
[Guide: How to Configuring Backups for ClickHouse]
Analyze with AI
Get AI-powered insights from this Mad Devs tech article:
Overview
In a previous article, we explored the installation process of a ClickHouse cluster within a GKE environment using the Altinity ClickHouse Operator. Nevertheless, when deploying this cluster for production use, it is important to create a reliable backup configuration.
This article will guide you through the essential steps and tools necessary for configuring backups effectively.
Altinity ClickHouse operator doesn't provide a backup functionality "out of the box". However, the Altinity team has a project called clickhouse-backup (https://github.com/Altinity/clickhouse-backup) for easy ClickHouse backup and restore with support for many cloud and non-cloud storage types.
It has a rich functionality:
- Easy creation and restoration of backups of all or specific tables.
- Efficient storing of multiple backups on the file system.
- Uploading and downloading with streaming compression.
- Works with AWS, GCS, Azure, Tencent COS, FTP, and SFTP.
- Support for Atomic Database Engine.
- Support for multi-disk installations.
- Support for custom remote storage types via rclone, kopia, restic, rsync, etc.
- Support for incremental backups on remote storage.
Let's dive deeper, but before it we need to install the required tools:
- gcloud
- gsutil
- kubectl
We are going to keep backups using GCS. GCS is a cloud object storage service provided by Google Cloud Platform (GCP). Google Cloud Storage allows users to store and retrieve data in a highly scalable and durable manner. It is commonly used for various purposes, including hosting static websites, storing large datasets, and serving as a backend for applications that require reliable and scalable storage.
We will use GCP Workload Identity to allow pods from a GKE cluster to work with GCS. Google Cloud Platform (GCP) Workload Identity is a feature that enhances the security and manageability of applications and services running on GCP. Workload Identity provides a way to securely delegate permissions to Google Cloud services and resources without the need for long-lived service account credentials.
How to back up a cluster
So, now we are ready to go through the whole process of configuring backups step-by-step.
- Configure gcloud to work with the right project
- Make sure you have access to the GKE cluster with the Clickhouse operator installed
- Make sure Workload Identity Federation for GKE is enabled at the cluster and node pool levels:
- Cluster settings:
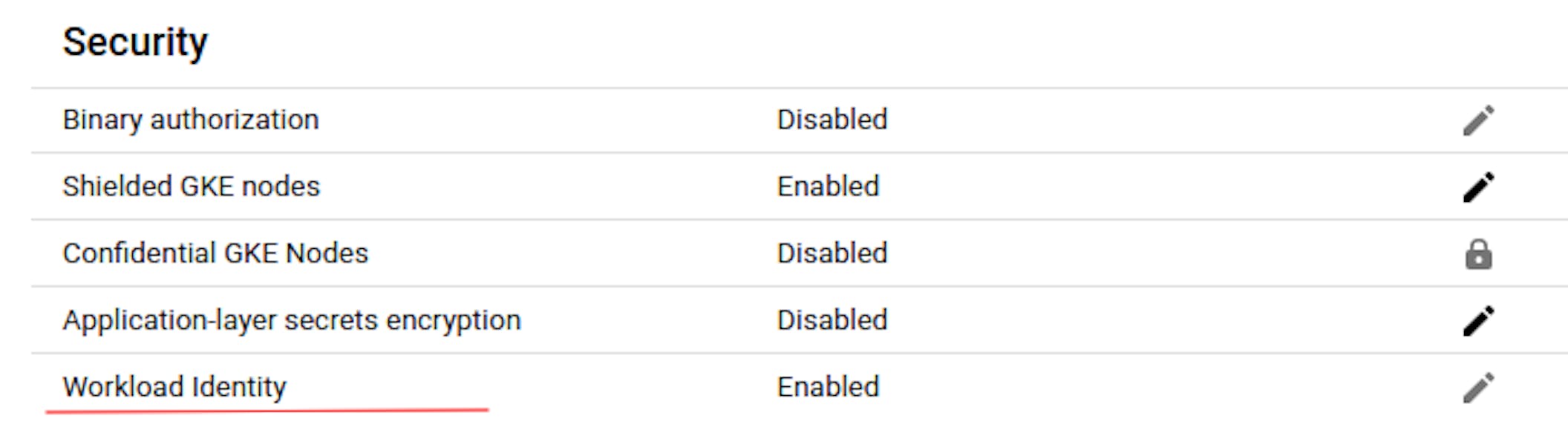
- Nodepool settings:

4. Create a GCS bucket:
gcloud storage buckets create gs://my-bucket-to-keep-clickhouse-backupswhere my-bucket-to-keep-clickhouse-backups is the name you want to give your bucket.
5. Create a Kubernetes service account in the namespace with the ClickHouse operator:
kubectl create serviceaccount clickhouse-gcp --namespace clickhousewhere clickhouse-gcp – the name of your new Kubernetes service account; clickhouse - the name of the Kubernetes namespace for the service account.
6. Create a GCP service account:
gcloud iam service-accounts create clickhouse-clusterwhere clickhouse-cluster – the name of the new IAM service account.
7. Grant permissions for the clickhouse-cluster service account to work with the GCS bucket:
gsutil iam ch serviceAccount:clickhouse-cluster@GCP_PROJECT_ID.gserviceaccount.com:roles/storage.objectViewer gs://my-bucket-to-keep-clickhouse-backups8. Create a binding between the Kubernetes service account and the GCP service account. It allows the Kubernetes service account to act as the IAM service account:
gcloud iam service-accounts add-iam-policy-binding GSA_NAME@GSA_PROJECT.iam.gserviceaccount.com \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE/KSA_NAME]"In our case, it looks like:
gcloud iam service-accounts add-iam-policy-binding clickhouse-cluster@GCP_PROJECT_ID.iam.gserviceaccount.com --role roles/iam.workloadIdentityUser --member "serviceAccount:GCP_PROJECT_ID.svc.id.goog[clickhouse/clickhouse-gcp]"9. Annotate existing Kubernetes service account:
kubectl annotate serviceaccount clickhouse-gcp --namespace clickhouse iam.gke.io/gcp-service-account=clickhouse-cluster@GCP_PROJECT_ID.iam.gserviceaccount.com10. Add the clickhouse-backup as a sidecar container in the podTemplate section:
- name: clickhouse-backup
image: altinity/clickhouse-backup:2.4.25
imagePullPolicy: Always
command:
- bash
- -xc
- "/bin/clickhouse-backup server"
env:
- name: LOG_LEVEL
value: "debug"
- name: ALLOW_EMPTY_BACKUPS
value: "true"
- name: API_LISTEN
value: "0.0.0.0:7171"
- name: BACKUPS_TO_KEEP_REMOTE
value: "14"
- name: REMOTE_STORAGE
value: "gcs"
- name: GCS_BUCKET
value: "my-bucket-to-keep-clickhouse-backups"
- name: GCS_PATH
value: backup/shard-{shard}
- name: CLICKHOUSE_SKIP_TABLES
value: "system.*,INFORMATION_SCHEMA.*,default.*" # All tables except these will be backed up
ports:
- name: backup-rest
containerPort: 7171
volumeMounts:
- mountPath: /var/lib/clickhouse
name: server-storageWhat this configuration does:
- Log level is DEBUG.
- REST API listens on all interfaces.
- Remote storage is GCS.
- A volume with Clickhouse data is shared between containers. Otherwise, clickhouse-backup doesn't back up data and backs up only metadata.
- Backup all tables except these "system.,INFORMATION_SCHEMA.*,default.*".
- Backups are stored for 14 days.
11. Create a Kubernetes cron job to take a backup every day.
- Create a Kubernetes manifest (cronjob.yaml) with the following content:
apiVersion: batch/v1
kind: CronJob
metadata:
name: clickhouse-backup
spec:
# every day at 00:00
schedule: "0 0 * * *"
concurrencyPolicy: "Forbid"
jobTemplate:
spec:
backoffLimit: 1
completions: 1
parallelism: 1
template:
metadata:
labels:
app: clickhouse-backup
spec:
restartPolicy: Never
containers:
- name: run-backup
image: bash
imagePullPolicy: IfNotPresent
env:
# use first replica in each shard, use `kubectl get svc -n clickhouse | grep chi-dc1`
- name: CLICKHOUSE_SERVICES
value: chi-dc1-cluster1-0-0
command:
- bash
- -ec
- CLICKHOUSE_SERVICES=$(echo $CLICKHOUSE_SERVICES | tr "," " ");
BACKUP_DATE=$(date +%Y-%m-%d-%H-%M-%S);
DIFF_FROM[$SERVER]="";
declare -A BACKUP_NAMES;
apk add curl jq;
for SERVER in $CLICKHOUSE_SERVICES; do
BACKUP_NAMES[$SERVER]="full-$BACKUP_DATE";
echo "set backup name on $SERVER = ${BACKUP_NAMES[$SERVER]}";
done;
for SERVER in $CLICKHOUSE_SERVICES; do
echo "create ${BACKUP_NAMES[$SERVER]} on $SERVER";
curl -s "$SERVER:7171/backup/create?rbac=true&name=${SERVER}-${BACKUP_NAMES[$SERVER]}" -X POST;
done;
for SERVER in $CLICKHOUSE_SERVICES; do
while [[ "in progress" == $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"create --rbac ${SERVER}-${BACKUP_NAMES[$SERVER]}\") | .status") ]]; do
echo "still in progress ${BACKUP_NAMES[$SERVER]} on $SERVER";
sleep 1;
done;
if [[ "success" != $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"create --rbac ${SERVER}-${BACKUP_NAMES[$SERVER]}\") | .status") ]]; then
echo "error create --rbac ${BACKUP_NAMES[$SERVER]} on $SERVER";
curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"create --rbac ${SERVER}-${BACKUP_NAMES[$SERVER]}\") | .error";
exit 1;
fi;
done;
for SERVER in $CLICKHOUSE_SERVICES; do
echo "upload ${DIFF_FROM[$SERVER]} ${BACKUP_NAMES[$SERVER]} on $SERVER";
curl -s "$SERVER:7171/backup/upload/${SERVER}-${BACKUP_NAMES[$SERVER]}?${DIFF_FROM[$SERVER]}" -X POST;
done;
if [[ ${DIFF_FROM[$SERVER]} == "" ]]; then
UPLOAD_COMMAND="upload ${SERVER}-${BACKUP_NAMES[$SERVER]}";
else
UPLOAD_COMMAND="upload ${DIFF_FROM[$SERVER]} ${SERVER}-${BACKUP_NAMES[$SERVER]}";
fi;
for SERVER in $CLICKHOUSE_SERVICES; do
while [[ "in progress" == $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"${UPLOAD_COMMAND}\") | .status") ]]; do
echo "upload still in progress ${BACKUP_NAMES[$SERVER]} on $SERVER";
sleep 5;
done;
if [[ "success" != $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"${UPLOAD_COMMAND}\") | .status") ]]; then
echo "error ${BACKUP_NAMES[$SERVER]} on $SERVER";
curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"${UPLOAD_COMMAND}\") | .error";
exit 1;
fi;
curl -s "$SERVER:7171/backup/delete/local/${SERVER}-${BACKUP_NAMES[$SERVER]}" -X POST | jq .;
done;
echo "BACKUP CREATED"- Create a Kubernetes cronjob:
kubectl apply -f cronjob.yaml -n clickhouseThat's it. Now the backup job will run every day, but the setup is not complete until you test the restore path and confirm that the data can actually be recovered.
Can your backups be trusted in a real recovery?
A backup you have never restored is a guess. Ask Mad Devs to review your ClickHouse backup and recovery plan before an outage tests it.
Review my recovery planHow to restore a cluster
Let's consider the recovery process, assuming that we've lost the entire cluster.
These are the steps to restore it:
1. Get a list of backups and copy the part of a path after shard-0:
gsutil ls gs://clickhouse-backups-dev/backup/shard-02. Create a manifest (job.yaml) with the following content to deploy a Kubernetes Job:
apiVersion: batch/v1
kind: Job
metadata:
name: clickhouse-restore
spec:
backoffLimit: 1
completions: 1
parallelism: 1
template:
metadata:
labels:
app: clickhouse-restore
spec:
restartPolicy: Never
containers:
- name: run-restore
image: bash
imagePullPolicy: IfNotPresent
env:
- name: BACKUP_NAME
value: BACKUP_NAME # Set backup_name that we need to restore
# use all replicas in each shard to restore schema
- name: CLICKHOUSE_SCHEMA_RESTORE_SERVICES
value: chi-dc1-cluster1-0-0,chi-dc1-cluster1-0-1
# use only first replica in each shard to restore data
- name: CLICKHOUSE_DATA_RESTORE_SERVICES
value: chi-dc1-cluster1-0-0
command:
- bash
- -ec
- |
declare -A BACKUP_NAMES;
CLICKHOUSE_SCHEMA_RESTORE_SERVICES=$(echo $CLICKHOUSE_SCHEMA_RESTORE_SERVICES | tr "," " ");
CLICKHOUSE_DATA_RESTORE_SERVICES=$(echo $CLICKHOUSE_DATA_RESTORE_SERVICES | tr "," " ");
#Install extra components
apk add curl jq;
for SERVER in $CLICKHOUSE_SCHEMA_RESTORE_SERVICES; do
BACKUP_NAMES[$SERVER]="${BACKUP_NAME}";
curl -s "$SERVER:7171/backup/download/${BACKUP_NAMES[$SERVER]}?schema" -X POST | jq .;
done;
for SERVER in $CLICKHOUSE_SCHEMA_RESTORE_SERVICES; do
while [[ "in progress" == $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"download --schema ${BACKUP_NAMES[$SERVER]}\") | .status") ]]; do
echo "Download is still in progress ${BACKUP_NAMES[$SERVER]} on $SERVER";
sleep 1;
done;
if [[ "success" != $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"download --schema ${BACKUP_NAMES[$SERVER]}\") | .status") ]]; then
echo "error download --schema ${BACKUP_NAMES[$SERVER]} on $SERVER";
curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"download --schema ${BACKUP_NAMES[$SERVER]}\") | .error";
exit 1;
fi;
done;
for SERVER in $CLICKHOUSE_SCHEMA_RESTORE_SERVICES; do
curl -s "$SERVER:7171/backup/restore/${BACKUP_NAMES[$SERVER]}?schema&rm&rbac" -X POST | jq .;
done;
for SERVER in $CLICKHOUSE_SCHEMA_RESTORE_SERVICES; do
while [[ "in progress" == $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"restore --schema --rm --rbac ${BACKUP_NAMES[$SERVER]}\") | .status") ]]; do
echo "Restore is still in progress ${BACKUP_NAMES[$SERVER]} on $SERVER";
sleep 1;
done;
if [[ "success" != $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"restore --schema --rm --rbac ${BACKUP_NAMES[$SERVER]}\") | .status") ]]; then
echo "error restore --schema --rm --rbac ${BACKUP_NAMES[$SERVER]} on $SERVER";
curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"restore --schema --rm --rbac ${BACKUP_NAMES[$SERVER]}\") | .error";
exit 1;
fi;
curl -s "$SERVER:7171/backup/delete/local/${BACKUP_NAMES[$SERVER]}" -X POST | jq .;
done;
for SERVER in $CLICKHOUSE_DATA_RESTORE_SERVICES; do
BACKUP_NAMES[$SERVER]="${BACKUP_NAME}";
curl -s "$SERVER:7171/backup/download/${BACKUP_NAMES[$SERVER]}" -X POST | jq .;
done;
for SERVER in $CLICKHOUSE_DATA_RESTORE_SERVICES; do
while [[ "in progress" == $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"download ${BACKUP_NAMES[$SERVER]}\") | .status") ]]; do
echo "Download is still in progress ${BACKUP_NAMES[$SERVER]} on $SERVER";
sleep 1;
done;
if [[ "success" != $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"download ${BACKUP_NAMES[$SERVER]}\") | .status") ]]; then
echo "error download ${BACKUP_NAMES[$SERVER]} on $SERVER";
curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"download ${BACKUP_NAMES[$SERVER]}\") | .error";
exit 1;
fi;
done;
for SERVER in $CLICKHOUSE_DATA_RESTORE_SERVICES; do
curl -s "$SERVER:7171/backup/restore/${BACKUP_NAMES[$SERVER]}?data" -X POST | jq .;
done;
for SERVER in $CLICKHOUSE_DATA_RESTORE_SERVICES; do
while [[ "in progress" == $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"restore --data ${BACKUP_NAMES[$SERVER]}\") | .status") ]]; do
echo "Restore is still in progress ${BACKUP_NAMES[$SERVER]} on $SERVER";
sleep 1;
done;
if [[ "success" != $(curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"restore --data ${BACKUP_NAMES[$SERVER]}\") | .status") ]]; then
echo "error restore --data ${BACKUP_NAMES[$SERVER]} on $SERVER";
curl -s "$SERVER:7171/backup/actions" | jq -r ". | select(.command == \"restore --data ${BACKUP_NAMES[$SERVER]}\") | .error";
exit 1;
fi;
curl -s "$SERVER:7171/backup/delete/local/${BACKUP_NAMES[$SERVER]}" -X POST | jq .;
done;
echo "RESTORE FINISHED"- Please review and set the correct values for the BACKUP_NAME, CLICKHOUSE_SCHEMA_RESTORE_SERVICES, CLICKHOUSE_DATA_RESTORE_SERVICES environment variables.
3. Delete a clickhouseInstallation and a clickhouse-keeper statefulset:
kubectl delete clickhouseInstallation dc1 -n clickhouse
kubectl delete statefulset clickhouse-keeper -n clickhouse
kubectl delete pvc -l app=clickhouse-keeper -n clickhouse4. Deploy a clickhouseInstallation resource (custom resource you used to deploy the ClickHouse cluster into Kubernetes).
5. Apply the job.yaml manifest to start the restoring process.
kubectl apply -f job.yaml -n clickhouse6. Wait for the ClickHouse cluster's pods to be up and running.
7. If you had manually created ClickHouse users, then restart (delete) ClickHouse pods one by one to run a process of restoring Users/Permissions.
Conclusion
In summary, understanding how to back up and restore your ClickHouse cluster is crucial for protecting your data and ensuring your system can recover from any disasters. With the user-friendly ClickHouse-backup tool, we've covered a step-by-step guide on effectively securing your cluster's information. By choosing Google Cloud Storage (GCS) as a reliable storage solution, you not only boost the safety of your backups but also make sure you can easily access important data when necessary.