
No Bad Questions About ML
Definition of Gradient descent
What is gradient descent?
Gradient descent is a method used to help machine learning models learn and improve. It works by finding the best settings (called parameters) that reduce the difference between what the model guesses and what the correct answer actually is.
To do this, the model examines the training data, makes a prediction, evaluates the accuracy of its prediction using a cost function, and then adjusts its settings slightly to improve next time. This process repeats over and over until the errors are as small as possible.
Once the model learns well enough, it can make accurate predictions, and that's what makes it useful for things like AI and computer science tasks.
Imagine it like you're making coffee but can't taste it. A friend gives feedback each time. You adjust the ingredients based on what they say, making small changes each time. Eventually, the coffee tastes perfect. That's how gradient descent works: small, guided updates until the result is as good as possible.
Why is gradient descent important?
Gradient descent is used to find the best parameters for a machine learning model by reducing the difference between the model's predictions and the actual answers.
Here's why it matters:
- Finds the best model: Machine learning models have parameters that need to be adjusted to make good predictions. Gradient descent helps find the best combination of these parameters.
- Reduces errors: It minimizes the difference between what the model predicts and the actual results, which is known as the loss or cost. Gradient descent gradually lowers this loss over time.
- Works with complex models: For models like deep neural networks with millions of parameters, gradient descent is one of the few practical ways to optimize performance.
- Scalable and efficient: It can handle large datasets and still work effectively by using variations like stochastic gradient descent (SGD), which updates the model using just a small batch of data at a time.
In short, without gradient descent, most machine learning models wouldn't know how to improve and would stay inaccurate.
How does gradient descent work?
Gradient descent iteratively reduces the value of the cost function, leading to optimized parameters and improved model performance. Here is a simple step-by-step process:
- Initialize parameters
Start with random values for the function's parameters. - Compute the gradient
At the current parameter values, calculate how much the cost function changes. This tells us the direction in which the function increases. The gradient shows how each parameter affects the function's output. - Update the parameters
Move each parameter slightly in the direction that lowers the cost. To do this, subtract the gradient from the current values. The size of the step is controlled by a number called the learning rate. A smaller learning rate means smaller steps. - Repeat the process
Perform these calculations again with the new parameters. Keep repeating this process until the function value stops decreasing or becomes very small. This means the algorithm has likely reached the minimum.
The algorithm stops when it reaches the lowest point of the function, giving optimized parameters that minimize the cost and improve model accuracy.
What are the different types of gradient descent?
The main types of gradient descent differ in how much data they use to update model parameters during training. The 3 most common types are Batch, Stochastic, and Mini-Batch Gradient Descent.
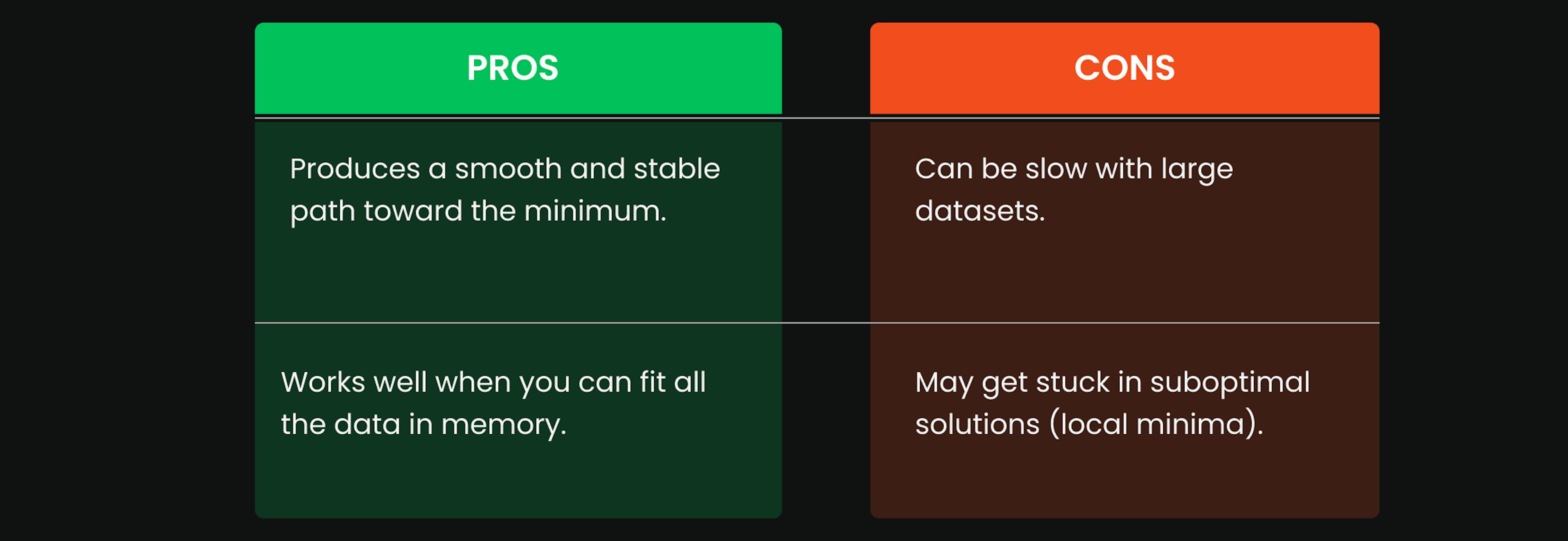
1. Batch Gradient Descent
- This method uses the entire training dataset to calculate the gradient before updating the model parameters.
- It performs one update per training cycle, also called an epoch.
2. Stochastic Gradient Descent (SGD)
- Instead of using all data, SGD updates the model for each individual training example.
- Each step is based on a single data point.

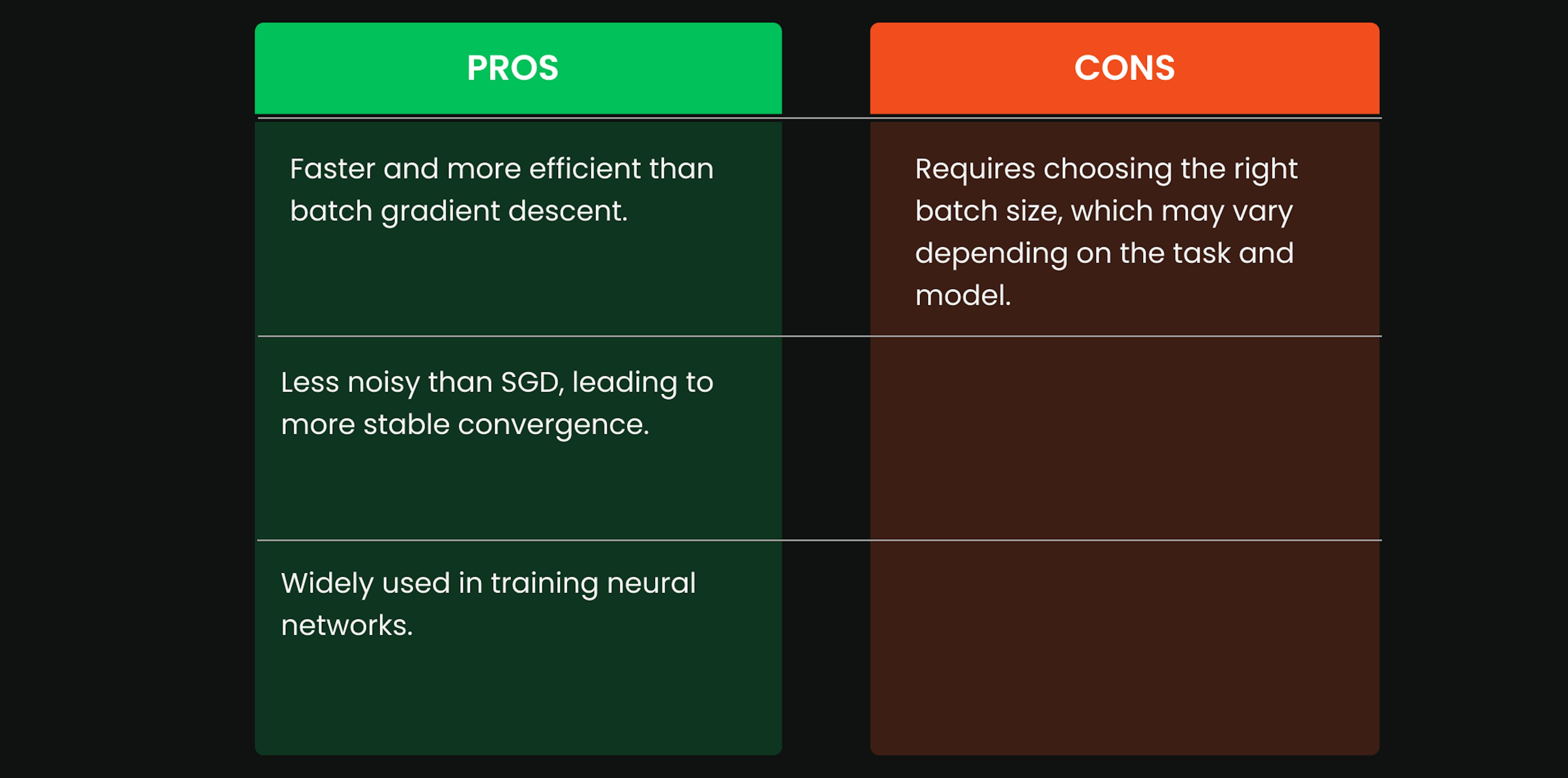
3. Mini-Batch Gradient Descent
- Combines the advantages of both batch and stochastic methods.
- The dataset is split into small batches (32, 64, 128 examples).
- The model updates after each batch.
Key Takeaways
- Gradient descent is a core method in machine learning that helps models learn by adjusting their parameters to reduce prediction errors.
- It works by calculating how much the model is off, then gradually updating the parameters to improve performance. This process repeats until the model reaches its best possible state.
- The algorithm is important because it allows models to improve over time, even when dealing with complex tasks and large datasets. Without gradient descent or similar techniques, machine learning models wouldn’t know how to adjust themselves and would remain inaccurate.
- Gradient descent follows a simple loop: start with random parameters, compute how much they affect the error, adjust them to reduce that error, and repeat until there’s little to no improvement left.
- There are 3 main types of gradient descent, depending on how much data is used during each update. Batch Gradient Descent uses the whole dataset and is stable but slower. Stochastic Gradient Descent updates after each data point and can be faster but more chaotic. Mini-Batch Gradient Descent strikes a balance by updating in small chunks of data, making it the most widely used in practice.
