
No Bad Questions About Cloud Computing
Definition of Serverless computing
What is serverless computing?
Serverless computing is a cloud-based service model where backend resources are provided on-demand, enabling developers to deploy code without managing the underlying infrastructure. Companies using serverless providers only pay for the actual computing resources they consume, eliminating the need to reserve and maintain fixed amounts of bandwidth or server capacity.
Despite the name, "serverless" computing still relies on physical servers; however, these servers are managed entirely by the cloud provider, allowing developers to focus exclusively on their applications.
Serverless computing is like ordering food from a restaurant instead of cooking at home. The name "serverless" is a bit confusing because servers still exist. You just don’t have to think about them, like how you don’t worry about the restaurant’s kitchen when ordering food.
How does serverless computing work?
Applications typically comprise two main components: the frontend and the backend. Traditional architectures require developers to manage physical servers or cloud resources. Serverless architectures shift this responsibility to cloud providers, allowing developers to focus solely on deploying backend code.
Serverless uses an event-driven model, where small, independent services interact through events, improving scalability and modularity.
Here is an example describing how an event-driven serverless microservice diagram typically looks:
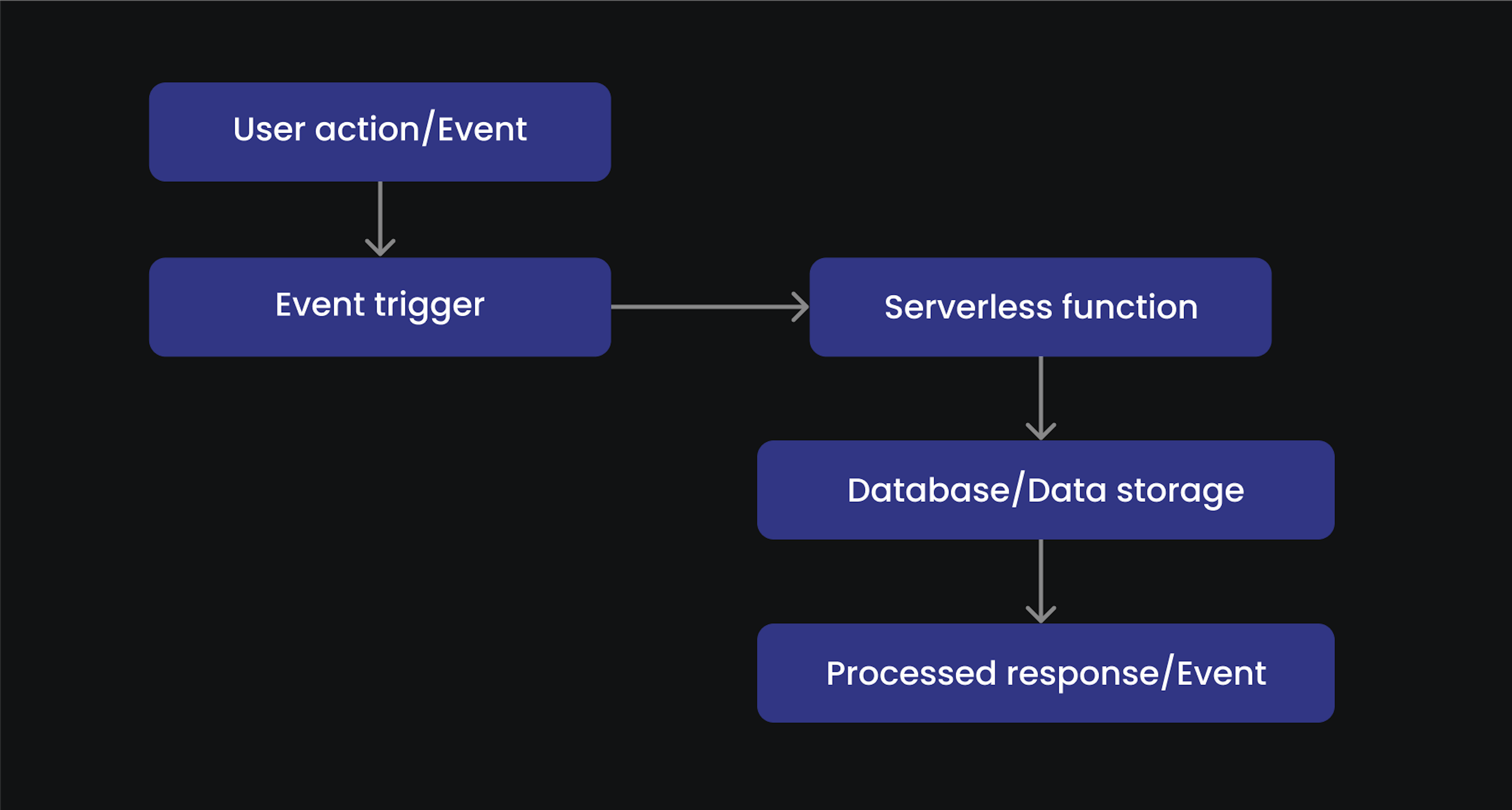
Why is serverless computing important?
Serverless computing reduces operational overhead, enabling faster development and innovation. Let’s elaborate on each of the benefits:
- Cost efficiency: You pay only for the actual compute time your code uses—no charges for idle server time or over-provisioned resources.
- Effortless scalability: Serverless platforms automatically scale based on incoming traffic without manual configuration.
- Simplified development: Functions as a Service (FaaS) enables developers to break applications into small, manageable pieces, simplifying code and maintenance.
- Faster Time to Market: Developers can roll out new features and bug fixes faster without complex deployment pipelines, accelerating product development.
This model is especially beneficial for startups, lean teams, or rapidly evolving projects that need flexibility, speed, and scalability without investing heavily in infrastructure management.
What are use cases of serverless computing?
Thanks to its scalability, cost-efficiency, and rapid deployment, serverless computing is particularly effective in scenarios involving microservices, mobile backends, and real-time data or event stream processing. Below are examples where serverless excels:
SERVERLESS AND MICROSERVICES
One of the most popular serverless use cases is supporting microservices architectures. Microservices are small, independently deployable components that perform specific tasks and communicate through APIs. While they can also be implemented using containers or Platform as a Service (PaaS) solutions, serverless offers unmatched advantages: lightweight functions, automatic scaling, rapid provisioning, and zero charges when idle. These features align perfectly with the microservices model, accelerating development and reducing infrastructure overhead.
API BACKENDS
Serverless functions can easily be exposed as HTTP endpoints, making them ideal for building backend APIs. These functions, often called web actions, can be composed into comprehensive APIs using an API gateway that provides security features, OAuth3 support, rate limiting, and custom domains. This model simplifies the creation of secure, scalable web services without the need for managing backend servers.
📖 Discover how leading tech giants like Google, Instagram, Amazon, and Netflix transformed their development strategies by putting APIs at the center of their architecture, enabling unprecedented scalability and flexibility.
OPEN LIBERTY INSTANTON FOR FAST STARTUP
Open Liberty InstantOn, leveraging CRIU (Checkpoint/Restore In Userspace), allows Java applications to achieve near-instant startup—essential for serverless environments. It works by taking a snapshot of a running Java application during the build process, which can then be restored in production in a matter of milliseconds. Because the restored app behaves identically to the original, this solution enables enterprises to bring serverless capabilities to both new and legacy Java-based workloads without sacrificing performance.
DATA PROCESSING WORKLOADS
Serverless is highly effective for processing both structured and unstructured data. It's commonly used in tasks such as data enrichment, transformation, validation, and cleansing. Developers also use serverless platforms for processing PDFs, normalizing audio, editing images (like sharpening, resizing, or OCR), and transcoding video. These tasks benefit from the ability to run in parallel, scale dynamically, and eliminate costs when not in use.
MASSIVELY PARALLEL COMPUTATION
Tasks that can be divided into many independent parts, known as "embarrassingly parallel" workloads, are particularly well-suited to serverless environments. Examples include cloud-based data searches, MapReduce operations, web scraping, Monte Carlo simulations, business automation processes, hyperparameter tuning, and genome sequencing. In each case, serverless offers high concurrency and efficient resource usage.
STREAM PROCESSING WORKLOADS
Combining serverless with managed services like Apache Kafka and cloud storage forms a strong foundation for real-time stream processing. This architecture is ideal for ingesting, validating, cleansing, and transforming data from IoT devices, app logs, financial feeds, and other sources. Serverless functions can process this data in real time, enabling responsive and scalable pipelines without provisioning long-running infrastructure.
AI AND MACHINE LEARNING
Serverless computing supports AI and ML use cases by providing the elastic compute power needed for tasks such as model training, inference, and data preprocessing. Teams benefit from the ability to scale workloads automatically while only paying for resources used, allowing for faster innovation and efficient experimentation in AI-driven systems.
HYBRID CLOUD FLEXIBILITY
Serverless is also a key enabler of hybrid cloud strategies. It can manage workloads across public clouds, private infrastructure, edge locations, and on-prem environments. This flexibility allows organizations to scale as needed, adapt to shifting demand, and meet compliance or latency requirements while maintaining a unified application model.
COMMON SERVERLESS APPLICATIONS
Serverless is now widely used across industries. Common applications include customer relationship management (CRM) systems, high-performance computing (HPC), big data analytics, business process automation, video streaming, online gaming, telemedicine, e-commerce platforms, and intelligent chatbots. Its event-driven nature, cost-effectiveness, and ease of integration make serverless an essential part of modern software development.
Key Takeaways
- Serverless computing lets developers run code without managing servers. You only pay for what you use, and cloud providers handle all infrastructure.
- It works using an event-driven model, ideal for breaking apps into small, independent functions. This approach reduces costs, scales automatically, and speeds up development. Serverless is widely used in microservices, APIs, real-time data processing, machine learning, and hybrid cloud setups.
- It's especially valuable for startups and fast-moving teams that need agility without complex infrastructure overhead.
