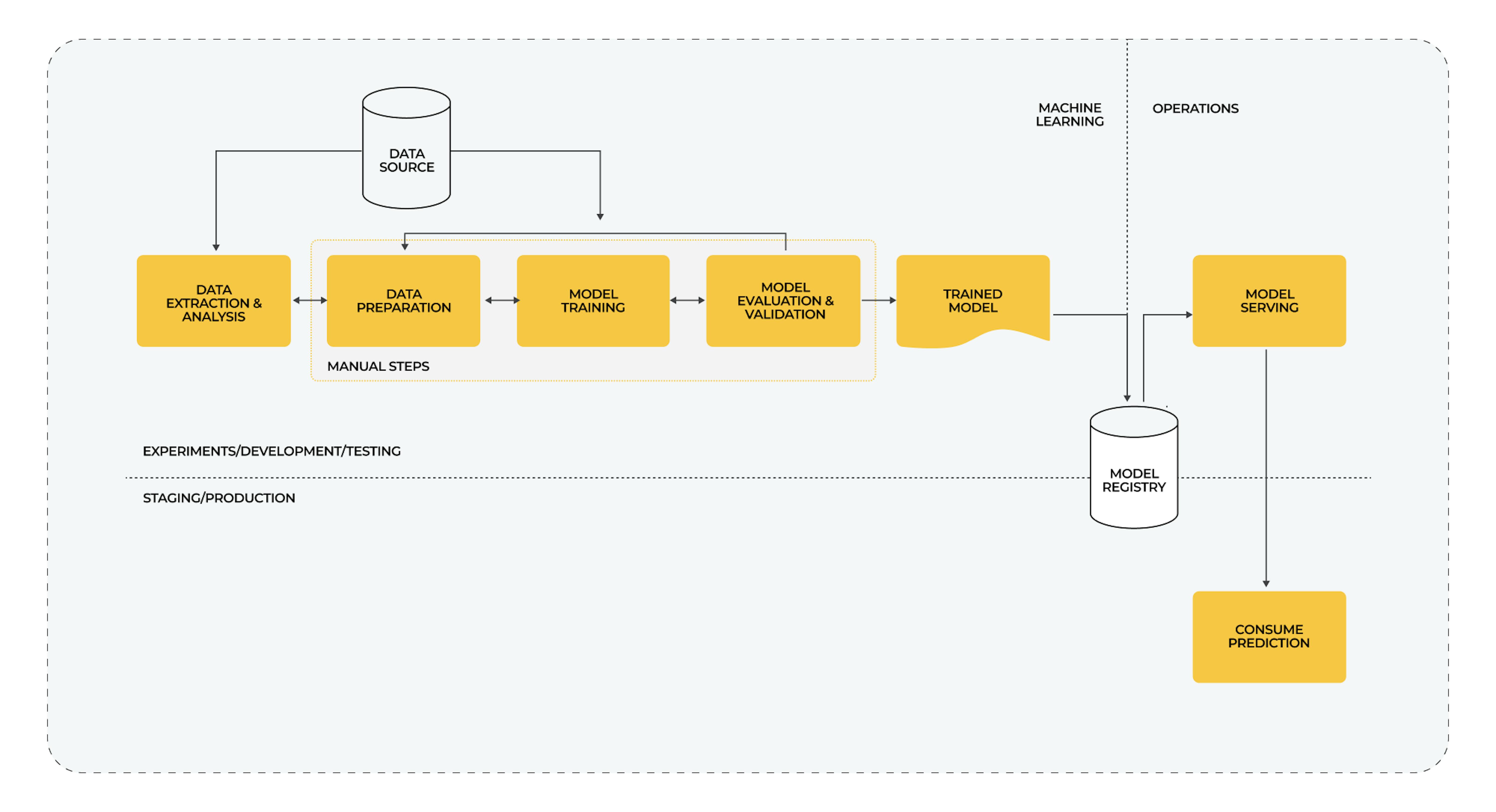
Specifics
- All processes are done manually, from data collection to data processing, model development, and deployment.
- The model training and operations teams don't work as closely. The work is done sequentially on model building, training, and testing, and others on model deployment to their infrastructure via APIs.
- Rare iterations and limited versioning because the model is rarely updated and modified.
- Lack of CI/CD and CT, since the model is infrequently tested, retrained, and redeployed, the automation of such processes is redundant.
- Weak monitoring of the model since it does not require the most comprehensive collection of model metrics for improvement.
Problems
MLOps level 0 is common for businesses new to ML, driven by data scientists. However, real-world deployment often results in model failures due to environmental or data changes. In order to maintain accuracy:
- Monitor model quality. Continuously track model performance to detect issues, and prompt manual retraining.
- Frequent retraining. Keep models up-to-date by training them with the latest data for better adaptation.
- Experimentation. Try new implementations (e.g., feature engineering, architecture) to leverage technological advancements.
MLOps Level 1 or ML pipeline automation
The primary goal is to introduce the CT model by automating the ML pipeline. In this way, predicting model behavior and improving it becomes a challenge.
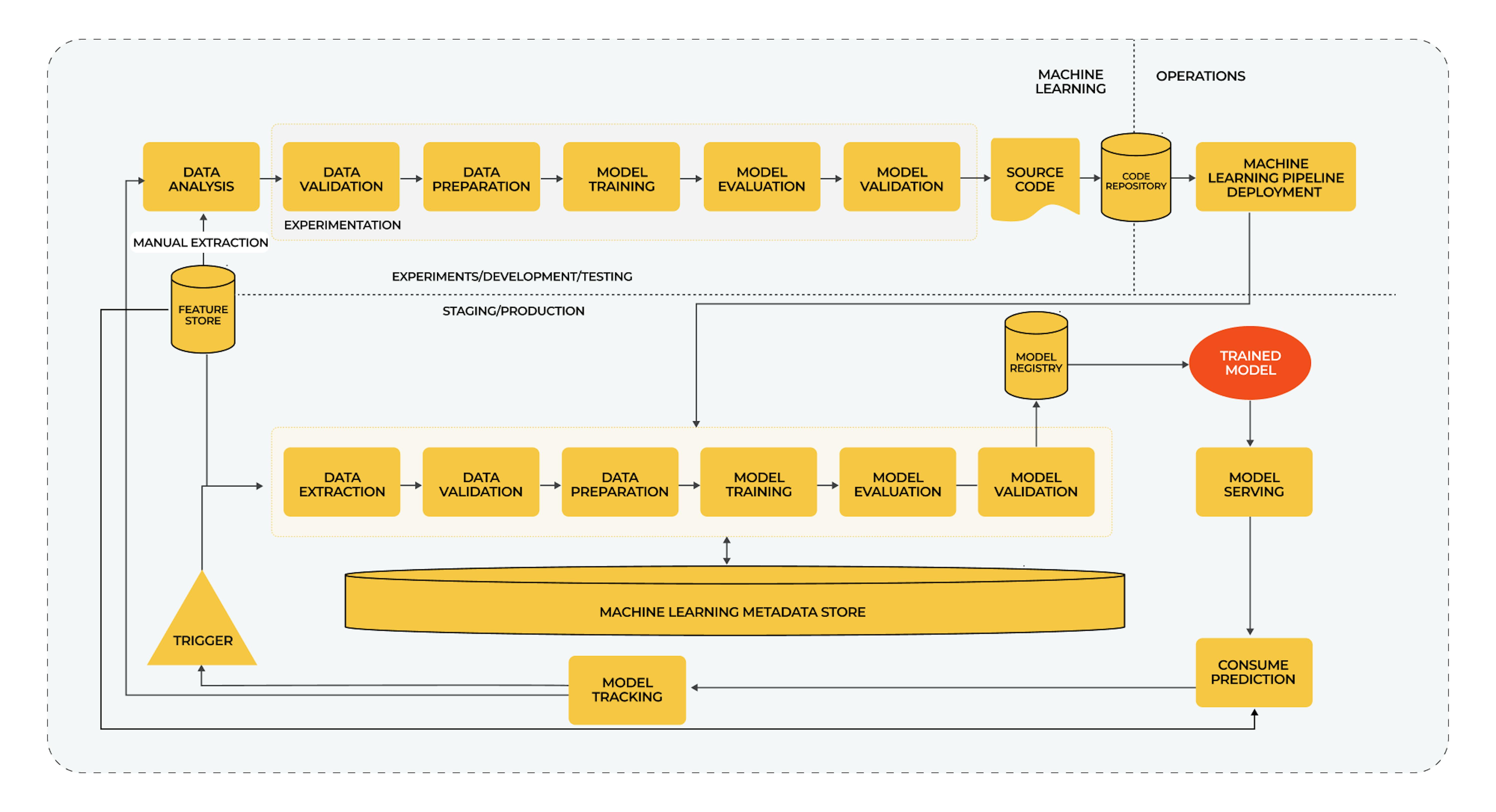
Specifics
- The speed of experiments and training increases because they are automated.
- Thanks to CT, models are trained to obtain and pre-process new data in production.
- Modular components and pipelines are suitable for reuse and reconfiguration.
- Continuous model delivery allows you to deliver models that are always tested and trained on fresh data to the service.
- You deploy not just the model itself in a working environment, but the entire training pipeline that will serve to run and train the model.
- Data validation is automatically set up with appropriate pipelines.
- The feature repository is implemented as a separate repository that you provide access to for the pipeline.
- Metadata management is also automated to help with data and artifact origin, reproducibility, and comparison.
- Configured machine learning triggers to run automatic learning either all the time, on a schedule, or from new data arrivals or performance degradation.
Problems
- This works effectively when you only have one model pipeline. If you have multiple pipelines and models, you already need a CI/CD to deploy them. So we move on to the next level.
Additional components
- Data and model validation: The pipeline necessitates new, real-time data to generate a fresh model version trained on this data. Consequently, automated data validation and model validation steps become essential components of the production pipeline.
- Feature store: A feature store serves as a centralized repository where you standardize feature definitions, storage, and access for both training and serving purposes.
- Metadata management: Recording information about each ML pipeline execution is crucial for tracking data and artifact lineage, ensuring reproducibility, facilitating comparisons, and aiding in the debugging of errors and anomalies.
- ML pipeline triggers: Automation of ML production pipelines enables model retraining with new data based on specific criteria, such as on-demand, scheduled, availability of new training data, performance degradation, or significant changes in data distribution (evolving data profiles).
Challenges
This configuration is ideal for deploying new models using fresh data rather than introducing new machine-learning concepts. Nevertheless, when experimenting with new ML concepts and swiftly rolling out new ML component implementations, a CI/CD setup becomes essential. If you oversee multiple ML pipelines in production, an automated system for building, testing, and deploying these pipelines is crucial.
MLOps Level 2 or CI/CD pipeline automation
Here, we look at the complete implementation of MLOps in case you have multiple data pipelines and models with entirely different algorithms that are frequently updated and come into production.
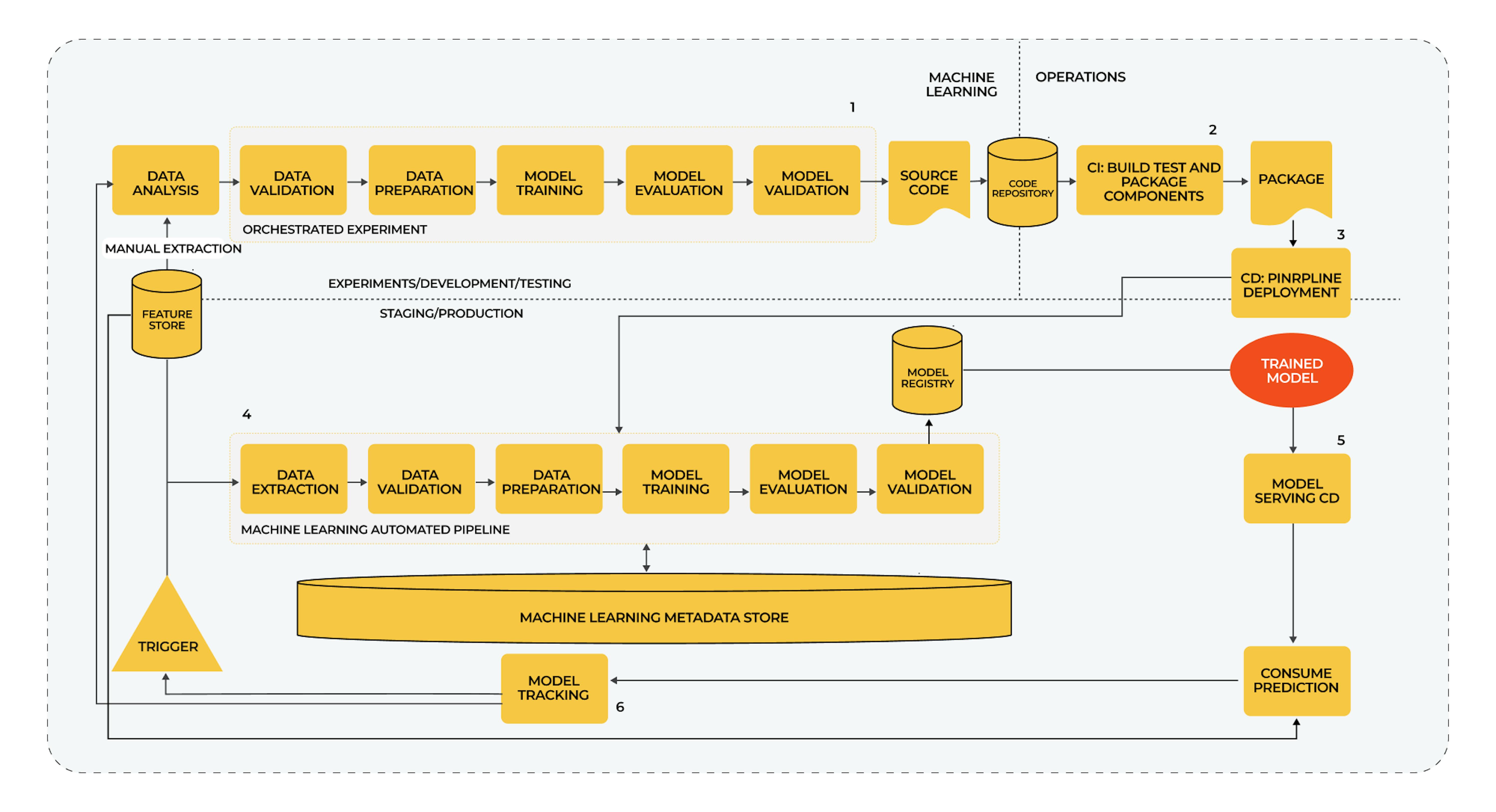
The MLOps configuration consists of these elements:
- Version control
- Testing and building tools
- Deployment services
- Model registry
- Feature repository
- Metadata storage for machine learning
- ML pipeline manager.
Specifics
- Quick and efficient automated development, experimentation with new algorithms, and building new models.
- CI allows you to build pipeline components that can be reused later.
- CD lets you automate the deployment of artifacts and entire pipelines with new model iterations.
- Real-time monitoring allows you to collect various data about the performance of models and run pipelines or experiments in the production environment, depending on the set triggers.
How much does it cost to implement MLOps?
It's worth noting right away here that the numbers can be as individual as possible. It all depends on the industry, company, model requirements, choice of MLOps levels, and infrastructure. For example, the website phdata.io provides a very clear estimation.
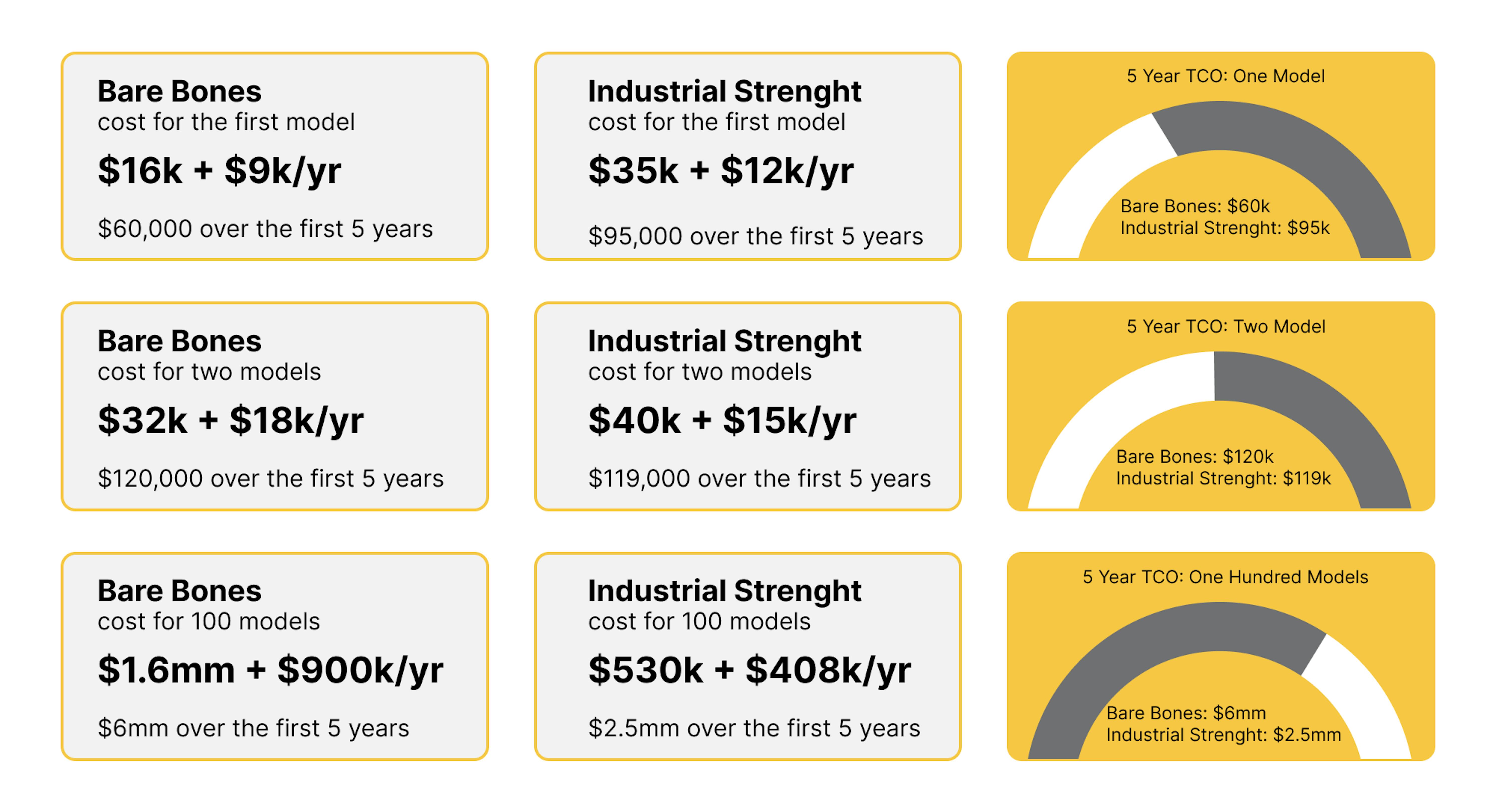
However, choosing a good vendor that will provide the right processes and use the most profitable framework can greatly reduce the cost of the final models and greatly increase the quality and speed of development.
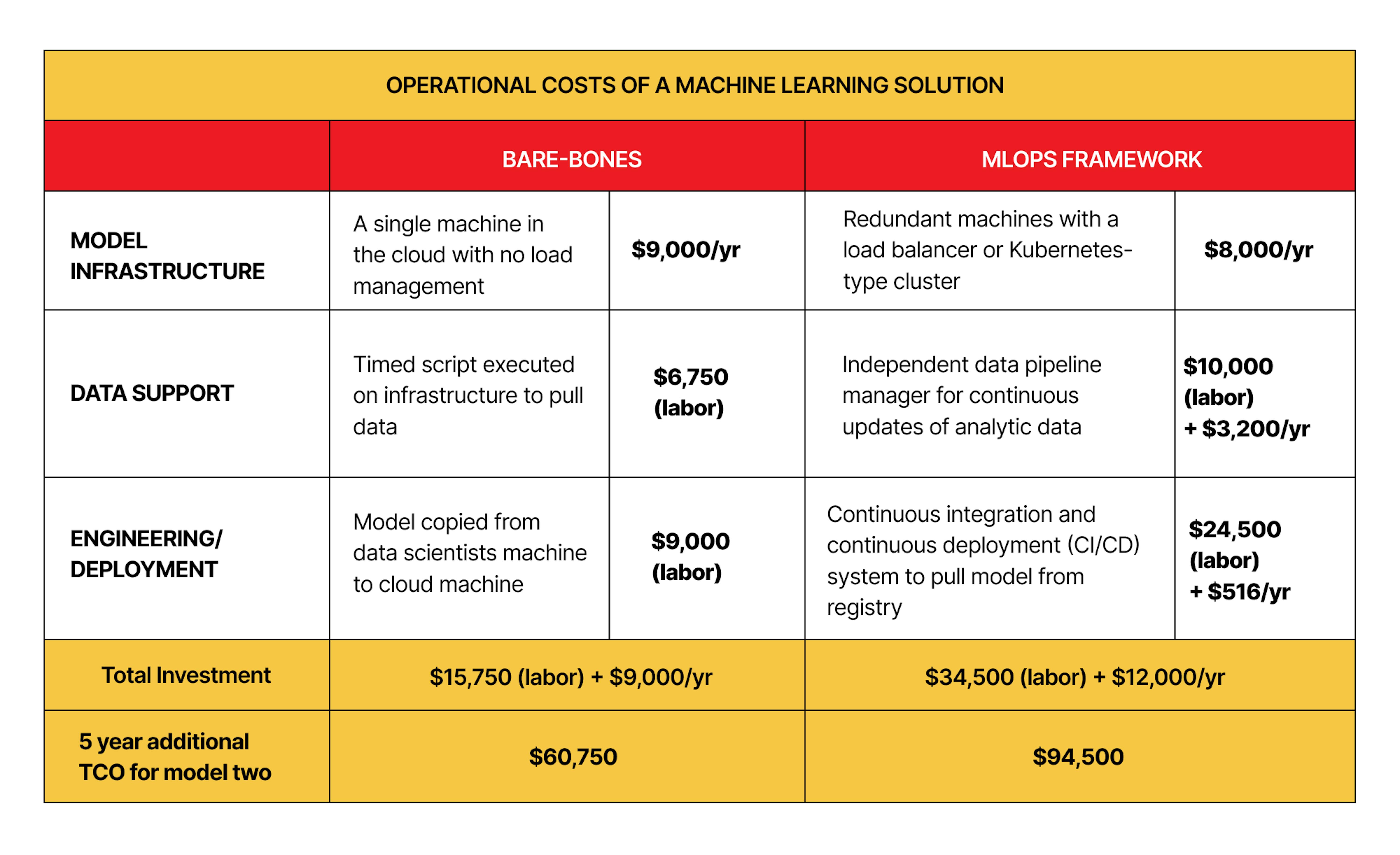
Quality MLOps platform costs serious money, and some might think it's easier to develop your own infrastructure. It may be a good idea if your resource pool is indefinite, as your own infrastructure will allow the creation of specific models generating huge profits.
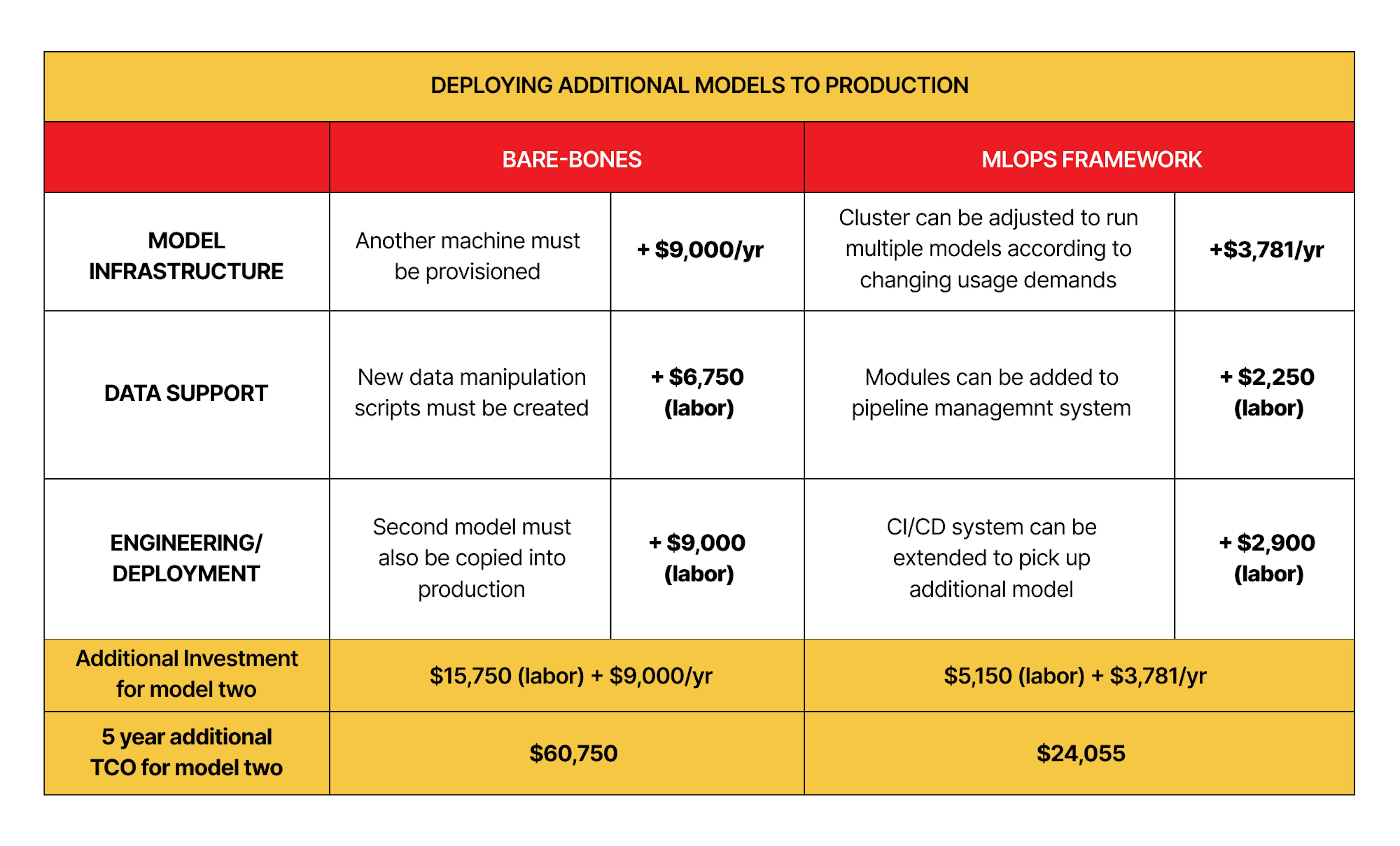
Although building MLOps infrastructure from existing solutions requires a large investment, if you look at most cases, in the long run, it greatly reduces the cost of building new models and maintaining existing ones.
Summary
Machine learning is with us for the long term. It shows excellent results in all domains, receives huge investments, and even prompts the creation of special hardware for specific tasks. All these lead to the fact that artificial intelligence and machine learning will solve even more problems going deeper and deeper, which means its improvement requires the right practices like MLOps.
We hope you've received enough information to think about implementing promising technologies that provide a place in the future market and your company and products. If you still have questions, you can always contact us for a free consultation, and we'll tailor the options to your needs.


FAQ
What is MLOps?
What is AIOps?
What is DevOps?
What are the benefits of implementing MLOps in my organization?
What challenges should I expect when implementing MLOps?
What is the economic impact on the MLOps industry?
How can MLOps contribute to long-term sustainable growth for a business?
What risks are associated with MLOps, and how can they be mitigated?
How can a company get started with implementing MLOps practices?
Latest articles here




